こんにちは! Mercari Advent Calendar 2020 の6日目は、メルカリ Notification チーム/Software Engineer の tarotaro0 がお送りします。
Notification チームは、メルカリのアプリ内通知やメール、プッシュ通知などを扱うマイクロサービスの開発・運用を担当しているチームです。いわゆるバックエンドアプリケーションの開発と、そのアプリケーション・サーバー及びデータベースなど関連サービスの運用を行っています。
Notification チームでは、データベースに Google Cloud Spanner (以下 Spanner) を採用しています。メルカリにおける通知は社内でも特に大きいトラフィック・データ量を扱う領域で、秒間数千にも及ぶリクエストに対応出来るスケーラビリティや高可用性などが求められます。Spanner は上記観点や、既存のアーキテクチャとの親和性から採用され、約2年ほど運用を続けて来ました。
今回の記事では、この2年間 Spanner を運用する中でかなり苦労した、本番稼働中の Spanner における Secondary Indexes (以下インデックス)追加に関連する話をしたいと思います。
目次
- インデックス追加の背景
- 57時間かけてインデックスを追加した話
- 知見を活かして同様のオペレーションを問題なく実行した話
1. インデックス追加の背景
Notification チームの扱う Spanner には、お客さま毎のアプリ内通知を保存するテーブル(以下 Notification テーブル)が存在し、お客さまごとの通知一覧や通知総数の取得のために使われています。

↑アプリのお知らせ一覧画面
当初設計した段階では、通知は必ず特定のお客さまに紐付いており、上記のユースケースでは必ずお客さまの ID (以下UserID)で条件を絞ることを想定していたため、Notification テーブルではUserIDとUUID(uuid v4) などを組み合わせた複合 Primary Key を設定していました。
しかし開発が進み、他サービスからの要件が増えていく中で、Primary Key と既存のインデックスだけではどうしても良いパフォーマンスが見込めないという壁にぶつかりました。これはサービス開発において一般的に生じうる問題かと思いますが、弊チームにおいては本番稼働中の Spanner におけるインデックスの追加は初めてで、知見のない状態でのチャレンジでした。
昨年に公開された Google Cloud Japan Customer Engineer のアンチパターンから学ぶ!Cloud Spanner あるあるクイズでは、ゲーム用データベースとして Spanner を使用する際のホットスポット対策として、サービス開始時にはインデックスを張らないというものを紹介しています。
ゲームプレイヤーのデータを保持するテーブルに、プレイヤーのレベルに対するインデックスを張りたいというケースで、サービス稼働直後はレベルが1に偏ってしまう事によってホットスポットが発生してしまうという問題があります。その問題に対して、ある程度サービスが稼働してレベルが分散した後にインデックスを張る、という対策が具体的に紹介されていました。
このように本番稼働中に Spanner のインデックスを追加することはテクニックとして紹介されているものの、実際に運用中の Spanner、そしてメルカリ程度の規模で、ダウンタイム無しにインデックスを追加したケースはまれではないかと思います。
次章では、実際に約57時間かけて Notification テーブルにインデックスを追加した話を、その次の章では初回実行時に得た知見を活かして、安定して数時間でインデックスを追加した話をします。
2. 57時間かけてインデックスを追加した話
Notification テーブルでは上述したようなUserIdやUUIDなどを複合させた Primary Key がありましたが、新しい要件ではUUIDのみでの読み取りが必要になりました。
Spanner では Primary Key の中でも先頭に設定したカラム(今回はUserId)に対してデータを分割したスプリットを作成するため、UUIDのみでクエリしても効率の良い探索が行われません。そのためUUIDのみでの検索に特化したインデックスを作成することに決めました。
本番環境でインデックス作成を開始
オペレーションに問題が無いかを確認するため、テスト用や開発環境用のデータベースに対して同様のインデックスを作成しましたが、それぞれ数百万・数千万件の行数に対して数分で問題なくインデックスの作成が完了しました。
そして勢いに乗って本番環境にてインデックスを作成し始めた際の Spanner のCPU使用率グラフがこちらになります。
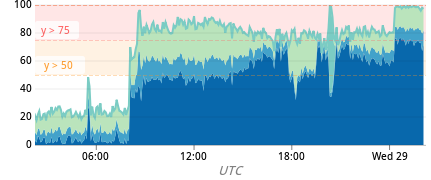
