こんにちは、AIチーム所属の@shidoです。CRE (Customer Reliability Engineering) 領域でMLを扱っています。
みなさんはPythonで本番コードを書くことについてどうお考えでしょうか。「研究/分析以外には使いたくない」「遅い」「動的型付け言語を本番用に使いたくない」といった声が聞こえてきそうです。
しかしながら機械学習サービス(または機械学習サービスのためのサービスなど)を作りたい場合、「学習に利用したPython用のライブラリを使用したい」「Pythonでやっていた分析と同じことを本番環境内でもやりたい」など、Pythonでバックエンドを実装したくなることがあると思います。
この記事ではtype hintsを付けながらPythonを書くことで、GoやJavaのようなサーバーサイドでよく使われる言語と可読性や保守性、場合によっては型安全性も同じレベルで書けますよね、という話をしたいと思います。
想定している読者は
- Notebook以外でPythonを書いたことが無い人
- 実験と分析でしかプログラミングしない人
- 大昔のPythonしか知らない
といった方々で、逆に
- Python以外にもたくさん書ける人
- シニアなバックエンドエンジニア
の方々には物足りない内容かもしれません。
背景
メルカリにおけるマイクロサービス化とPython
過去のエントリーでも紹介されている通りメルカリではマイクロサービス化を進めていますが、その恩恵でマイクロサービスを開発する各チームでは、サービスに合ったプログラミング言語を自由に選択しています。とはいえメルカリのメインストリームはGo言語であり、サービスの基幹となるものを含めほとんどのマイクロサービスはGo言語で書かれています。
しかしながら冒頭の通り、機械学習を用いたマイクロサービスでは研究・実験段階で用いたPythonのライブラリをそのままプロダクションでも使用したいなどといった理由でPythonをメインの言語に採用することが増えています。使用したいライブラリにはデータの前処理パイプラインを記述するもの、自然言語処理や画像処理を行うもの、C++などで記述されたライブラリのPythonラッパー、場合によってはモデルのサービングを行うものなどが挙げられるかと思います。
実験用コードと本番用コード
近年機械学習・データマイニング系の研究成果やデータ分析の実装はほとんどがPythonで書かれており、多くの人がそのような目的でNotebookなどと共にPythonを使っていると思います。主観ですが個人で書かれたこれらのコードは短期的に実行と修正を繰り返すことに焦点を置き、可読性や保守性をあまり気にしない場合もあるかと思います。
Notebookなどで手軽に実験や分析を行えるのはPythonの魅力の一つですが、ある程度大きな会社やコミュニティでは本番用コードは何年にも渡って何人もの人がメンテナンスをする可能性があり、それを考慮した品質を担保する必要があります。本記事では実験用だったPythonコードを本番環境へ実装して行く際に気をつけたいことや最低限守りたいことについて書きたいと思います。
本文
Pythonと型
Pythonは動的型付け言語で、ある変数にどのような操作を行っても不正な操作は実行時にエラーとなって例外が発生するので型安全です(型安全とは何かについてはいろいろな意見があるため触れません)。Pythonが型を評価するのは実行時ですので、当然コンパイラが型によるエラーを教えてくれるようなことはありません。また型が動的に変化するため読み手は型を想像しながらコードを読んでいく必要がありました。
しかしながら、Python3.5からPythonの文法が大きく変わり、関数の宣言やstatementに型に関するアノテーションを任意で付けることが可能になりました。これにより事前にツールを用いて型チェックを行うことで、(多くはないかもしれませんが)ユニットテストをパスしてしまうようなTypeErrorやAttributeErrorを排除することが出来ます。またType HintsによりIDEが属性やメソッドについて補完できるようになり、とても有能になります。さらに他の開発者は型を意識しながらコードを読んだり開発することができ、メンテナンスが容易になります。
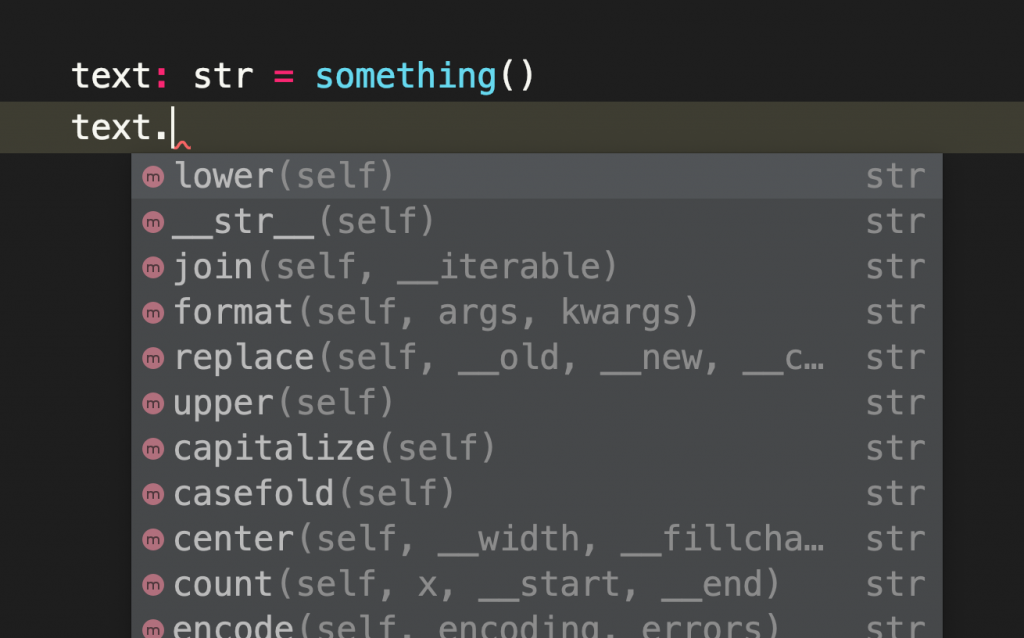
これは関数に対するアノテーションの例です。
ALLOWED_INTEGERS = {1, 2, 3}
def check_integer(x: int) -> bool:
return x in ALLOWED_INTEGERStype hints周りはPython3.6以降も継続的に改良されており、3.6ではPEP 526で変数に対するtype hintsをサポートするようにsyntaxが変更となり、3.7ではPEP 563でアノテーションが遅延評価できるようになり、アノテーションでの型の前方参照がサポートされ、実行速度への影響が小さくなりました。またPython3.9ではPEP 585によりジェネリクスのアノテーションに標準のコレクション型を使えるようになりました。Python3.10でもtype hintsに関する仕様の追加がいくつか予定されているようです。
