こんにちは。メルカリの画像検索チームでTech Leadをしています葛岡です。
今回は、メルカリのMLシステムの中で一、二を争う複雑なシステムである画像検索の基盤を再設計し、経済的にも技術的にもみんなが幸せになったお話をしたいと思います。
画像検索ってなぁに?
その名の通り、画像をベースに視覚的に似ている商品を検索する機能です。この機能は2年ほど前にリリースされていて、すでにiOSバージョンのメルカリではご利用いただけます。
当時のシステムはブログ記事になっているので、ご確認ください。
再設計?なにそれ?おいしいの?
さてこの機能を支えるシステムですが、当時開発されて以来、大きな再設計などは特になく、つい最近まで運用されていて、画像検索やその他のメルカリサービスでも内部的に呼ばれていて、プラットフォーム的な立ち位置を担っていました。
画像検索は定期的に新しい画像インデックスを構築するのですが、当時のシステムではインデックスの構築からサービング(画像インデックスの提供)まで全てLykeionという内製MLプラットフォーム上で動いていました。
この内製ツールはk8sのCRD (Custom Resource Definition)を使って動いており、CRD Controllerを実装して学習やサービングのパイプラインを管理していたのですが、k8sの中でも上級者向けなCRDを管理するのは運用コストが高かかったり、できれば自分達では管理したくないという気持ちがありました。
そんななか、Modelの学習だとKubeflowやSage Maker、サービング側ならCloud FunctionsなどサーバーレスアーキテクチャとSpinnakerなどのCD (Continous Delivery)ツールを使って置き換えれるというざっくりした構成図がメンバーの中で浮かんでおり、再設計により運用コストが大幅に下げられると判断したため、中長期的にシステムの再設計の決断に至りました。
画像検索システムは学習側とサービング側に分かれているため、今回の再設計では大きくフェーズを2つに分けました。理由としては、すでに独立機能としてプロダクションリリースしている機能であり、プラットフォームとして内部サービスにAPIを提供しているサービスであるため、一度に大きい変更をリリースしダウンタイムが発生したり、SLAを破るなどワーストケースを避けるためでした。
再設計フェーズ1
サービングのこれまでと課題
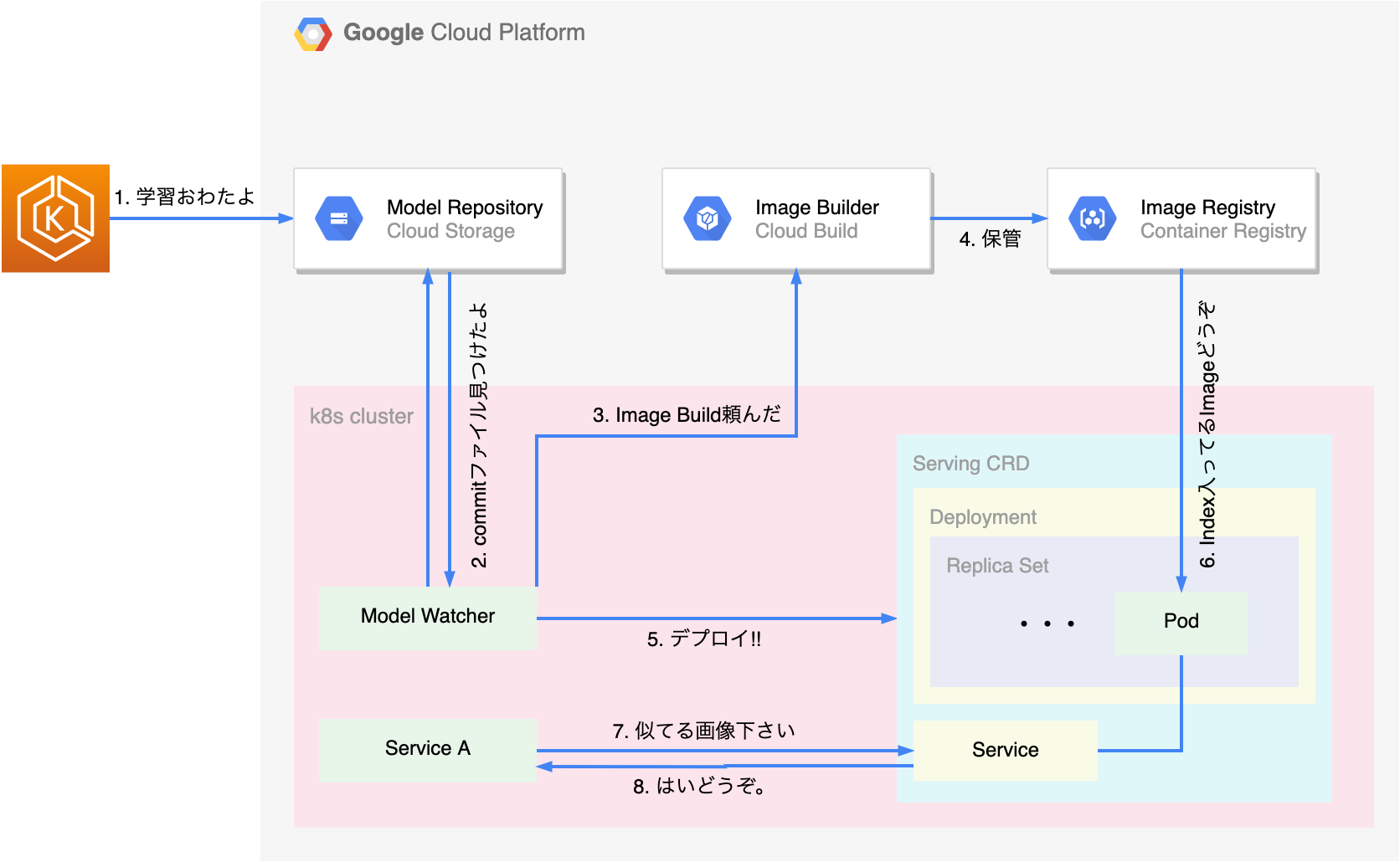
まず前提として、学習側とサービング側の連携は、Model Repositoryと呼ばれる、学習済みのモデルや、生成されたインデックスを格納するGCS Bucketによって行われていました。
画像検索システムでは学習環境にEKSを、サービング環境にGKEを使用していて、サービング側の主な構成はGCP上で以下のようになっていました。

(図1)フェーズ1再設計前
再設計以前は、EKS上で学習が終わったことを知らせるためのCommitファイルが、Model Repositoryにアップロードされます(図中1)。GKEクラスタ内には、Model RepositoryをLong Pollingで監視している、Model Watcherが存在し、Commitファイルを検出し(図中2)、Cloud Buildでサービングに必要なDocker ImageをBuildし(図中3)GCRに格納します(図中4)。最後にServing CRDをクラスタにデプロイすることによって(図中5)、画像インデックスを含んだImageがPodにPullされ(図中6)、k8sのServiceを通してPodの類似画像検索APIを呼び出す(図中7、8)構成となっていました。
