
Mercari Advent Calendar 2020の2日目は、メルカリEdgeAIチーム エンジニアのChica Matsuedaがお送りします。
近年、高性能なサーバーではなくスマートフォンなどのモバイル機器上で機械学習モデルの推論を走らせる(EdgeAI)技術の開発が進んでおり、 TensorFlowLite / MLKit / CoreML / MediaPipe をはじめ様々なモバイル端末向けの推論ライブラリが開発されています。
EdgeAIチームでは、これらの技術を活用してUXの改善を目指し、様々な機能開発に取り組んでいます。
この記事では動画などストリーミングメディアの推論に特化した MediaPipe というGoogle製のOSSの活用事例について、紹介していきます。
MediaPipeとは
MediaPipeはストリーミングメディアに対して推論を実行するパイプラインを構築するためのフレームワークです。
FaceDetection、HandTracking、ObjectTrackingなどのカメラや動画を入力として推論を行うサンプルが豊富に準備されており、簡単に手元で試すことができます。



Mediapipeには前処理、モデルの推論、データ変換、図形描画等のcalculatorが準備されており、それらを組み合わせたパイプラインをグラフとして作成することができます。最近Google Meetsに追加された背景ぼかし機能も、MediaPipeを使って実装されています( Google AI Blog )。
動画を入力とした推論では、前処理・推論・描画までをの処理を毎フレーム繰り返す必要があり、うまく制御できないと入力動画フレームに対して処理結果が遅延してリアルタイム性が損なわれてしまいます。MediaPipeではそれぞれのノード(calculator)の処理をスケジューラが管理し並列実行されるため、そのような事態が起こりづらい設計になっています。
例えば30fpsで動作させたい場合、MediaPipeがないと前処理から描画まで全てを1/30secで実行する必要があります。しかしMediaPipeにスケジューリングされると、最も時間のかかる処理が1/30secで処理できれば、他の処理は並列して計算しておけるので30fps近いパフォーマンスを出すことができるというようなイメージになります。(詳細は Synchronization – mediapipe )

今回はMediaPipeを使って現在開発している機能についてご紹介させていただきます。
リアルタイム売れるかチェック
現在EdgeAIチームでは、こちらのデモ動画のようなカメラをかざして持っているアイテムが売れるかをチェックする機能をiOSにて開発中です。

この機能を開発する上で
- ストリーミングで処理をしたい
- 電池消費を抑えるためのチューニングをしたい
- 自作モデルを利用したい
という要件を満たす必要があります。
これらが実現可能であることからMediaPipeを採用することにしました。
この機能は以下のようなしくみで動いています。

