こんにちは。AIチーム所属ソフトウェアエンジニアの@shidoです。
機械学習は様々なサービスの中で強力な武器となりますが、データパイプラインの構築や学習のための計算リソースの確保など、リーズナブルにシステムに組み込むには機械学習特有の困難を克服しなければなりません。
またその困難は機械学習の応用先によっても様々だと思っています。今回の記事ではデータパイプラインの構築に「Human-in-the-Loop (HITL)」と呼ばれる機構を違反出品検知のための機械学習システムへ取り入れた実例と、この仕組みについての考察をお話します。
もくじ
違反出品検知システムについて
本題の違反出品検知システムの話をする前に、我々メルカリが機械学習を違反出品検知に利用している目的やシステム化する際に考慮しなければならない事柄について説明させて頂きます。
メルカリの安心・安全・公正な取引環境への取り組み
メルカリではお客さまに安心・安全・公正なマーケットプレイスを提供するために様々な取り組みを行っております。(詳しくは会社HPにて)
そのような取り組みの一つが機械学習システムによる違反出品の検知となります。
このようなシステムを活用しメルカリでは違反商品をお客さまの目に触れる前に可能な限り早く、出品者様に理由をお伝えすると同時に出品停止・削除させて頂いております。
ポリシーの変更について
メルカリでは法令・社会的変化に合わせて出品物に対するポリシーをアップデートしています。これは不正な取引の検知の質を高めるためには必要不可欠なことですが、機械学習エンジニアリング的には最も辛いポイントとなります。
一般的に機械学習モデルは学習データが多ければ多いほど良いものとなりますがポリシーの変更はときにデータのラベルの定義の変更を意味することになります。実運用ではこのような時に人手でラベル付け直し!というわけにはいかないので、なかなか難しい課題です。
対策としては階層的ラベリングのような予め変更をある程度吸収できるようなラベルの付け方を設計できると良いのではないかと個人的には考えています。
不正取引の潮流の変化について
上記の通りメルカリでは社会的変化に合わせポリシーをアップデートしていますが、プラットフォーム上で行われる不正取引の数や分布も日々変化しています。
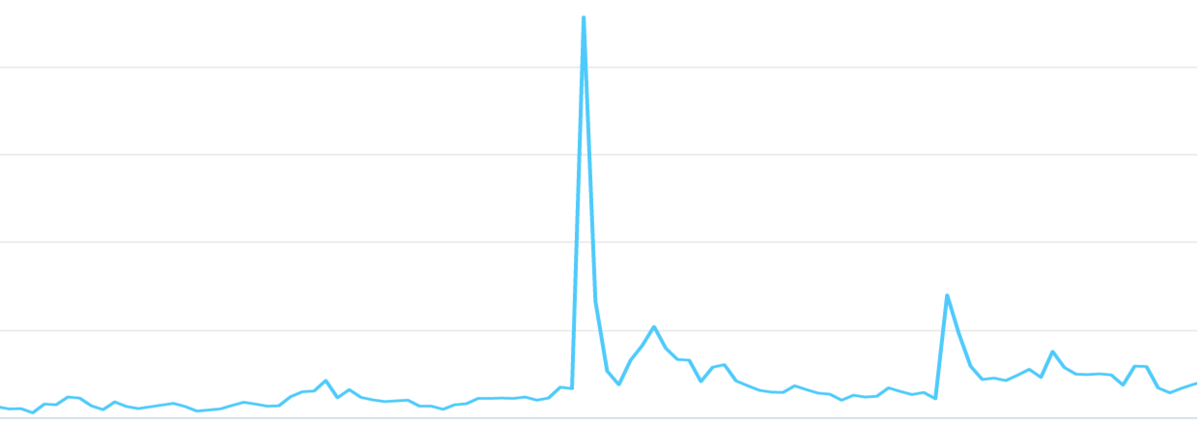
下の図はシステムが検知したある違反種別の違反出品数と時系列を描画した図になります。線が上にあるほど違反数が多かったことを表します。

ある日突然平常時の30倍以上の値を観測したため、弊チームでもざわめきが起こりました。
調べてみると日本国内でとあるイベントが開催されていたことが原因でした。
このケースでは我々のMLシステムが検知できましたが、もしカバーできないような新たな不正があった場合は可能な限りMLシステム側でも対応できるよう対応したいものです。
機械学習システムによる違反出品の検知
ここまで違反出品を検知するシステムの一部に機械学習を組み込んでいることに触れてきましたが、実際どのようなメリットと課題があったかについてまとめました。
機械学習による違反出品検知の強みと課題
機械学習を違反出品検知に実運用する一番のメリットはやはり精度の向上です。メルカリでは機械学習システムの他にもルールベースによる検知など他の仕組みも存在しますが、これらの仕組みでは検知しきれなかった商品も機械学習を用いることで検知することができています。
では機械学習特有の課題に目を向けると、冒頭で触れたデータの確保、計算資源のマネジメント*1、再学習の必要性、ルールベースよりはるかに重い推論コスト、解釈性の欠落、テストの設計などが思い浮かびます。
特にデータに関しては機械学習システムの性能に直結するため細心の注意を払い設計しなければならない部分です。先程ポリシーの変更や不正取引の潮流の変化について触れましたがこのあたりをデータパイプラインに入れる工夫が非常に重要でした。ポリシーの変更は正解ラベル定義の変更と同義ですので、変更があった場合は変更前のデータは一切使われるべきではありません。一般的にこの正解とすべき変数が移り変わってしまう問題は「Concept Drift」と呼ばれています。我々のデータパイプラインではこのような変更を機械的に処理し、データセットのラベルを変更する仕組みが実装されています。
DNNのような表現力の高いモデルを利用する場合はおかしなデータが少量混じるだけでBoostingTree系のような頑健なモデルに簡単に負けてしまいます。したがってデータのパイプラインは我々が最も慎重に考えていることの一つです。
また、機械学習システムの評価も非常に重要です。メルカリは2020/02/07時点、累計11億出品と、多くのお客さまに利用頂いています。その中で不正が疑われるのはこの中のごく少数であり、そのためテストの設計も通常の機能と同じ様に行うことができません。
一般的に、機能や機械学習モデルの評価をする場合ABテストなどを行いメトリクスの変化を測ることが多いと思いますが違反検知の場合はそもそも検知の対象が少ないため、メトリクスの分散が非常に大きくなりがちです。そのため、違反検知モデル間での評価を正しく行うためには一般的な機能のABテストに比較して統計的に妥当性があるかどうかをより緻密に考慮しなければならないと思っています。
継続的なモデルアップデートの重要性
先程データパイプラインの設計に触れましたが、ポリシーの変更をハンドルできたとしても実際に取引プラットフォームで行われている不正取引の潮流の変化にも対応する必要があります。
これは定期的な再学習によってある程度解消することができます。下の図はモデルの性能を時系列で描画した図になります。上にあるほど性能が良いことを表します。色の違う線はそれぞれ別のバージョンとなります。

