この記事は MERPAY TECH OPENNESS MONTH の 13日目の記事です。
こんにちは、メルペイ ソフトウェアエンジニアの laughngman7743 です。
メルペイではマイクロサービスにおけるデータストアのデータや、アプリケーションのログを有効活用できるような基盤づくりをデータプラットフォームチームとして行っています。
データプラットフォームではラムダアーキテクチャに基づき、スピードレイヤとして Cloud PubSub と Cloud Dataflow を利用した仕組みに加え、バッチレイヤとして Cloud Composer と Cloud Dataflow を利用した仕組みを構築しています。
この記事ではバッチレイヤのアーキテクチャについてご紹介します。
スピードレイヤのアーキテクチャについては 「GCPでStreamなデータパイプライン始めました」 を参照ください。
構成
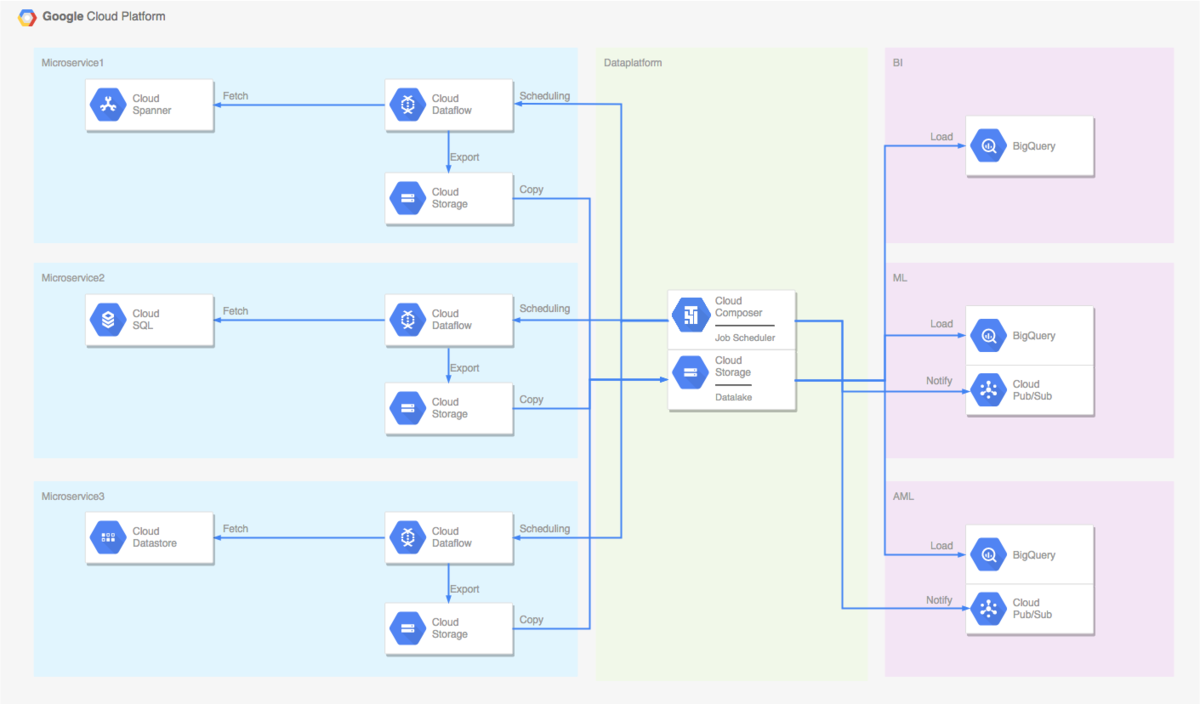
メルペイではマイクロサービスアーキテクチャを採用しており、マイクロサービス間ではデータストアを共有して利用することは行わず、各マイクロサービスがそれぞれ独立したデータストアを持っています。データストアには Cloud Spanner や Cloud SQL 、 Cloud Datastore が利用されています。
バッチレイヤでは、このような各マイクロサービスのデータストアのデータを活用できるように、 GCS や BigQuery に連携する仕組みを提供してます。
決済サービスというセンシティブな情報を扱うこともあり、連携時に個人情報のマスキングもできるようにしています。
構成は以下のようになってます。

真ん中の緑の部分がデータプラットフォームの GCP プロジェクトです。
ジョブスケジューラを提供し、ワークフローのリリース管理を行っています。
Data Lake を提供して、データの管理、提供を行っています。
Data Lake のデータはすべて Avro 形式で管理しています。
左側の青い部分がマイクロサービスの GCP プロジェクトです。
データプラットフォームからは直接マイクロサービスのデータストアは参照せず、マイクロサービス側で Dataflow ジョブを動かして GCS にエクスポートする形をとっています。
直接マイクロサービスのデータストアを参照する構成も考えられるのですが、その場合全マイクロサービスのデータストアを参照できる権限がデータプラットフォームに集約されることになり、セキュリティ的に不健全な状態になりそうだと言うことでこのような構成にしています。
各マイクロサービスに連携するサービスアカウントもそれぞれ分け、1つのサービスアカウントが強い権限を持たない構成にしています。
右側の赤い部分が BI や ML といったデータを利用するチームが持つ GCP プロジェクトです。
一旦データプラットフォームの Data Lake にデータを集約し、複数のチームにデータを提供できる構成にしています。
Dataflow ジョブにはソリューションチームの orfeon が作成した、Dataflow テンプレートを利用しています。
Google オフィシャルでもいくつかテンプレートが提供*1されていますが、orfeon 作成のテンプレートはパフォーマンスも良く、圧倒的に使いやすいです。
詳細については、 MERPAY TECH OPENNESS MONTH の 9日目の記事「メルペイにおける Dataflow Template の活用」 を参照ください。
利用しているGCPマネージドサービス
以下のGCPマネージドサービスを利用しています。
- Cloud Composer
Apache Airflow のマネージドサービスです。
Dataflow ジョブをスケジューリングするのに利用し、定期的に Dataflow ジョブを起動、 Data Lake にデータを集約、BigQuery へのロードや PusSub への通知等を一連のワークフローとして管理しています。 -
Cloud Dataflow
Cloud Spanner や Cloud SQL から GCS へデータをエクスポートするのに利用しています。
Cloud Composer から定期的にバッチジョブとして実行して、 GCS にデータをエクスポートしています。 -
Cloud Storage
Data Lake として利用しています。
-
BigQuery
Data Warehouse として利用しています。
-
Cloud PubSub
データエクスポート完了や、BigQuery へのロード完了を通知するのに利用しています。
Cloud Composer採用の理由
バッチレイヤとして、以下の項目を実現したいと考えていました。
- スケーラビリティ
- スケジューリングのコード管理
- エクスポート処理、BigQuery へのロード処理、PubSub への通知処理をフローとしてコード管理
- WebUI で状況を把握、リカバリができる
- 処理に失敗した時や、時間がかかっている時にアラートを通知
- 並列実行数の制御
- 連携テーブルの追加、変更は簡単な設定ファイルの追加、変更のみで、GitHub 上プルリクエストベースでやり取り
できればマネージドサービスを利用して、インフラ管理コストも削減したいと考えており、
Cloud Composer であればマネージドサービスかつ、以下のように一通り要求を満たすことができるので採用することにしました。
- スケーラビリティ
オートスケーリングには対応していませんが、ワーカーノード数を増やせばスケール可能です。
-
スケジューリングのコード管理
Python コードで管理できますが、メルペイでは以下のような YAML ファイルで設定を管理できるようにしています。