- カメラの入力画像を取得
- 推論を行いたいアイテムが写っている長方形領域を探す
- 2.で検出されたアイテムの領域に画像をトリミングし、
画像を特徴ベクトル化する - 写真から類似商品を検索する弊社のAPIにベクトル情報を送り、類似する商品情報を取得
それらを集計してアイテムに関する情報を推定する - アイテムの位置と推定結果をレンダリングする
このうち、類似商品検索以外のプロセスはすべてモバイル端末上で行われています。
オンデバイスでほとんどの処理を終わらせることには以下のような利点があります
- サーバーとの通信が入らないので、ほぼリアルタイムで物体検出・トラッキングができる
- 画像自体をサーバに送らないので、プライバシー的にも安心
逆に欠点としては、
- 推論モデル自体をアプリケーションに含める必要があり、アプリサイズが増加する
- ある程度のCPU・メモリが必要なので、すべてのデバイスで推論可能なわけではない
という点が挙げられます。
さて、それではこの機能がどのように実現されているのかを見て行きましょう。
リアルタイム売れるかチェックのグラフ紹介
リアルタイム売れるかチェックのグラフは Box Tracking(Object Detection and Tracking)のExample をベースに拡張をしています。
以下はMediaPipeのVisualizerを使ってグラフを可視化したものです。左が元のBox TrackingのExample、右が私達の追加実装を含めたリアルタイム売れるかチェックのグラフになります。
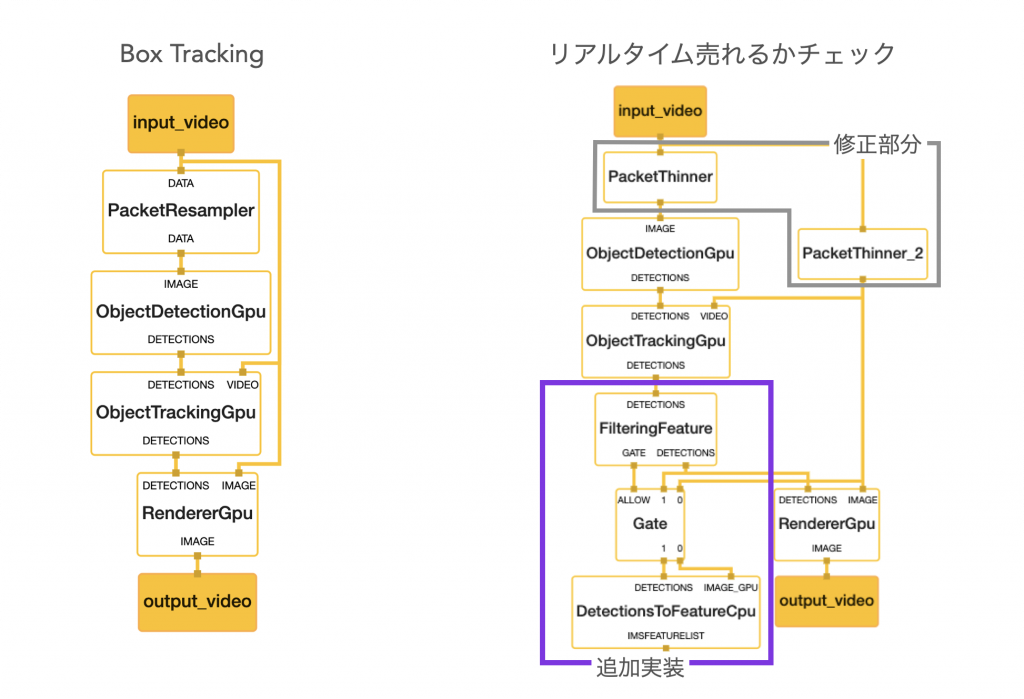
MediaPipeを利用したことのない方には読みづらいと思うので、わかりやすく各ノードのやっていることを書き出してみるとこのような感じになります。

紫の部分が独自でCalculatorを作成した部分です。
物体選別とは、複数の物体が検出された場合に、フォーカスするメインの物体を判別する処理になります。物体が画面の中央に配置されているかや領域の重複などを考慮し、メインの検出物体1つを選んでいます。
特徴量抽出は画像をベクトル情報に落とす処理です。物体検出と似た実装ですが、検出した物体ではなくtensor(ベクトル)を出力するcalculatorは準備されていなかったため作成しました。
MediaPipeでは、 calculator_base.h を継承して実装することでノード(グラフ内の各長方形のこと)として好きな処理をグラフに組み込むことができます。
