はじめまして、Team AI Sysmlのエンジニアリング・マネジャの澁井(しぶい)です。 社内で使っている商品分類にマルチモーダルなディープラーニング・モデルを本番稼働させました。本ブログではそのモデルとシステム・アーキテクチャについて紹介します。
分類対象はメルカリに出品される商品すべてです。メルカリには毎日大量の多種多様な商品が出品されます。カテゴリも様々です。お洋服、バッグ、靴、家電、スマホ、おもちゃ、絵本、プラモデル、日用雑貨、書籍、時計・・・。 出品内容を確認するため、社内では画像やテキストを使って分類し、正確に把握しようと努めています。
tl;dr
- メルカリに出品される商品をマルチモーダルなディープラーニング・モデルで分類します。
-
マルチモーダルとは複数のデータ様式(画像とテキスト等)を組み合わせることです。
-
今回使ったデータは画像とテキストで、モデルは畳込みニューラルネットワーク(CNN)の組み合わせです。今後は簡単にマルチモーダルなモデルを作れるように社内ライブラリにしました。
-
Kubernetesを使って本番稼働させました。
-
マルチモーダルについてはこちらの記事もご参照ください。
なぜマルチモーダルなの?
メルカリに出品される商品には商品名、説明文、画像、出品価格、ブランド名等がデータとして付与されています。これまではテキストや出品価格、ブランド名による分類モデルや、画像のみによる分類モデルは稼働していました。しかしテキストと画像を組み合わせることによって、より正確に分類できる商品もあります。そこで今回は、商品名、説明文、画像という非構造的なデータを組み合わせたマルチモーダルな特徴量でディープラーニングモデルを開発し、本番稼働させました。
どういうモデルなの?
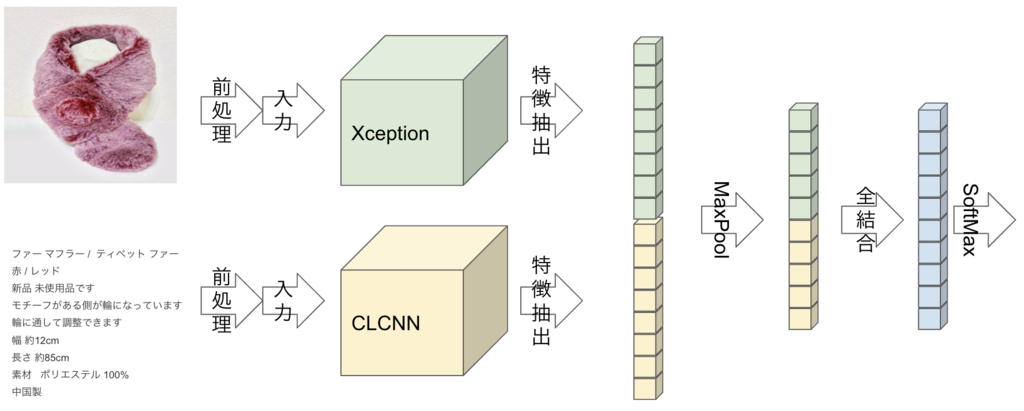
入力データは出品者が出品時に撮影する写真(画像)と、商品名や説明文(テキスト)です。
画像は畳込みニューラルネットワーク(CNN)のXception、説明文は文字レベルCNNで特徴抽出します。特徴は画像、商品名・説明文ともに256次元のベクトルで出力されるので、これらを組み合わせてSoftmax層に入力し、分類します。 図解すると以下のようになります。

