こんにちは。Mercari Advent Calendar 2019の20日目は、AIチーム所属エンジニアのlain_m21が担当させていただきます。
一度出したサービスはそのまま放置せず、何度も改善させていくものです。特に機械学習を用いたサービスを改善させていく際には、精度向上がどれほどのビジネスインパクトがあるのか、どの指標を用いてモデルを改善していくべきなのか、ということを常に考える必要があります。それらを検証するために、オンラインでモデルを高速にテストする仕組みが必要だったので作った、という話をします。
背景
機械学習を用いたサービスは、開発時には何かしらの精度指標を最適化するようにモデルを学習させます。しかし、その精度向上が実際にはどれほどのビジネス的なインパクトに繋がるかは、プロダクション環境に出すまでわからないことがとても多いです。
例えば、出品時に商品の提示価格をサジェストするサービスにおいて、学習時には過去の取引価格と予測値の乖離を最小化するようにしていますが、それが商品の購入される確率や出品完了率などに直接的につながっているとは一概には言えません。
学習時に用いられる最適化の目的関数とビジネスKPIがどのような関係を持っているのかを調べるには、複数のモデルを実際のプロダクション環境で走らせて、オンラインで評価する必要があります。
設計
AIチームでは違反検知、価格サジェスト、画像検索など、大小全て含めると10以上の機械学習サービスが運用されています。入出力のインターフェースやクライアントサイドとの通信プロトコルにバリエーションがあるので、その差異を吸収しつつ、新規に立ち上げられるサービスたちにも適用可能な設計にしなければなりません。
また、AIチームの人的リソースなども鑑みて、運用メンバーやサービス開発者にできるだけ負荷がかからないようなシステムを考える必要もありました。
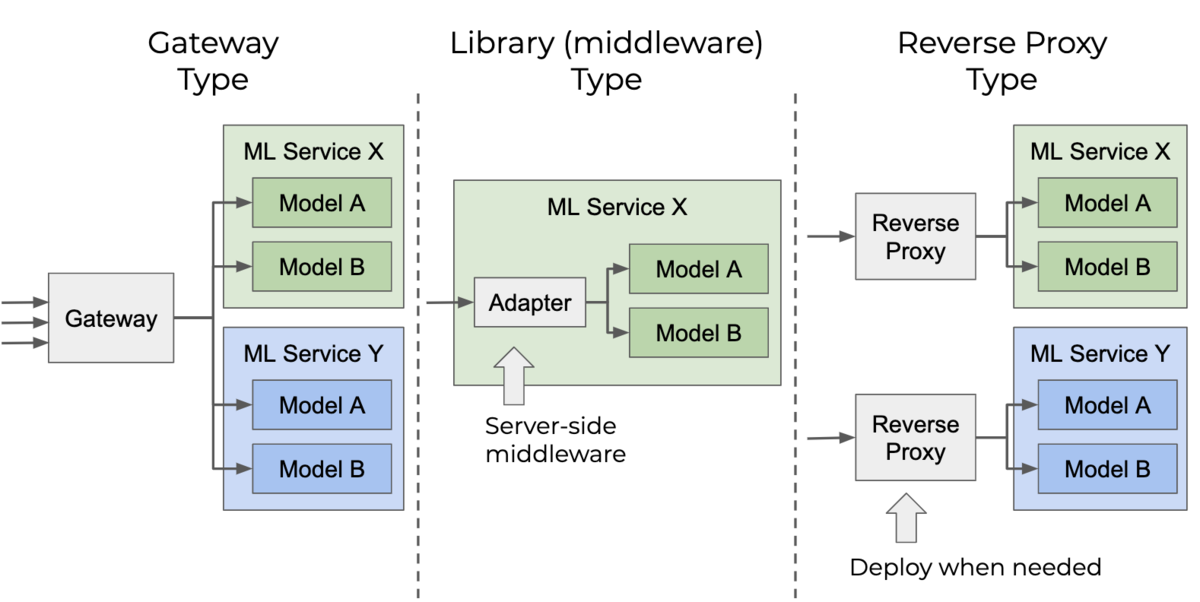
オンラインで機械学習モデルをテストする仕組みには、主に次の3通りの設計パターンが考えられます。
- Gateway Type
- Library (middleware) Type
- Reverse Proxy Type

それぞれについて、下記のように利点と欠点が挙げられます。
Gateway Type
利点
- Gateway単体を運用するだけで良い
- 全てのサービスと実験を一元的に管理できる
欠点
- 単一障害点となりうる
- リリースやオンラインテストのレビューに時間がかかる
Library Type
利点
- 運用コストがほとんどかからない
- 一度サービスに実装してしまえば、オンラインテストのサイクルを速く回せる
欠点
- 実装コストが高く、特に既存のサービスに適用するには大幅なコード変更が必要になる
- オンラインテストの設定などが各サービスに散らばってしまい、複数のサービスでテストが走っていると管理が難しい
Reverse Proxy Type
利点
- 必要な時だけ差し込めば良いので、特別に運用チームを設ける必要がない
- トラフィックのルーティングを変えるだけでリリースもロールバックも容易にできる
- 既存サービスのコード変更の必要性がほとんどない
欠点
- 各サービスの運用メンバーがこのリバースプロキシの運用知識を持つ必要がある
以上を比較し、現AIチームとしては「実装・運用コストをできるだけ抑え」、かつ「手軽に速くオンラインテストする」ことを重要視し、Reverse Proxy Type を採用することにしました。
システム概観
実際にオンラインテストをする際には、どの機械学習モデルのサービスを選択するかを決定するリバースプロキシに加え、オンラインテスト時のログを収集するためのデータパイプラインも用意する必要があります。今回そのシステムを作成するにあたって、そのリバースプロキシのことをExperiment Manager、それとデータパイプラインを合わせたシステム全体を、Experiment Platformと呼ぶことにしました。