import typing
ALLOWED_INTEGERS: typing.Set[int] = {1, 2, 3} # Python 3.6
ALLOWED_INTEGERS: set[int] = {1, 2, 3} # Python 3.9
def check_integer(x: int) -> bool:
return x in ALLOWED_INTEGERSもちろんType Hintsは注釈に過ぎず、オブジェクトに対する不正な操作がコード上に存在していても実行時には例外が発生します。機械的に型によるエラーを防ぐためには静的に型をチェックするツールをCIなどに組み込み、それをパスしなければ本番へデプロイ出来なくするような仕組みが必要です。型チェックを行うツールはDropboxのエンジニアが作ったmypy、Googleのpytype、Microsoftのpyright、Facebookのpyreなどが有名です。pyright以外はpypiからインストールすることが出来ます。
当然Pythonにおいてtype hintsはoptionalな構文であり、未定義でも実行可能ですが例えばmypyを使う場合は --disallow-untyped-defs オプションをつけると関数の定義にアノテーションを強制することが出来ます。更にこれらのツールでは型のチェックのみではなく、無駄なキャストを検出したり変数の再定義を許さなかったりすることもできます。どこまで最適化を徹底させるかは要求や状況によるかと思いますが、外部ライブラリの読み込みには寛容でもプロジェクト内部で定義されるコードに対してはきっちりしていると後々嬉しいことが多い印象です。
type hints アンチパターン
熱烈なNotebookユーザーの方がやってしまいがちなことの一つにとにかくprimitiveな型で済ませようとしてしまうというものがあるかと思います。例えばお寿司の注文を取得する関数を
from typing import Dict, List, Tuple
def get_order() -> Tuple[str, List[Tuple[str, str, int, bool]]]:
# Processing
return foo # e.g. "no1234", [("Alice", "tuna", 2, True)]のように書いたとしましょう。注文のデータ構造については置いておいて、実はこの戻り値は注文IDと(お客さんの名前, 魚の種類, 数量, ワサビを入れるか)のリストを表していました。仮にコメントで丁寧に戻り値の解説があったとしても、この関数を呼び出すたびに混乱し、変更を加えるにあたってバグを埋め込みかねません。これを書いた本人でさえ、数分後この関数を使うときに戻り値を確認する羽目になるでしょう。
そこで
def get_order() -> Tuple[str, List[Dict[str, Union[str, int, bool]]]]:
# Processing
return foo # e.g. "no1234", [{user="Alice", fish="tuna", amount=2, wasabi=True}]のように辞書を使って注文の内容を表すことにしました。可読性は多少上がったかもしれませんがこのような辞書を使用してもせっかくのtype hintsの意味がありません。呼び出し側では辞書に対してstr型のkeyを使って呼び出すことになりますが本番環境でそのようなことを行いたくはないはずです。またIDEに対しても不親切です。仮に戻り値の辞書は複数のkeyで固定された型のオブジェクトを持っているということが静的解析から分かるとしてもそこまで考えてくれるIDEは少ないでしょう。
このようにtype hintsがなされていても適切なデータクラスが定義されていない場合、読みにくくtype hintsによる安全性などの恩恵を十分に受けることができません。次節からはtype hintsを活かしながらこの関数を綺麗に書くために最低限知っておきたいことと、その他知っておくと便利なことを紹介したいと思います。
type hints と dataclass
Pythonにはnamedtupleがあり例えばこの例だと
Item = namedtuple("Item", ["user", "fish", "amount", "wasabi"])で定義できるnamedtupleをannotationするのではなく
class Item(typing.NamedTuple):
user: str
fish: str
amount: int
wasabi: boolとtyping.NamedTupleを継承することでコンテナの中身の型を明示しながらnamedtupleを定義することができます。
>>> Item.__annotations__
{'user': <class 'str'>, 'fish': <class 'str'>, 'amount': <class 'int'>, 'wasabi': <class 'bool'>}これを用いることでよりスッキリします。
