この記事は先日公開されたこちらの記事の日本語版です
こんにちは、AI Engineeringチームでインターンをしている @dkumazawです。今日は、出品違反検知モデルの開発をマルチモーダルなNeural Architecture Search(以下、NAS)システムを使って高速化したお話をご紹介します。
概要
メルカリでは月間利用者数が1000万人を超える中、利用規約に違反する出品を即座に発見し削除するニーズが高まっている。その中で、出品画像や紹介文など、複数モダリティのデータを最大限に活用して高い精度で違反を発見するシステムを開発することがAIチームには求められている。しかし、(1)マルチモーダルなモデル開発では単一モダリティの場合と比較してベストプラクティスが確立されておらず、(2)また規約や関連法令等の変化に応じて違反カテゴリが追加・変更される場合にもスケーラブルに対応する必要がある、といった課題がある。
以上のモデリングとスケーラビリティの課題に対処するために、DARTSをベースとするNASシステムを開発した。これによって、マルチモーダルニューラルネットのモデリングの自動化を可能にした。さらに、このシステムを内製のデータETLプラットフォームに組み込むことで新違反カテゴリに対するモデルの生成・デプロイにかかる時間を月単位から週単位に削減した。

問題設定
月間利用者数が1000万人を超えるメルカリでは日々お客様から多数の商品の出品を頂いていますが、その一部には利用規約違反等で取り除かれるべき出品が含まれています。これら違反出品は他のお客様の目に入る前に削除されるのが理想である一方、カスタマーサポートのリソースは有限な為、人力で全出品を検査し違反検知するのは非現実的という問題がありました。
そこで、機械学習チームは以前からMLを用いた違反検知システムの開発に取り組んできました。ただ、違反検知システム作成に際し、規約違反ではない出品を誤って削除することは出品者のお客様体験の低下につながる為、開発するモデルは可能な限り高いPrecisionを達成する必要があります。そのため、出品画像や商品の紹介文など、利用可能な複数モダリティのデータを最大限に活用することが求められています。
その上で、2点の課題が存在していました。一点目は、画像のClassificationといった単一モダリティのケースとは異なり、マルチモーダルなニューラルネットのベストプラクティスはまだ模索されている段階である点で、モデリングする上でも実験的要素が強いのが現状です。二点目としては、規約や関連法令の変化等に伴い違反のカテゴリは時間とともに変化するという課題で、カテゴリの変化があった際にも迅速にモデルを作成しデプロイ出来るようなスケーラブルなシステムが必要とされていました。
上記のモデリング及びスケーラビリティの課題に対応するべく、AutoML的なモデル自動作成システムの開発を試みることとなりました。
手法
提案手法ではNeural Architecture Search(NAS)を活用しました。昨今の研究成果に現れている通り、NASベースのモデルは人間が作成したモデルに匹敵もしくはそれ以上の精度の出るニューラルネットワークアーキテクチャを発見することが可能とされています。
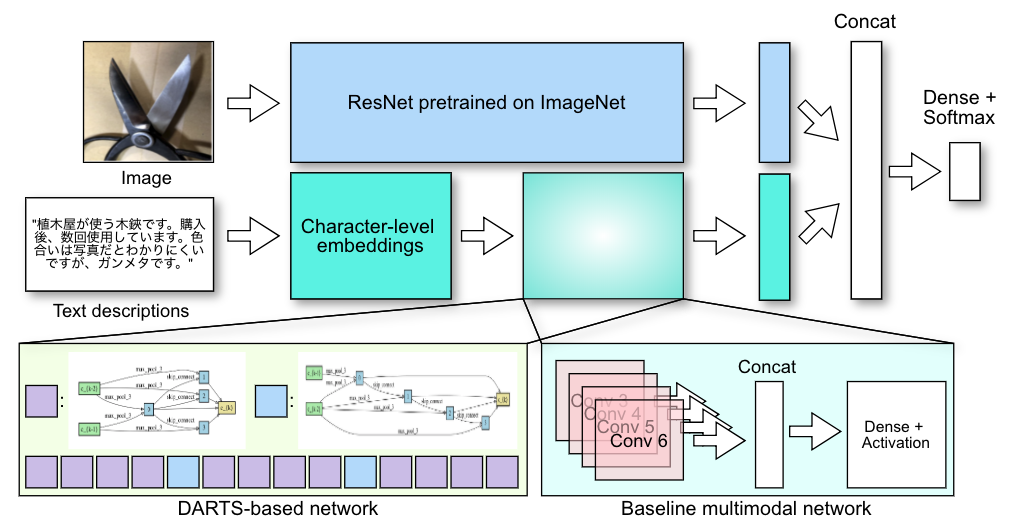
提案手法と比較対象となるベースラインモデルは図1に示されている通りです。ベースラインは、ある違反カテゴリに対し既に実際にデプロイされているアーキテクチャとなっています。提案手法では、アーキテクチャ探索コストの低さと実装の簡単さからDARTSと同様な微分可能なNASを採用しています。
マルチモーダルなデータを活用するため、提案手法では画像の特徴量とテキストの特徴量を結合します。テキスト側のネットワークは「セル」と呼ばれる構造の繰り返しによって構成され、各セルの内部構造が最急降下法によって最適化されます。各セルは利用可能なオペレーションの有向非巡回グラフ(DAG)となっており、中間特徴量をアウトプットします。セルの種類はDARTSと同様に、入力次元を維持するノーマルセルと入力次元を半分にするリダクションセルの2種類を用います。ノーマルセルを複数回積み重ねたものがネットワークを構成しますが、図中にある通り全体のセル数の1/3ごとにリダクションセルを用いることで次元削減を行っています。
ここで、テキスト入力に対応する為、オペレーションは1次元のものを利用しています。候補となるオペレーションは、Kernel sizeがそれぞれ3と5の ConvolutionレイヤーとDilated Convolutionレイヤー、Kernel sizeがそれぞれ3のMax PoolingとAverage Pooling、そしてSkip ConnectionとZero Operationの8種類です。*1 一方で画像側の特徴量抽出は、転移学習を活用するためImageNetで事前学習されたCNNを利用しています。
提案手法とベースラインの学習は以下のように行われます。提案手法の学習は、DARTSのペーパーでも行われている通り、サーチフェーズと評価フェーズからなります。サーチフェーズでは、アーキテクチャパラメータと重みパラメータが交互に最急降下法によって最適化され、最適なアーキテクチャの発見を行います。評価フェーズでは、サーチフェーズで発見されたアーキテクチャを対象となるタスクに対して再学習することで、最終的なClassifierを生成します。一方でベースラインモデルでは、アーキテクチャは既に決まって居るため提案手法のサーチフェーズに相当するものは存在せず、対象タスクに対する通常行う通りの学習が評価フェーズに相当します。
実験
提案手法の精度を検証するため、6つの違反カテゴリに対して性能の比較を行いました。実験用にそれぞれのカテゴリに対して、違反出品(正例)と通常出品(負例)を含むマルチモーダルデータセットを作成しました。現実には違反出品数は通常出品数に比べて非常に少ないので、通常出品を30万件程度ランダムにサンプリングしてくることでデータセットの不均衡に対応しています。
DARTSのような微分可能なNASのサーチフェーズでは、複数オペレーションの重ね合わせ(Superposition)を考慮することに起因するGPUの高メモリ消費が問題となります。その為、プロキシーとなる小さいデータセット上でのアーキテクチャ探索がよく行われています。今回の実験でも同様に、上記の手順で取得したデータセットのサブセットを作成することで、各カテゴリに最適化されたアーキテクチャを探索するのではなく、6カテゴリ全てに対応するアーキテクチャを作成することを目指しました。より具体的には、各違反カテゴリより層化抽出法で正例をサンプリングすることで、6万件程度の均衡の取れたデータセットを作成しました。
提案手法のサーチフェーズの学習はNVIDIA Tesla P100 GPU上で約2日、評価フェーズは各カテゴリに対し約1日掛かりました。ベースライン手法のトレーニングは、同じGPU機種上で約1日掛かりました。
結果
図2にサーチフェーズによって発見されたノーマルセルとリダクションセルの構造を示します。候補となるオペレーションはConvolutionを含んでいたにも関わらず、主にMax PoolingとSkip Connectionが選択されており、今回のタスクでは比較的少ないパラメータ数でも精度を出すことができる可能性が示唆されています。