また、リアルタイム売れるかチェックのグラフの中で、
- 物体検出
- 特徴量抽出
がモデルの推論を走らせる一番重い処理となります。
MediaPipeでは複数のノードの処理が並列に走るため、物体検出はGPUで、特徴量抽出はCPUで計算するよう実装しています。
サービスとして提供するための工夫
上記のグラフを実装してみたところ、
- 計算負荷が高すぎてモバイル端末が熱くなる
- モデルサイズが大きい
という技術的課題にぶつかりました。
これらをどう解決したかを紹介していきます。
計算負荷を減らし、端末が熱くなるのを抑える
MediaPipeのサンプルを実行したことのある方はわかると思いますが、Box Trackingはかなり計算が重いため、数分起動しているとモバイル端末がかなりの熱を持ちます。
社内でユーザテストを実施した中でも「端末が熱い」という意見は多く寄せられました。
そこで、グラフの中からフレームレートを落としても問題のない処理を見つけ出して計算負荷を減らそうと試みました。
物体検出をさぼる
物体検出・追跡はこのグラフ内でも特に重い処理です。
しかし、ここのフレームレートを下手に落とすと、カメラが移動したときに追跡・検出が遅れてリアルタイム性が著しく失われてしまいます。
そこで、私達は物体の追跡は毎フレーム行いつつ、物体検出を数フレームに一度だけ行うようにグラフを変更しました。
物体追跡は検出ほど重い処理ではありませんが、フレームレートを落とすとカメラの動きに追跡が間に合わず、カクカクとした動きに直結します。
一方物体検出は数フレーム遅れても違和感はそれほどありませんでした。
この変更により、なめらかに物体の追跡しつつも、物体検出の回数を削減することに成功しました。前述のMediapipeグラフの「修正部分」のPacketThinnerノードが実際に計算フレームを調整している部分です。
特徴量抽出をさぼる
特徴量抽出も物体検出同様計算の重い処理です。しかし、アイテムの撮影位置が多少変わってもアイテム自体の見かけ(特徴量)はそれほど変わりません。そのため特徴量抽出はアイテムが新たに検出された場合に一度だけ行うようにしました。
また物体が検出されて一番はじめのフレームはカメラが移動していることが多く物体がブレがちなため、物体が検出されてから数フレーム後に特徴量抽出を行う工夫をしています。
これらの計算量を削減する修正を加えた結果、ユーザ体験を悪くするような変更を加えずにデバイスへの負荷以下のように削減することができました。