project: my-gcp-project gcp_conn_id: my-gcp-project-conn pool: my-pool schedule_interval: 0 15 * * * depends_on_past: true catchup: false dagrun_timeout: 60 # minutes execution_timeout: 60 # minutes sla: 60 # minutes retry_count: 3 retry_delay: 5 # minutes slack_channel: "#my-alert-channel" pd_conn_id: "pager-duty-conn" - エクスポート処理、BigQuery へのロード処理、PubSub への通知処理をフローとしてコード管理
ワークフローの実装は基本的に Python で行います。
メルペイでは オペレータクラス*2 や フッククラス*3 をカスタマイズしたり、独自で実装したりしています。 -
WebUI で状況を把握、リカバリができる
GCP の IAM 権限と認証が統合されたWebUIが提供されます。 IAM 権限と統合されているため、Terraform を利用して WebUI を閲覧できるユーザの管理が行えます。
-
処理に失敗した時や、時間がかかっている時にアラートを通知
Slack への通知はオペレータの実装が既にあります*4。PagerDuty への通知は独自にオペレータクラスを実装しています。
-
並列実行数の制御
メルペイでは基本的にテーブル単位でのデータ連携を行っています。シーケンシャルに実行していては時間がかかりすぎています。
とはいえ並列で大量にデータストアにアクセスして負荷をかけ、サービスに影響を与えるようなことがあってはならないです。
Airflow には Pool の仕組み*5があります。メルペイではこの Pool の仕組みを利用して並列実行数の制御し、サービスに影響を与えることがないような制御を行っています。
Pool の管理は簡単な iniファイル でしており、 CI で自動的に作成される仕組みにしています。 -
連携テーブルの追加、変更は簡単な設定ファイルの追加・変更のみで、GitHub 上プルリクエストベースでやり取り
メルペイではデータ抽出用のクエリやデータの宛先は以下のような YAML ファイルで記述し、特定のディレクトリに配置すると自動的にワークフローが生成され、連携の追加や変更できるようにしています。
query: | SELECT column1, column2 FROM test_table bigquery: - project: test_project dataset: test_dataset table: test_tableYAML ファイルの特定の項目は Jinja テンプレート*6 として解釈されるようにしており、以下のような動的な記述もできるようになっています。
query: | SELECT id, column1, column2, updated_at, created_at FROM test_table WHERE updated_at >= '{{ execution_date.strftime('%Y-%m-%d %H:00:00') }}' AND updated_at < '{{ next_execution_date.strftime('%Y-%m-%d %H:00:00') }}' incremental: true bigquery: - project: test_project dataset: test_dataset table: test_table merge_query: | MERGE{{ params.destination_project }}.{{ params.destination_dataset }}.{{ params.destination_table }}T USING{{ params.destination_project }}.{{ params.destination_dataset }}.{{ params.staging_table }}S ON T.id = S.id WHEN MATCHED THEN UPDATE SET id = S.id, column1 = S.column1, column2 = S.column2, updated_at = S.updated_at, created_at = S.created_at WHEN NOT MATCHED THEN INSERT( id, column1, column2 updated_at, created_at ) VALUES ( id, column1, column2, updated_at, created_at )各マイクロサービス担当者に YAML ファイルを記述してもらい、プルリクエストをもらう形の運用が行えるようにしています。
実際に運用していくつか気になるところは出てきているのですが、概ねいい感じのバッチ処理の仕組みが構築できているかと思います。
まとめ
メルペイでは Cloud Composer を利用したバッチ処理の仕組みを構築しています。数十のマイクロサービスと連携し、数百テーブルのデータ連携を行っています。
マイクロサービスの開発では Go が利用されていますが、データプラットフォームでは Python や Scala (一部 Java)を利用した仕組みづくりを行っています。
MERPAY TECH OPENNESS MONTH の 14日目の記事はメルペイ SRE の @tjun による「メルペイMicroservices on Microservices Platform」です。お楽しみに!!!