Experiment Manager
このリバースプロキシがシステム全体の要になります。上述の通り、現在のAIチームでこのオンラインテストシステムを運用していくためには、主に下記の機能要件を満たす必要があります。
- ポータブルである(簡単にリリース・ロールバックできる)
- 既存サービスの実装(通信プロトコル、入出力)に依らず適用できる
- 高負荷に耐えうる
開発言語
上記の条件から、高パフォーマンスであり、実装の柔軟性が高く、メルカリ内で多くのマイクロサービスの実装実績を持つGoを言語として選択しました。Goには、HTTP、gRPCそれぞれで透過型の(入出力のインターフェースを定義する必要のない)リバースプロキシを実装するためのライブラリ(HTTP, gRPC)があり、実装コストが低かったというのも大きな理由です。
オンラインテストの割り振りアルゴリズム
オンラインテストをする際は、後段のモデルを選択する(A/Bテストのバケットを決める)ために、ハッシュ関数を用いた割り振りアルゴリズムを採用しました。テスト名とテスト対象のUIDの組み合わせとテスト割合の設定から、一意にかつ決定的に割り振り先が決まるようになっていて、異なるテスト間で不要な相関が発生しないようになっています。
割り振りアルゴリズムの性質上、リクエストから何かしらのUID(ユーザーIDなど)を取り出す必要があります。そのためのUIDExtractorというインターフェースを定義し、各サービスでそれぞれある程度自由にUIDの種類やそのソース(ヘッダー、認証情報、ペイロードなど)を指定できるようにもしました。
運用方法
Experiment Managerは透過型のリバースプロキシとして実装したので、既存のトラフィックのルーティングを変えるだけで容易にリリースできます。
オンラインテストに用いる機械学習サービスをまずは全てデプロイし、次にExperiment Managerをデプロイしてそれらサービスと接続します。オンラインテストの設定はConfigMapの形でデプロイしてExperiment Managerにマウントします(下図のIntermediate State)
弊チームの機械学習サービスは独自のGKEクラスターで運用されており、IstioのVirtual ServiceとGatewayを用いてルーティングしています。そのため、段階的なカナリアリリースやミラーリングでのリリースができるようになっています。Intermediate StateでデプロイされたExperiment Managerにミラーリングで接続して安全性を確認した後、徐々に元のトラフィックをExperiment Managerに移し変えていくことでゼロダウンタイムでオンラインテストを開始できるようになっています。
オンラインテストが終了したり、何か不測の事態が起きたら、このリリース手順の逆をたどってルーティングを変えるだけで元の状態へロールバックできます。

プロジェクトからの学び
このプロジェクトを通して、初めて一つのシステムを運用の観点まで含めて設計するという経験をしました。組織でのエンジニアリングでは、チームの状況やリソースの制約、今後の拡張性や保守性を考えた上で設計・開発をしていくことが大切です。その上で開発速度を出す必要もあり、行き詰まりや出戻りを無くすために事前にライブラリ調査をしたりチームの各メンバーにヒアリングをしたりもしました。
今回このシステムは、私一人がひたすら実装して開発し、マネージャーが一人で全部コードレビューするという、とても特異な開発体制でした。(というか無茶でした笑)そのため、バス係数がとんでもないことになっていたので、開発を頓挫させないためにいくつかの工夫をしました。
End-to-Endテスト
まずは一気に動くものを作り、そこから細部を詰めていこう!という方針で、End-to-Endのテストを真っ先に実装しました。システム全体として最低限満たされていなければならない挙動を保証することで、その後の開発で出戻りが少なくなることが期待されるからです。
この方針のおかげで、End-to-Endテスト実装後は、その先の細部の挙動を詰める際は完成形までほぼ一直線に実装を進めることができました。
MVPに注力する
アジャイルの思想のもとでは、まずはMVP(Minimum Viable Product)を一気に作り上げ、市場に出してフィードバックを得ることで改善・拡張させていくべき、という考え方が主流です。今回の開発もその思想にのっとり、まずは現在のAIチームにおいて求められている機能を実現させることだけに集中しました。Goはインターフェースを用いることで拡張性を比較的容易に低コストで担保できるため、今この時点でもいくつか拡張可能性が考えられる部分はインターフェースを実装するようにもしました。ひとまず必要な機能だけ実現し、後々要件が変化した際にある程度改変できる柔軟性も担保できたかと思います。
終わりに
たった一人でやり始めたプロジェクトで、かつ自分にとっては初のGoでのサービス開発でしたが、チームに必要なものをそれなりに楽しみながら開発でき、良い経験ができたと思います。今回の設計・開発の経験はこれからも何かしらの形で活かしていきたいです。(今度はチームで開発したいなぁ・・・)
最後まで読んでいただき、ありがとうございました!
明日(21日目)の執筆担当は @karszawa です。引き続きお楽しみください!