最も著しい伸びを見せている濃い青色のメトリクスが優先度の低いシステムタスクで、インデックス作成のために用いられるCPU使用率を表しますが、作成開始した時刻が一見して明らかなほど使用率が増加しています。
Spanner CPU使用率の公式ドキュメントから引用すると、
Cloud Spanner では、必要に応じて優先度の低いタスクがすべて停止され、優先度の高いタスクが、最大で 100% の利用可能なCPUリソースを活用できます。
と記載されており、優先度の低いシステムタスクが増えても、通常のアプリケーションから用いる優先度の高いユーザータスクは優先されて処理されるとされています。実際にインデックス作成が開始された後に優先度の高いタスクは顕著に伸びておらず、Spanner 側で推奨されているアラートにも引っかからなかったため、特別な対応をせずに静観していました。

↑Spannerで推奨されているアラート
しかし作成開始から30数時間を経過した頃、CPUの合計使用率が100%付近に張り付いていることに気付きます。

この状態が継続した場合、平滑化された24時間のCPU使用率が90%を越えてしまい、推奨されているアラートの値を超えてしまうため、何かしらの対策が必要であると判断しました。
調査と対策の検討
時は少し遡り、本番環境でインデックスを作成するのにかかる時間を試算していました。
テスト用・開発環境・本番環境それぞれのデータベースの情報は以下の通りです。(数値はおおよその値)
| テスト | 開発環境 | 本番環境 | |
|---|---|---|---|
| レコード数 | 100万 | 1000万 | X0億 |
| 平均CPU使用率 | <5% | <5% | 20~30% |
| ノード数 | 1 | 1 | 7 |
| 作成時間 | 数分 | 数分 | ??? |
ご覧のように、開発環境と本番環境でレコード数が異なるだけでなく、Spanner のノード数や一日の平均CPU使用率も異なってきます。このため作成時間の見積もりが立てづらいのですが、およそレコード数に対して線形時間かかると仮定して、約60時間ほどかかるという予想を立てました。
また別の切り口として、実行後に作成され増加した Spanner のストレージ容量からの見積もりも試みました。Spanner のインデックスは、全レコードに対して、インデックス対象のカラムに Primary Key のカラムを加えた新たなテーブルとして作成されます。そのためインデックス作成によって増大するストレージ容量は以下のように試算出来ます。
レコード数 * (インデックスカラムサイズ + Primary Key カラムサイズ)この増加する見込みのストレージ容量と、単位時間辺りに実際に増加したストレージ容量を比べることで、約58時間と予想され、概ねレコード数から試算した時間と近い時間になりました。
以上の試算より、少なくとも24時間はCPUの合計使用率が100%の状態を継続すると予想されたため、具体的な対策を検討し始めました。
対策とその結果
結論として対策はシンプルで、ノード数を増加させることでした💸。既に本番環境で稼働しているアプリケーションを止めるわけにはいかず、インデックスも作成中で変更するわけにはいかないため、我々に出来ることはノード数を増やすことか、インデックス作成を中止することか、落ち着くのを祈ることだけでした。
しかしノード数を増やすことは一種の賭けです。ノード数を増加させることで Spanner はデータ(スプリット)を各ノードに割り当て直す必要が生じ、負荷も同時に増してしまうのではないかという懸念があったため、CPU使用率が100%付近に張り付いた状態でのノード追加は諸刃の剣である可能性も否めませんでした。
最終的にはノードの追加を決断し、徐々にノードを追加してノード数が7→13に増えた後のCPU使用率がこちらになります。
CPU使用率に20%ほど余裕が生まれ、最終的にインデックス作成のオペレーション開始から57時間経過後、アプリケーションにも大きな問題無く完了しました。
得られた知見
Spanner高負荷時の対応
最も大きい知見は、Spanner 高負荷時の対応です。前述したようにノード数増加によって追加の負荷をかけてしまうという懸念がありましたが、結果として大きな追加の負荷も無く全体の負荷を下げることが出来ました。
このように水平方向のスケールを動的に、ダウンタイムなしに行えるのは、Spanner を使う上で大きなメリットだと改めて感じました。
インデックス追加時間の見積もり
公式ドキュメントのセカンダリ インデックスの追加でも書かれていますが、作成に必要な時間は
- データセットのサイズ
- インスタンスのノード数
- インスタンスの負荷
に依存します。今回は本番環境以外の環境との比較や、実際に追加し始めてからのストレージ容量を指標に試算して、おおよそ近い時間を見積もることが出来ました。今後インデックス追加を行う際には過去のデータを元に実行時間を見積もり、最適なノード数を算出して実行する、という知見が得られました。