画像特徴抽出のXceptionはImageNetで学習済みのモデルから転移学習しています。Xceptionを選んだ理由は学習時間、推論時間、モデルサイズ(パラメータ数)のいずれもバランスが取れていたからです。実験段階では正確性を求めてInceptionResnetV2やNasNetも検証したのですが、ネットワークが複雑で学習や推論にかかるリソース量(GPU、CPU、メモリ)が高すぎたため、NGとしました。
文字レベルCNNを選んだ理由は、メルカリの説明文データが「文章」というよりも「単語の羅列」や「スペック・リスト」に近く、且つ形態素解析器による分かち書きが難しかった(顔文字や絵文字、記号、感嘆詞・・・)ためです。文字レベルCNNにより、形態素解析器の辞書メンテナンスを省略し、モデルの再学習コストをを削減しています。また、文字レベルCNNはメルカリに出品される商品の説明文向けにKatibを使ってパラメータ・チューニングしています。
同じテキスト向けのCNNでCNN-LSTMも試し、文字レベルCNNよりもAccuracyは多少改善されたのですが、LSTMの計算量(=推論時間=必要なリソース量)に見合う改善ではなかったため、見送りました。
結果として、画像、テキストともにCNNで特徴抽出するモデルになりました。
2つのCNN特徴抽出層から出力された256次元のベクトルは、連結した後にMaxPoolingで画像、テキストそれぞれの特徴を取捨選択します。
最後は全結合層とSoftmax層で分類します。
どう作ったの?
ディープラーニングのライブラリはKerasを使用しました。Kerasを選んだ理由は、簡単に書けて且つ複雑なモデルも定義できる点が好きだからです。また、KerasのImage PreprocessingやSequence Preprocessing、Callbacksが便利だった、というのも理由です。
今後のメンテナンス性や再利用を考慮して、マルチモーダル学習のためのネットワーク選択や結合方法、入力データの前処理(DataGenerator)はライブラリ化しています。このライブラリを使うことで、ネットワークの組み換えや違う結合方法を試す、ということをパラメータで設定できるようにしました。

個人的にはモデル作成がだいぶ楽になりました。
どこで動かしてるの?
メルカリのTeam AIでは機械学習の学習、推論をKubernetesで実行しています。Kubernetesで学習、推論を実行、管理できるように、独自に機械学習プラットフォームを開発、運用しています。本プラットフォームでは機械学習のワークフロー(データ取得、前処理、学習、デプロイ、推論)を実行可能にしています。IstioのVirtualServiceを用いることで、モデルのA/Bテストや無停止置換も可能にしています。
うまく動いているの?
2度失敗しています。
- 1度目の失敗
実は数ヶ月前に画像分類で同じ商品分類を本番投入したのですが、誤分類が多すぎて1週間で停止させました。モデルはInceptionResnetV2を使っていました。
そのときの失敗原因は、画像のみではメルカリの出品商品を分類することはできない、というものです。たとえばハサミと包丁は、人間がみると別物とわかりますが、画像分類では似た特徴(細長い金属)に反応して誤分類する一例となっていました。これに「包丁」のような説明文の特徴量を追加しマルチモーダルにすることで、画像の特徴量だけでは困難だった商品を識別できるようになります。
- 2度目の失敗
マルチモーダルの分類モデルをリリースしたあとに、もう一回失敗しています。細かい違いなのですが、ハサミにも「紙を切るためのハサミ」と「植木用のハサミ」があります。これらは似た形状、同じ名称ですが、用途は全く違います。この2つはマルチモーダルのモデルで使っているデータで大きな違いが出ないのですが、対応方法はとても簡単です。「植木用のハサミ」は多くの場合、商品名や商品説明に「植木」や「庭技」という単語が入る(逆に「紙を切るためのハサミ」にはそれらの単語が入らない)ので、キーワード検知(ルールベース)で分類することができます。

モデルの入れ替えやコードの更新は機械学習プラットフォームで簡単にできるようにしているので、失敗してもすぐ対策を取ることができるようになっています。
まとめ
というわけで、メルカリ特有の商品情報をマルチモーダル・ディープラーニングで分類する、というお話でした。ディープラーニングのモデルを本番で動かすためには、機械学習的な指標(Accuracy、Precision、Recall等々)とインフラ的な指標(スピード、メンテナンス性、リソース量等々)のバランスを取ることが重要になってきます。両方の指標でバランスをとり、業務上最適な組み合わせを選択していくことが、機械学習を本番運用するチャレンジであり、面白みです。
今後もより多くの業務にマルチモーダルなモデルを投入していって、またBlogやミートアップで共有できたら良いな、と思います。