def get_order() -> Tuple[str, List(Item)]:
# Processing
return foo # e.g. "no1234", [Item(user="Alice", fish="tuna", amount=2, wasabi=True)]もしPython3.7以上が使えるなら標準でdataclassが用意されています。
@dataclass
class Item:
user: str
fish: str
amount: int
wasabi: bool
>>> Item(user="Alice", fish="tuna", amount=1, wasabi=True)
Item(user='Alice', fish='tuna', amount=1, wasabi=True)fieldsを定義することで__init__関数や各種比較関数などが自動で定義されます。dataclassはミュータブルですがfrozen=Trueのオプションを渡すことでnamedtuple同様イミュータブルにすることも出来ます。この場合ハッシュも計算できます。またnamedtupleと同様デフォルト値を設定することも出来ますが、色々と挙動は異なります。dataclassは継承によって両方のfieldを持たせることができる、dataclassはタプルではないため偶然同じ値を持つタプルと比較されない、namedtupleとは異なり__dict__を持つなどです(__slots__を定義すれば持たないようにも出来ますが)。
最後に
@dataclass
class Order:
id: str
items: List[items]
def get_order() -> Order:
# Processing
return foo # e.g. Order(id="no1234", items=[Item(user="Alice", fish="tuna", amount=2, wasabi=True)])のように定義すれば、可読性もぐっと上がり、IDEとの親和性も上がります。多くのIDEがitemsがemptyでないならget_order().items[-1].wasabiがboolであることを分かってくれます。またItemsクラスにeat(user: str)メソッドを実装するとget_order().items.に対してeatメソッド補完してくれるでしょうし、userにint型を渡そうとするとしっかり怒ってくれます。
似たような機能を提供するライブラリにattrsがあり、こちらはdataclassに加えて他の機能も持つ代わりに、dataclassのほうがシンプルです。例えばattrsでは、上に書いたように自前で__slots__を実装せずとも引数を渡すことで自動で定義することが出来ます(そもそもそのレベルでメモリ最適性を求めるならPythonを使わないでしょうが)。ほとんどの場合ではdataclassで十分ではないでしょうか。こちらは標準ライブラリでないため別途インストールする必要があります。なぜattrsがありながらdataclassが標準ライブラリに加えられたのかについてはPEPにも記述されています。
Notebookでは例えば実験の記録を全てdictに突っ込んで使用したりすることがあると思いますが、本番で動くようなコードではしっかりとデータ構造を定義することでtype hintsを活かし、安全性と可読性を上げ、コーディングを快適にすることが出来ます。
Enums
実はお寿司の種類は無限ではありませんでした。ですが上の実装ではネタの型にstrを使用しています。これでは"tuna"と間違えて"tuba"とtypoしてしまっても例外は発生せずIDEは注意をしてくれません。そんなときは列挙型を使うと便利です。
from enum import Enum
class Fish(Enum):
TUNA = 1
SALMON = 2
MACKEREL = 3Enumの中身に興味がない場合は、python3.6でauto()が追加されたのでそれを使うのもいいかもしれません。
from enum import auto
class Fish(Enum):
TUNA = auto()
SALMON = auto()
MACKEREL = auto()もしItem.fishがstr型であることを利用していた、または利用したいのであれば、Enumと同時に継承することも出来ます。
class Fish(str, Enum):
TUNA = "tuna"
SALMON = "salmon"
MACKEREL = "mackerel"
MAGURO = "tuna"
>>> Fish.TUNA.split("n")
['tu', 'a']
>>> Fish.MAGURO
<Env.TUNA: 'tuna'>
>>> Fish.TUNA.value
'tuna'これを用いてItemを定義すると
@dataclass
class Item:
user: str
fish: Fish
amount: int
wasabi: boolとなり、よりミスが少ないコードになりました。