これまでの設計の課題としては、Model Repositoryを監視しているModel Watcherや、Serving CRDを管理するServing Controllerの運用と管理にかかるコスト、それに加え監視のPullモデルによる無駄なPodや、毎時Build・Push大量の画像インデックスを含むDocker Imageを保管するGCRなど、クラウド利用コストなどがありました。
プラットフォームの恩恵を十分に受けるシステム構成
はじめにModel Repositoryの監視部分ですが、Cloud Functionsなどを使ってPullモデルからPushモデルに簡単に移行できるというのは頭の片隅にありました。Pushモデルによって、独自のLong Pollingロジックを書かなくてよいだけでなく、コスト面でも常時監視しなくてもよいので、サーバーレスアーキテクチャの魅力であるPay-As-You-Goの恩恵を受けることができます。これらの利点を考えると、置き換える以外の選択肢はありません。
続いて、k8sクラスター内にリソースデプロイするステップですが、メルカリではCDツールであるSpinnakerを採用しています。Spinnakerはリソースのデプロイだけでなく、自動カナリアリリースの機能やUIを通してリソースの状態がリアルタイムに把握できたり、便利な機能をたくさん兼ね備えています。(Spinnakerの詳細はこちらのブログを参考にしてください)
メルカリではマイクロサービスプラットフォームチームがSpinnakerを管理しているため、マイクロサービスの開発者は基本的に運用コストゼロでSpinnakerを使えます。そのメリットを生かしてServing Controllerの置き換えはCloud Functions + Spinnakerの技術選定でいくことにしました。

(図2)フェーズ1再設計後
図1と図2を比較するとServing Controllerとしてk8sクラスタ内にデプロイされていたModel Watcherがなくなっていることがわかります。Cloud Functionsを使うことによって、指定のBucketにObjectがアップロードされた時に自動で呼び出されるため(Pushモデル)、常時監視しなくてよくなります。
続いてSpinnakerのWebhookをCloud Functionsが呼び出すことによって、DeploymentとServiceをk8sクラスタにデプロイするのですが、再設計前と比較してServing CRDを使用せず、純粋なk8sリソースのみ(図2青枠内)をデプロイしています。もともとServing CRDは複数のk8sリソース(図1青枠内)から構成されていたので置き換えは簡単で、これによりServing CRDが必要なくなり、Serving Controllerの管理も不要になりました。
さらに設計前では新しいインデックスが生成されるたびにImageを生成していたいのですが、再設計後にはBaseのImageを用意して、PodのinitiContainerを活用することによって必要なモデルの成果物をPullする仕様になっています(図中4)。これによりGCRの容量を大幅に削減することができました。
再設計フェーズ2
学習基盤のこれまでと課題