※iPhone11にて検証
CPU利用率とEnergyImpactが大幅に抑えられているのがわかるかと思います。これにより、この機能を長い時間使用し続けても端末が熱を持つことはなくなりました。
この内容をふまえ、はじめに説明した売れるかチェックのしくみをもう少し詳細に説明すると、以下のような感じになります。

基本的には物体の追跡をして検出範囲の描画を更新しつつ、定期的に新たな物体を検出し、類似商品情報を検索して予測結果を描画しています。
モデルのチューニング
今回利用しているのは
- 物体検出
- 特徴量抽出
の2つのモデルです。
そのうち物体検出モデルは自由につくることができますが、特徴量抽出モデルは類似商品検索APIで利用しているモデルと同一特徴ベクトルを生成する必要があるため、チューニングすることはできません。そのためここでは主に物体検出モデルをチューニングしていきます。
アーキテクチャの選定
今回ベースとしているMediaPipeのBox TrackingのExampleではCOCO Datasetで学習されたSSDLite-mobilenet-v2が利用されています。
リアルタイム売れるかチェックではデータセットを準備し、以下のアーキテクチャでそれぞれ学習し評価を行いました。
| アーキテクチャ | Precision/mAP | Recall/AR@100 | モデルサイズ |
|---|---|---|---|
| SSD-mobilenetv2 | 0.56 | 0.66 | 18MB |
| SSDLite-mobilenetv2 | 0.56 | 0.67 | 12MB |
| SSDLite-mobilenetv3-small | 0.38 | 0.5 | 3.7MB |
| SSDLite-mobiledet | 0.59 | 0.71 | 13.8MB |
評価の結果、精度・モデルサイズの面からBox Trackingでも採用されているSSDLite-mobilenet-v2を利用することにしました。
クラス数の削減によるモデルの軽量化
今回は物体検出モデルでは物体の位置さえ検出できればよいため、クラス分類をする必要がありません。全結合層の重みはモデルサイズに大きな影響があるため、クラス数を1に設定し検証してみたところ、大きな精度低下は見られなかったため、物体があるかないかだけを判定する1クラス分類モデルを採用することにより、モデルサイズの削減に成功しました。
こちらがSSDLite-mobilenet-v2のモデルをクラス数を変えて推論速度とモデルサイズを比較したものになります。
| クラス数 | 500枚の画像の推論にかかった時間 | モデルサイズ |
|---|---|---|
| 600 クラス | 60sec | 49MB |
| 90 クラス | 35sec | 17MB |
| 1 クラス | 32sec | 12MB |
モデルサイズの削減が成功したことに加え、全結合層の計算が軽くなることにより推論速度も向上しています。
重みの量子化によるモデルの軽量化
モデルの軽量化に有効な方法といえば、重みの量子化(Weight Quantization)が挙げられます。MediapipeではTensorFlowLite(以下TFLite)のモデルを利用することができ、v2.3現在TFLiteは以下の量子化をサポートしています。
| Technique | Benefits | Hardware |
|---|---|---|
| Dynamic range quantization 重みをuint8に量子化する |
4x smaller, 2x-3x speedup | CPU |
| Full integer quantization 重みと活性化関数をuint8に量子化する |
4x smaller, 3x+ speedup | CPU, Edge TPU, Microcontrollers |
| Float16 quantization 重みをfloat16に量子化する |
2x smaller, GPU acceleration | CPU, GPU |
TensorFlow – Post-training quantization より
しかし、Dynamic range quantizationやFull integer quantizationする場合2つの注意点があります。
1つ目として、 量子化を意識してモデルのトレーニング (quantization aware training、以降QA)をする必要があります。そうしない場合、精度劣化が大きく利用できなくなる可能性があります。
私達の作った物体検出モデルは、QAした場合とそうでない場合で、uint8に量子化をして推論をすると以下のように精度の差が生まれました。
| 物体検出モデル | mAP |
|---|---|
| QAなし + Dynamic range quantization | 0.365 |
| QAあり + Dynamic range quantization | 0.415 |
2つ目の注意点は、uint8の計算をgpuで計算するのは今現在tfliteが対応していない点です。
これらをふまえて取れる選択肢は以下のどちらかになります。
| 量子化 | 精度 | GPU利用 | 推論の高速化 |
|---|---|---|---|
| uint8 + QA | ○ | × | ○ |
| float16 | ◎ | ○ | × |
重みがfloatの場合、GPU利用時にCPUよりも3倍ほど速度が上がります(iosデバイスの場合)。しかし、Dynamic range quantizationもしくはFull integer quantizationを採用したuint8に量子化されたモデルの場合、推論速度があがるためGPUが利用できなくても同等の速度になる可能性があります。
今回は、MediapipeのDetectionまわりのcalculatorはGPU用のみ準備されていることから、それらを利用したかったためFloat16 quantizationを採用しました。
また、特徴量抽出モデルでもFloat16 quantizationを試してみたところ、類似商品検索結果が変わるほどのズレは発生しなかったため、こちらでもFloat16 quantizationを利用することにしました。
以下がそれぞれのモデルの量子化を行った場合のモデルサイズです。
| – | 物体検出モデルサイズ | 特徴量抽出モデルサイズ |
|---|---|---|
| Base model (量子化なし) | 12.1MB | 16.4MB |
| Float16 量子化 | 6.1MB | 8.2MB |
| Uint8 量子化 | 3.1MB | 4.6MB |
量子化により、モデルを合計28.6MBから14.3MBに抑えることができました。量子化に関しては今後uint8の量子化を採用できる方法はないか調査していきたいと思っています。
これらの工夫をしたことで、大きな問題は解消しアプリケーションへの組み込みも現実的なラインになりました。
ここまでの検証はiOSデバイス(iPhone7, 11)で行っています。
iOSデバイス向けにはCoreML Delegateと呼ばれる機能を使って更に推論を高速化することができますが、Androidデバイスのサポートも考えたときに運用が複雑になることから今回は導入を見送りました。
MediaPipeはまだ発展途上のframeworkで使いこなすのは難しいですが、今後さらにUI/UXを改善しつつ、メルカリのアプリケーションに組み込めるようにしていきたいと思っています。
EdgeAIチームについて
EdgeAIチームでは、他にもユーザ体験を向上させるためのAI活用を提案しています。
チームの取り組みについてはMercari Gearsというイベントにて紹介しておりますのでよろしければご覧ください。
明日のMercari Advent Calendar 2020 執筆担当は、 WebPlatform チームのmkazutakaさんです。引き続きお楽しみください。