Spanner CPUの負荷
インデックス追加開始時はCPUの合計使用率が80~90%で推移し、途中から100%付近に張り付いていました。
Cloud Spanner では、必要に応じて優先度の低いタスクがすべて停止され、優先度の高いタスクが、最大で 100% の利用可能な CPU リソースを活用できます。
と上述していましたが、通知サービスという特性上ある時刻からお客さまへ大量の通知が配信されるというユースケースが存在し、瞬間的に優先度の高いユーザータスクの負荷が増加します。CPUに余裕がない場合にこのようなスパイクが発生すると、(許容できる範囲内でしたが)書き込みの遅延や読み取りのエラーが見られました。
今回の様にシステムタスクが膨大になる場合は、Spanner 側でCPUの合計使用率が100%に張り付くようにシステムタスクが実行されることもあるので、100%に近付く前に早期検知・対処が必要だと学びました。
そもそもインデックス作成をしない
インデックスを作成する上で出来るだけ Spanner への負荷を減らすための知見について書きましたが、どれだけ工夫をこらしても今回のようなケースでは Spanner に負荷をかけずにインデックスを作成することは出来ません。
本番稼働中の Spanner に負荷をかけないように、インデックスの作成を回避するのは現実的な選択肢だと思います。例えば、テーブル設計時点からユースケースを適切に考慮して Primary Key やインデックスを作成しておく、アプリケーションのロジックでカバーする、そもそもの要件が本当に必要かどうかを見直す、などを考える必要性があると強く感じました。
その上でどうしてもインデックスを作成しなくてはならない・作成した方が良いケースも存在するので、その時に今回の知見を活かせたらと思います。
3. 知見を活かして同様のオペレーションを問題なく実行した話
Notification テーブルへのインデックス追加から数ヶ月後、他の本番稼働中のテーブルに対してもインデックスを追加する要件が出てきました。
テーブルAは平常時15ノードで運用されていました。テーブルAにインデックスを追加する際には、前回の知見を活かして実行時間を見積もり、事前にノード数を10程度増やせば問題なく数時間で終わるだろうと見積もりを立て、通知の大量配信や1日のピークタイムなどを避けてオペレーションを開始しました。
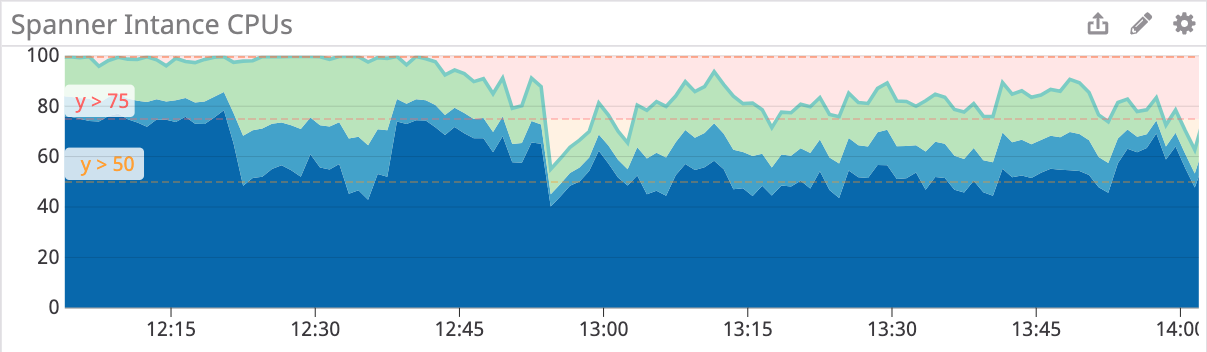
テーブルAに対してインデックスを追加した際のCPU使用率がこちらのグラフです。(グラフのビューは変わっていますが、前回と同様のメトリクスです)

インデックスの追加は9:24に開始し、10:19に終了しました。前回は100%に到達したCPU使用率も、最大で60%程度に落ち着いており、約1時間で完了しました。
インデックスの作成中にサービスのレイテンシやエラーレートなどを確認していましたが、特に気になる点も無く、前回のような緊急対応もせずに平常通りの運用を行うことが出来ました。
後日テーブルBに対しても同様の要領でインデックスを追加しました。Notification テーブル・テーブルA・テーブルBに対してインデックスを追加したオペレーションの結果をまとめると以下になります。
| Notification | Table A | Table B | |
|---|---|---|---|
| レコード数 | X0億 | 10億 | 15億 |
| 平均CPU使用率 | 20~30% | 20~30% | 20~30% |
| ノード数 | 7→13 | 24 | 21 |
| 作成時間 | 約57h | 約1h | 約2h |
事前にレコード数・平常時のCPU使用率から適切なノード数を試算し、ノード数を増加させ、出来るだけサービスの負荷が高くない時間帯に実行する。前回の知見を活かすことで、速やかに問題なくインデックスの追加が出来ました。
ちなみに、Spanner のノード数には上限が割り当てられていて、Google Cloud Console で確認することが出来ます(参考)。割り当て上限を増やす際は Google Cloud Console 上からリクエストして Cloud Spanner チームに対応してもらう必要があるため、ノード数が上限ギリギリの場合は予め割り当てを増やしておくと安心です。
今回の記事が読んで頂いた皆様のお役に立てば幸いです。
メルカリではミッション・バリューに共感できるソフトウェアエンジニアを募集しています。今回のオペレーションのようなチャレンジングな課題に Go Bold に取り組める職場で一緒に働ける仲間をお待ちしております。
明日の Mercari Advent Calendar 2020執筆担当は、 Data Platform Engineer の yu さんです。引き続きお楽しみください。最後までお読み頂きありがとうございました。