続いてモデルの学習部分ですが、こちらもk8sのCRDとControllerを使って、Training Controllerを実装し、DAGの生成・管理そしてModel RepositoryへのアップロードすべてをEKS上で内製ツールが担当していました。当時の構成は以下のようになっていました。

(図3)フェーズ2再設計前
学習基盤は初めに、EKS内にデプロイされているCronJobリソースが、毎時Training CRDを生成するためのコードを実行し(図中1)、定義されたDAGと共にTraining CRDをApplyします。ここでApplyされたTraining CRDをもとに、Training Controllerはk8sのJobのステータス管理と、k8sのJobをDAGの定義通りに作成していきます(図中2ー5)。最後にTraining Controllerが管理するJob全てが成功した後に、学習の終了をサービング側に伝えるCommitファイルをModel Repositoryにアップロードします(図中6)。
やっていることはシンプルに見えるのですが、k8sのCRD controllerは管理と運用のコストが高く、問題が起こるたびにGoで書かれているレポジトリをデバッギングして修正、デプロイしなければならなかったため、気づけばAIエンジニアの時間が管理・運用に時間の大半を割かれているという運用コスト上の課題がありました。
OSSを活用した低運用コストなシステム構成
当時と比較しOSSのMLツールであるKubeflowやAWSが提供するSageMakerなどプロダクションで利用できる環境が整い、内製する以外の選択肢も増えました。運用コストも考えると社内で管理されているKubeflowが基盤のGKE上に構築されているMLプラットフォームに移行した方が中長期的に良いと考え、学習側でも再設計をするという決断に至りました。
Kubeflowは、Kubernetes上で動くOSSのML基盤で、学習パイプラインの構築・管理からモデルや実験の管理まで幅広い機能をサポートしています(ベータですがServingもサポートしているらしいです)。またGCPやTensorflowなどGoogle製のツールと相性がよく、近年プロダクション環境として使われるようにもなっています。
もともとTraining ControllerのDAGはContainer化されたスクリプトと記述された依存関係をもとにDAGを構築・管理するというのが役目だったため、移行は比較的容易で、すでに存在していたyamlで記述されているDAGをKubeflow SDKを使って再定義し、新しいPipelineをKubeflow上でデプロイするのみがフェーズ2での移行作業でした。

(図4)フェーズ2再設計後
再設計後では内製ツールの代わりにKubeflowを採用したため、k8sのCronJobの代わりに、KubeflowのRecurring Jobを使い定期的に、画像インデックス生成をパイプラインで実行しています。これまではk8sのJobとJobが管理するPodの中でデータの前処理やインデックス生成をしていましたが、これらが全てKubeflowのComponentという概念に置き換えられ、DAGやステータスの管理も全てKubeflowが行ってくれます。
これにより自分達でTraining Controllerを管理する必要がなくるだけでなく、これまでは学習はEKS、サービングはGKEというマルチクラスター構成だったのが、学習側もGKEに移行でき、クラスター管理のコストが大幅に下がりました。
結果どう?