パラメータとenvvar
CLIやプログラムからパラメータを渡す際、数が多い場合は設定のためのクラスを用意したほうがコードがスッキリし、型の扱いもやりやすいことが多いです。特に機械学習系の設定にはパラメータが多くなりがちです。例えばsklearn.ensemble.RandomForestClassifierのコンストラクタは
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)このように多くのkwargsを受け取ります。
一方でtransformers.BertModelのコンストラクタは
class transformers.BertModel(config, add_pooling_layer=True)のようにBertConfig型を受け取るようになっています。どちらが良いいのかは難しい議論かもしれませんが、内部の処理を追っていく際に読みやすく書いていて扱いやすいと感じるのは後者のように設定用のクラスを用意している場合だと思います。例えば設定用クラスにクラスメソッドを実装したりしてメインのクラスを読みやすく出来たりします。機械学習系のオープンソースプロジェクトに関わらず、比較的新しいライブラリは後者の用になっている場合が多い印象があります。
定数を定義するときも型を明示したほうが良いことが多いです。
WASABI_RECOMMEND: Dict[Fish: bool] = {
Fish.TUNA: True,
Fish.SALMON: True,
Fish.MACKEREL: False,
}
TODAYS_RECCOMEND: Fish = Fish.MACKERELまた、本番環境ではほとんどのケースで定数を環境変数を利用して設定し、動作をコントロールしたい場面が多いと思います。そのような動作を設定するオブジェクトを生成したいときにconfig-envが便利です。
import environ
@environ.config()
class SushiConfig:
max_amount: int = environ.var(name="MAX_AMOUNT", converter=int)
todays_recommend: Fish = environ.var(name="TODAYS_RECOMMEND", converter=Fish)
os.environ["MAX_AMOUNT"] = "10"
os.environ["TODAYS_RECOMMEND"] = "mackerel"
>>> environ.to_config(SushiConfig)
SushiConfig(max_amount=10, todays_recommend=<Fish.MACKEREL: 'mackerel'>)このように型をキャストしつつ環境変数からオブジェクトを得ることが出来ます。(このとき__annotation__とConverterが不一致だった場合は型チェッカーが通ってしまうため注意)
依存ライブラリへのannotation
開発するプロジェクトでtype hintsを採用していても、全ての依存ライブラリがtypeについてのannotationを徹底させているわけではありません。しかしながらそういった場合でも、コメントなどで戻り値が明記されていたりコードから戻り値が明らかな場合、可読性上げたりIDEによる補完を受けたりという目的でこちらからhintをつけたほうが良い場合があります。例えば、
# In foobar.py
def fish_for_something(prob: float = 0.5):
return random.choice(list(Fish)) if random.random() < prob else None
# In other project
from foobar import fish_for_something # Not annotated function
catch: Optional[Fish] = fish_for_something()と書けば、もしfish_for_somethingがannotatetionされていなくてもこれ以降IDEは変数catchにNoneまたはFishが格納されていると理解しNoneへの警告やFishクラスへの補完を行ってくれますし、後のメンテナーが読みやすくなります。(実はpycharmを使うとこの程度の関数だとannotationが無くてもOptional[Fish]を返すことを解析してくれます。)
まとめ
Pythonは動的型付け言語で、並列処理に癖があるなど言語由来の難しさもあるので、やはり個人的には機械学習系のライブラリ依存などが無い限りPythonで書く必要は無いのかなと思います。しかしながらtype hintsを採用すると、読みやすいコードをIDEで快適に書くのに役立ち、静的解析ツールを使ってJavaやC#のような型検査を行うことが出来ます。一度慣れてしまうと型検査無しではPythonを書きたくなくなってしまうこと間違いなしです。みなさんもぜひtype hintsで型に厳しいPythonを書いてみてはいかがでしょうか。




