
この記事は、Merpay Tech Openness Month 2020 の18日目の記事です。
はじめに
こんにちは。メルペイ Architect の 五嶋 ( goccy ) です。
先月mercari.go #14 で「最速のJSONライブラリを求めて」というタイトルで、
開発した goccy/go-json という Go のJSONライブラリについて発表させていただきました。
この記事では、発表で触れなかった実装の詳細や今後について紹介したいと思います。
おかげさまで、プレゼンテーション資料は自分が思っていたよりも多くの方に見ていただけたようで嬉しい限りです ( この記事を公開した時点で7kほど )。ただ、資料はあくまで発表の補足ですので、よりコンテキストを踏まえた正確な情報を知りたい場合や、資料に載っていない情報を知りたい場合は発表動画をご覧になっていただければと思います。
資料や動画は こちら の記事にリンクされています。
GoのJSONライブラリの種類
はじめに、現在の Go の JSONライブラリの状況を簡単にまとめようと思います。
GoでJSONのような特定のフォーマットにエンコード・デコードする処理をライブラリに落とす際は、使い勝手とパフォーマンスのバランスから次のように3つに分類できると考えています。
1. コード生成タイプ
対象とする型に特化したエンコード・デコード処理を事前に自動生成するタイプです。
型定義時にコメントで自動生成用のマーカーを書くものなどがあります ( easyjson )。
事前にすべて計算して専用処理として書き出せるので、理論上もっともパフォーマンスが良くなりますが、「コード生成」という一手間がビルド前に必要なため、ライブラリ利用者の開発フローに影響を与えてしまう点は好ましくありません。
2. エンコード・デコード方法をユーザーに記述させるタイプ
対象とする型のレシーバメソッドとして MarshalJSONXXX や UnmarshalJSONXXX などライブラリ側が決めた API を実装させて、それを呼び出すようにする方法です。
それぞれのメソッドの引数としてライブラリ側から Encoder や Decoder が渡され、ビルトイン型 ( int, float32, string など )に対応した専用の Encode , Decode API を通して処理します。コード生成しない方法の中では、最も効率の良い処理ができます。このタイプの OSS では gojay が最速を謳っていて、人気もあるようです。
レシーバメソッドとして実装する以外にも、ビルトイン型に対応した専用のAPIを適切に呼び出すことを前提とするライブラリはこちらに分類できます。
たとえば、使い方がかなり特殊ですが simdjsonをGoに移植した simdjson-go などがあります ( デコードのみ )。
3. 汎用型受け入れタイプ
ライブラリのインターフェースとしては interface{} を受け付ける API だけ用意しておき、どのような型であっても同じ方法でエンコード・デコードできるようにするタイプです。
ライブラリのユーザーからしてみると、エンコード・デコードにあたって事前に行う処理が必要ないため、使い勝手は一番良いと言えると思います。一方、前述した2種類に比べて動的に型の内容を知る必要があるためパフォーマンスの点では劣ります。
標準ライブラリの encoding/json はこちらに分類できます。
また、 encoding/json とコンパチでかつパフォーマンスの良いライブラリとして json-iterator/go というライブラリが人気です。
- ~ 3. は、それぞれ 「パフォーマンス」と「利用のしやすさ」の観点でトレードオフとなっています。( パフォーマンスを重視すれば
1 > 2 > 3の順に選択すべきですが、利用のしやすさの観点では3 > 2 > 1が良いでしょう )
もちろん、「すでに開発フローにビルド前の事前処理が組み込まれていて、コード生成は問題にならない」といった事情などはあるでしょうから、必ずしも上記の関係が成り立つわけではありません。
JSONライブラリを開発するモチベーション
JSONライブラリ戦国時代
JSONパーサがとても簡単に開発できるという理由もあるのか、
Go のJSONライブラリはここまでに挙げたライブラリ以外でも様々なものがあります。
※ 情報は 2020/9/7 のもの
| name | star | type | encode | decode |
|---|---|---|---|---|
| easyjson | 2.8k | コード生成 | ○ | ○ |
| ujson | 68 | ユーザー記述 | ✗ | ○ |
| jingo | 703 | ユーザー記述 | ○ | ✗ |
| simdjson-go | 918 | ユーザー記述 | ✗ | ○ |