さて学習側とサービング側の設計をプラットフォームの恩恵を受けながら極力楽する方向に舵を切った画像検索ですが、この再設計により、経済的にも技術的にも改善され、みんなが幸せになりました。
フェーズ1:SLOの改善とクラウドコストの削減
フェーズ1により、既存CRD ControllerをCloud FunctionsとSpinnakerでのCDパイプラインによって置き換えることによって、運用コストを大幅に下げました。システムも安定稼働していて、定期的になっていたアラートも最近ではゼロに近く、継続的な改善によりSLOは0.5 ptほど上がり、約99.9%を維持しています。
更に毎時Build・Pushしていた画像インデックスを含むImageを、Base Image + initContainerの組み合わせに置き換えることで、毎時Build・Pushする必要がなくなり、無駄なGCRな容量とCloud Buildにかかる計算コストをゼロにしました。
また微々たるものではありますが、サーバーレスアーキテクチャを採用することによって、これまで監視の為に常時走っていたk8sのリソースが必要なくなり、Pay-As-You-Goモデルの課金体制になったことで、監視部分に割いていて計算コストを、約10分の1以下におさえることもできました。理にかなっていますね。
フェーズ2:運用コストの削減と新しい技術の採用
そしてフェーズ2により、独自の学習基盤から、プラットフォームチームが管理するKubeflowの学習基盤に移行することによって、内製ツールの管理コストがなくなるだけでなく、新しいOSSの技術を取り入れ更にこれまでなかった機能(モデルの可視化など)も使えるようになりました。
おまけにEKS + GKEで動いて画像検索ですが、GKEに統一され複数クラスタ管理する必要もなくなりました。言うまでもなく、大幅な運用コストの削減です。めでたしめでたし。
まとめ
今回の再設計は特段難しいことはしておらず、目の前の問題に対して適切なツール選択し、適切に使っただけです。その結果、運用コストの大幅削減、お財布に優しいシステム設計、新しい技術の採用など多くの利点がありました。
運用コストが下がった分、AIエンジニアは本業であるモデルの生成などにフォーカスできますし、新しい技術を採用した結果、これまでの半分以下の運用コストであたらしいこともできるようになりました。
今回の再設計で一番感じたのが、ものは使い方次第でいくらでも楽ができるということです。システムの設計に関しては正解はないので、動いていれば問題ないと思うかもしれませんが、わざわざ簡単な問題を難しく解く必要はありません。
時代はクラウドの利点をより活用するCloudNativeに向かっており、今後はよりアプリケーションレベルの実装がビジネスを左右する時代が来ると思っています。その中業務の大半をインフラ構築やレガシーシステムのデバッギングなどに時間を使っているなら、ふと立ち止まり「その問題難しく解いていない?」と問いかけてみてください。
もっと簡単な答えが目の前にあるかもしれません。




