Mercari Advent Calendar 2017 の5日目はソウゾウ エキスパートチームの@tenntennがお送りします。
本日は12月5日、つまりは12月Go日ということでGoの話題について書きたいと思います。
先日、golang.tokyo#10にて”メルカリ カウルのマスタデータの更新“というタイトルで発表を行いました。
その中でgolang.org/x/text/transformパッケージを用いたバイト列の変換について紹介しました。
しかし、golang.tokyo#10では時間の関係上、詳しい説明を省いてしまったため、ここではtransform.Transformerインタフェースの実装方法について解説を行います。
transformパッケージ
golang.org/x/text/transformパッケージ(以降transformパッケージと表記します)は、Goの準標準パッケージであるgolang.org/x以下で管理されているパッケージです。
transformパッケージは主にバイト列の変換を行う機能を提供します。
transformパッケージでは、バイト列の変換処理を一般的に扱うために、Transformインタフェースを提供しています。
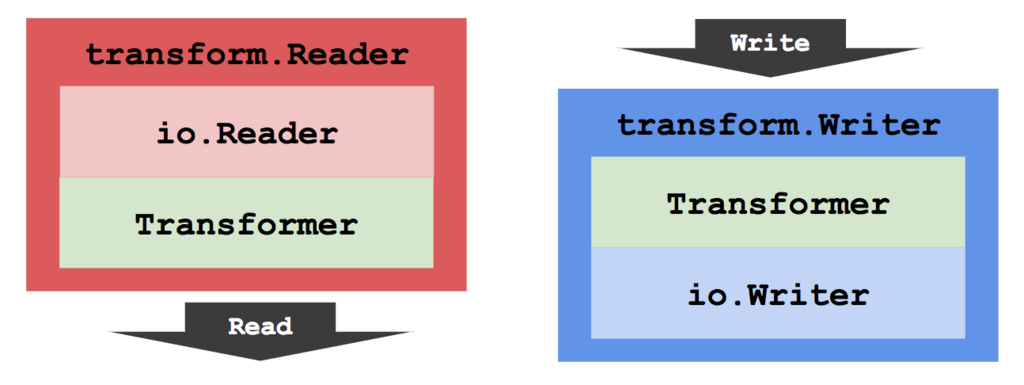
そして、Transformインタフェースを基にして、*transform.Reader型や*transform.Writer型の値を作成することにより、変換処理機能を持ったio.Readerインタフェースやio.Writerインタフェースを実装した値を生み出すことができます。
*transform.Reader型や*transform.Writer型の値は、次のように内部にtransform.Transformerインタフェースを実装する値を持つことで、一度にすべてをメモリ上に載せることなく、ストリームのまま変換処理を行うことができます。

encodingパッケージ
transform.Transformerインタフェースを実装したものとして、golang.org/x/text/encoding/japaneseパッケージ以下のjapanese.ShiftJISやjapanese.EUCJPなどがあります。
これらの変数はencoding.Encoding型で次のように定義されています。
type Encoding interface { // NewDecoder returns a Decoder. NewDecoder() *Decoder // NewEncoder returns an Encoder. NewEncoder() *Encoder }
encoding.Encodingインタフェースが持つ2つのメソッドが返すそれぞれの値、*encoding.Decoder型と*encoding.Encoder型にはtransform.Transformerインタフェースが埋め込んであります。
type Decoder struct { transform.Transformer // contains filtered or unexported fields } type Encoder struct { transform.Transformer // contains filtered or unexported fields }
そのため、encoding/japaneseパッケージなどで定義されているEncodingはtransform.Transformerインタフェースを実装しているということになります。
そこで、第1引数にio.Readerインタフェース、第2引数にtransform.Transformerインタフェースをとるtransform.NewReader関数に次のように、*encoding.Decoder型の値を渡すと、読み込んだバイト列をShiftJISとして解釈して読み込むReaderを作ることができます。
func main() {
dec := japanese.ShiftJIS.NewDecoder()
r := transform.NewReader(os.Stdin, dec)
io.Copy(os.Stdout, r)
}
transform.Transformerインタフェースの実装
さて、transform.Transformerインタフェースを自前で実装するためにはどうすればよいでしょう。
まずはtransform.Transformerインタフェースの定義についてみてみます。
ドキュメントを見ると次のように定義されていることが分かります。
type Transformer interface { // Transform writes to dst the transformed bytes read from src, and // returns the number of dst bytes written and src bytes read. The // atEOF argument tells whether src represents the last bytes of the // input. // // Callers should always process the nDst bytes produced and account // for the nSrc bytes consumed before considering the error err. // // A nil error means that all of the