2つの手法の比較をするに際し、主にAverage Precisionと様々なしきい値でのRecallとPrecisionスコアが重要な評価指標となります。表1に、正クラスのソフトマックス出力のしきい値を0.9に設定した場合のPrecisionとRecallスコアを示します。これらのスコアは未知のテストデータ(正と負の比が1:3程度)に対して求められたものです。Precisionに関しては、提案手法がどのカテゴリでも若干上回っているものの、両手法とも高い値を示しています。一方Recallスコアでは提案手法の優位性が顕著に現れており、いくつかのカテゴリでは0.15程度高い値が示されています。

また、もう一つの重要な観測としては、提案手法による改善にも関わらず、カテゴリAとBは他のカテゴリに比べて精度が出にくくなっています。これらのカテゴリはクラス内でのVariationが大きいことが我々には分かっており、提案手法の応用を試みた上でさらなる特徴量エンジニアリング等を行う等の工夫が必要なことを示しています。
何が変わったか
以前は新しいモデルを作成する際、データ収集、特徴量エンジニアリング、モデリング、精度検証、そしてデプロイ準備まで、2-3ヶ月を要することもありました。一方、開発されたマルチモーダルNASシステムを内製のデータETLプラットフォームに組み込むことで、迅速にモデルの開発・デプロイが出来るようになりました。このシステムによって、新カテゴリに対するモデル作成・デプロイの工数は2-3週間程度にまで削減されています。これによって、機械学習エンジニアはよりモデリングが難しい違反カテゴリに取り組んだり、他の重要なタスクに時間を割けるようになっています。
最後までお読みいただきありがとうございました!今後もAIチームの取り組みを積極的にシェアして行ければと思います。
*1:テキストに1次元のCNN的アプローチを用いているのは、出品の紹介文等が日本語として特に意味をなさない場合が多く(例えば、出品している商品を表現する単語の羅列にすぎないなど)、Recurrentなオペレーションを用いる利点は少ないと判断した為です。