| fastjson | 1k | ユーザー記述 | ✗ | ○ |
| gojay | 1.9k | ユーザー記述 | ○ | ○ |
| jettison | 82 | 汎用型受け入れ | ○ | ✗ |
| pkg/json | 225 | 汎用型受け入れ | ✗ | ○ |
| json-iterator/go | 8.2k | 汎用型受け入れ | ○ | ○ |
他にもまだまだあると思いますが、自分が見たことがあるのは上記になります。
それぞれ見比べてみると、やはりエンコード・デコード両方に対応しているライブラリが人気があるようです。
この中で特に人気のある easyjson , gojay , json-iterator/go でベンチマークをとってみた結果、パフォーマンスの良い順に並べると次のようになりました。
gojay > json-iterator/go > easyjson > encoding/json
設計方針の違いがそのまま速度に現れているようにも見えますが、理論上最速にできるはずの easyjson が遅かったりと実装の良し悪しも影響しているようです。
一番遅いのは encoding/json です。そもそも encoding/json が遅いから新しい JSONライブラリを作ろうとしているはずなので、一番遅いのは仕方ないのですが、しかし一番使われているのもまた encoding/json でしょう。理由は
encoding/jsonから乗り換えたいほどパフォーマンスに困っていないencoding/jsonより扱いづらいライブラリを使いたくないencoding/jsonの I/F に慣れているので他の使い方を覚えるのが面倒- 標準ライブラリでないものを積極的に使いたくない
- 他の有用なライブラリを知らない
など様々あると思いますが、 encoding/json の次に人気のあるサードパーティ製のJSONライブラリが json-iterator/go という事実からも、 encoding/json とコンパチのインターフェースを持っていることはライブラリの採用理由として重要な要素だと考えられます。
自分が利用者の立場でも、使うなら encoding/json と同じかそれ以上に使いやすいライブラリが良いと思います。
そこで、もし速さを求めるために encoding/json からインターフェースを変更する判断をしたライブラリに対して、インターフェースを変更することなく速度で勝るライブラリが作れたら、
もっとも使われるライブラリになるだろうし何よりとてもカッコイイことだなと思いました。
そこで、今回紹介する goccy/go-json を開発することにしました。
goccy/go-json

画像は goccy/go-json のロゴで 「ここはまかせて先にいけ」なGopherくんです。
かわいいですね。主な特徴は以下のようになります。
encoding/jsonと完全コンパチ (json-iterator/goと同じ思想 )- エンコードは観測範囲で最速 (
gojayよりも速い ) - デコードは
json-iterator/goよりかなり速く、gojayと競っている状況
実は他にもいろいろ機能を足したいとは思っているのですが、
まずはシンプルに encoding/json 互換かつ最速を目指して開発中です。
参考までに、ベンチマーク結果を Encode Decode でひとつずつ載せました。
より詳細なパフォーマンス比較について知りたい方は こちら をご参照ください。


以降では、どうやって速くしたのか。
その実装の詳細について、エンコーダにフォーカスして説明したいと思います。
デコーダに関しては、発表動画内で実装の面白い部分を網羅できているため、この記事では割愛させていただこうと思います。 ( そのぶん、エンコーダの説明を詳細に行います )
エンコーダの実装
今回ライブラリを開発するにあたって特に頑張ったのはエンコーダの開発です。
この記事では、発表ではあまり詳しく触れなかったエンコーダの実装の詳細について触れようと思います。
実装方針は次のようなものです。
- エンコード対象の型に
interface{}が含まれる場合を除き、エンコード中にリフレクションを利用しない - リフレクション起因のアロケーションを発生させない
- エンコード処理の実行パスを型によって最適化する
1. エンコード対象の型に interface{} が含まれる場合を除き、エンコード中にリフレクションを利用しない
json.Marshal(interface{}) ([]byte, error) や json.(*Encoder).Encode(interface{}) error では引数として interface{} 型をとるため、どうしてもライブラリ内部で受け取った型の判定処理が必要になります。
この際、型の詳細な情報を得るためにはリフレクションを利用する必要があります。