transformed bytes (whether freshly // transformed from src or left over from previous Transform calls) // were written to dst. A nil error can be returned regardless of // whether atEOF is true. If err is nil then nSrc must equal len(src); // the converse is not necessarily true. // // ErrShortDst means that dst was too short to receive all of the // transformed bytes. ErrShortSrc means that src had insufficient data // to complete the transformation. If both conditions apply, then // either error may be returned. Other than the error conditions listed // here, implementations are free to report other errors that arise. Transform(dst, src []byte, atEOF bool) (nDst, nSrc int, err error) // Reset resets the state and allows a Transformer to be reused. Reset() }
このように、transform.Transformerインタフェースには、2つのメソッドがあります。
Transformメソッドはその名の通り、バイト列の変換を行うメソッドです。
一方、ResetメソッドはこのTransformerが再利用できるようにリセットするための機能を提供します。
ここではTransformメソッドについて詳しくみていきましょう。
引数は、変換後のバイト列をいれるdstと変換元のバイト列が入ったsrc、EOFがきたかどうかを表すatEOFです。
戻り値として変換を行ったバイト列の結果が何バイトになったかを表すnDstと変換元のバイト列を何バイト変換したかを表すnSrc、そしてエラーを返します。
引数や戻り値だけを見るとtransform.Transformerインタフェースの実装は一見簡単そうですが、境界値やイレギュラーな挙動を実装するとなると途端にややこしくなります。
前述の通り、transform.Transformerインタフェースはストリームのまま、*transform.Reader型や*transform.Writer型に利用されます。
そのため、一度にバイト列をメモリ上に乗せて処理することができず、小さく分割して処理する必要があります。
小さく分割するということは、分割をまたいで変換処理を行う必要があるということで、その場合非常に処理がややこしくなります。
たとえば、"Merry Xmas"という文字列の"Merry"を"Mercari"に置換するという処理を考えてみます。
引数srcが3バイトで分割されているとした場合、srcは"Mer"となります。
これでは残りの部分がどうなっているのか分からないため、"Merry"にマッチするどうかを判断することができません。
そこでtransform.Transformerインタフェースでは、戻り値にtransform.ErrShortSrcという特殊なエラーを返すことで、呼び出し元にsrcの分割が小さすぎるということを知らせることができます。
一方、変換後の値がdstに収まらないサイズだった場合、transform.ErrShortDstというエラーを返すことで、それを知らせます。
このように、バイト列を分割して処理する際には、境界値を気にしながら処理を書く必要があるため非常にややこしくなります。
そのため、テーブル駆動テストでテストケースを網羅的に列挙しながら実装をすすめないと、イレギュラーなバグに悩まされることになるでしょう。
実際の実装されたものに興味のある方は、筆者の開発したgithub.com/tenntenn/text/transformパッケージが参考になります。
このパッケージは任意のバイト列を別のバイト列に変換するためのReplacerという型を提供しています。
テストもついてますので、どのようなテストケースを準備すればよいのか、transform.Transformerインタフェースの実装の助けになるでしょう。
まとめ
本記事ではGoでバイト列を変換するために用いるtransform.Transformerインタフェースについて紹介しました。
実装するのは若干ややこしいですが、任意のバイト列の変換処理をかけたい場合に便利なインタフェースであるため利用できる範囲は大きいでしょう。ぜひ読者のみなさんも手元で実装してみてください。
このようにメルカリ/ソウゾウでは、Goを書く機会がどんどん増えてきております。
それに伴い、slackのGoチャンネルやソウゾウの社内勉強会であるGo Fridayの議論が活発になってきています。
そして、最近発足したGoの可読性をチェックするGo Readability TeamによるコードレビューなどGoエンジニアにとっては良い環境が整ってきています。
そんな環境で私たちと一緒にGoを書いてくれるエンジニアを募集しています!