少しわかりにくいかもしれませんが、2つのモデルが同時に予測している期間を除くと、モデルがリリースした時点が一番性能が良く、その後徐々に下がっていることが分かるでしょうか。これは取引の潮流の変化により、過去のデータセットの分布から正解の分布がずれてくることによるものだと考えられます。
このことより、最新のデータで継続的に再学習を行っていくことの重要性が分かるかと思います。我々のシステムではCronJobにより定期的にモデルの再学習が行われています。
Human-in-the-Loopについて
ここまでにデータに関する課題について何点か触れましたが、これらの解決に必要不可欠だと考えているものがHuman-in−the-Loop(HITL)という仕組みです。
Human-in-the-Loopとは本来機械学習に限らずシミュレータなどのシステムの中に実際の人間が入り込みモックアップなどを果たすことを指すようですが、近年では機械学習の文脈で、機械学習モデルと人間が補完し合いながら動作するシステムを指して使われているのをよく目にするかと思います。
違反出品検知システムにおけるHITL
下の図はメルカリで動作している違反出品検知システムの概略を示した図です。

我々のシステムによって検知された違反商品はカスタマーサポートのオペレーターが必ずすべて確認します。これは違反検知システムのミスで商品が違反ではないにも関わらず通報されてしまった商品(False Positive)を実際に消してしまわないためのものでもあるのですが、このときのログを利用することで機械学習モデルの性能を大きく向上させることができます。
メルカリにおける違反検知のように予測を行いたい対象が時間経過によって頻繁に変化する場合、固定されたデータセットから学習を行うだけでは長期的に精度を維持することは難しいでしょう。しかし我々のシステムではデータの流れに人間が介入するため、判定するべき対象とその他との境界に位置するデータに対してのアノテーションを継続的に入手することができます。このように蓄積された正確で新しいデータを用いてモデルの再学習を行うことで機械学習システムの精度が保たれています。
次に全く新しい違反が現れた場合の話をします。違反検知システム全体で機械学習の他にルールベースなどのシステムも存在しており、人手により変更を加えることで新しい違反に対応します。機械学習はデータが無い状態からの対応は難しいですが、ルールベースシステムがCSオペレーターに候補を送信することでMLモデルへのラベルを新たに蓄積し、このラベルからMLモデルが新しい違反を学習することができます。
更にもうの1つ大きな利点はオペレーターの作業ログを設計することでポリシーの変更にも対応できることです。ポリシーの変更に伴い無効となってしまう教師データがどうしても存在してしまいますが、予めうまく切り分けられるログを残すことで急なポリシーの変更に対して無効となったデータを最小限の大きさでデータセットから除外することができます。これも大きな利点の1つです。
このように我々の機械学習違反検知システムではHITLが機能することで良い性能を保っています。
どのような機械学習システムがHITLを必要とするのかについての考察
個人的にはConcept Driftが頻繁に発生するプロジェクトではHITLによる継続的な教師データの修正が大きく性能を向上させると思っていますが、一般的なWeb系の機械学習プロダクトは”Human”の部分がサービスのお客さまであり、お客さまの行動データがうまくラベルなどになるように設計されているものが多いのでは無いかと思います。例えばリコメンドなどは予測したいものが顧客が買いそうなものや観そうなものとなるはずですが、これらのデータはアノテーションのコストをかけずとも実際のお客さまの行動データを参照すれば明らかになるはずです。
当然ですが人を介入させる場合にはコストもかかりますし、実際に第三者の導入を検討する前にお客さまの行動がそのままデータとなるループが作れないかを検討するべきなのかもしれません。
最後に
大雑把かもしれませんが、機械学習におけるHuman-in-the-Loopとデータ周りについてメルカリにおける実例を交えて紹介いたしました。今後ともメルカリではお客さまの安全な取引のために努力して参りますので、安心してご利用頂ければと思います。
もちろんメルカリではデータ周り以外にもML違反出品検知システムについて様々な努力を行っています。以下の過去記事にて触れておりますので、ご一読頂ければ幸いです。
*1:我々のML違反検知システムでは内製のMLプラットフォーム「Lykeion(リュケイオン)」を利用し、計算資源を動的に割り当てながら行う学習をGitOpsにより実現しています。
Lykeionについては過去の投稿「メルカリの写真検索を支えるバックエンド」で紹介されています。