しかし、周知の通りリフレクションは軽い操作ではないため、パフォーマンスに無視できない影響を与えます。
そこでどうするかというと、 Go が静的型付け言語であることに着目します。
実は Go の型情報はそれぞれ固有のアドレスを指しており、例え同じ型名であっても、定義しているスコープが違えば別のアドレス値が返ってきますし、同じ型であれば、必ず同じアドレス値が返ります。つまり型のアドレス値をその型のIDとみなすことができます。
この型情報へのポインタを得るためにはどうすればよいかというと、 interface{} を利用します。プログラミング言語処理系では、言語内部で型を表現する際に、 Boxing / Unboxing という操作を行います。Boxing は int 型などのプリミティブな型をそのまま扱うと型情報が存在しないので、以下のように値とセットで型情報をもった構造でラップする操作です。逆にこの構造から int の値を取り出す操作を Unboxing と呼びます。
type struct {
typ Type // 型情報
v int // 値
}なぜ急にこの話をしたかというと、まさにこの Boxing をしているのが interface{} だからです。 interface{} は Go内部で次のように表現されます。
type interfaceType struct {
typ *rtype // 型情報へのポインタ
ptr unsafe.Pointer // 値のアドレス
}つまり、Goコンパイラは json.Marshal(interface{}) ([]byte, error) の API に 10 といった int の値を渡すようなコードを書くと
json.Marshal(interfaceType{
typ: 0x...., // int型の情報へのアドレス
ptr: 0x0a, // 10
})上記のような擬似コードに変換されて json.Marshal に渡されます。
reflect ライブラリは、上記の interfaceType.typ を参照することで型情報を得ています。
Go が静的型付け言語であることに着目するといったのは、
この型情報がランタイム中に変化することがないことを指しています。
この性質を利用することで、同じ型の値を用いて json.Marshal を何度も呼び出すような場合、
1回目で判定した型情報に対応した専用の処理を構築してキャッシュしておき、
2回目以降では型のアドレス値からそのキャッシュされた処理を呼び出すことで、
型判定の処理をスキップすることが可能になります。つまり以下のような疑似コードです。
type typeIDToEncoderMap map[uintptr]func(uintptr)([]byte, error)
func Marshal(v interface{}) ([]byte, error) {
iface := ((*interfaceType)(unsafe.Pointer(&v))) // Go内部の表現へ変換
typeID := uintptr(unsafe.Pointer(iface.typ)) // 型固有のアドレス値を得る
if encoder, exists := typeIDToEncoderMap[typeID]; exists {
// typeID を key にして専用処理を検索、あればそれを呼び出す
return encoder(uintptr(iface.ptr))
}
f := ...// 専用の処理を構築
typeIDToEncoderMap[typeID] = f // 専用処理をキャッシュする
return f(uintptr(iface.ptr))
}キャッシュされている処理にはリフレクション操作は一切含まれません。
このため、2回目以降はリフレクションを一切使用することなくエンコードすることが可能となります。
※ ただし、型情報に interface{} が含まれている場合は、実行時に様々な型の値が入る可能性があるため、リフレクションを取り除くことはできません。
2. リフレクション起因のアロケーションを発生させない
1.で2回目以降はリフレクション操作を行わないと説明しましたが、
1回目はリフレクションを利用するため ( コード中の「専用処理を構築」の部分 )、Marshal の引数の v がエスケープされてしまいます。
これは、リフレクションで利用することになる reflect.Type がインターフェース型であるために、何かメソッドを呼び出した際に reflect.TypeOf() の引数がエスケープされてしまうからです。
そこで、いろいろなテクニックを駆使して reflect.Type と全く同じ機能を提供しつつ、
エスケープさせずに ( ゼロアロケーションで )利用できる方法を考えました。
このテクニックを go-reflect というライブラリで公開しているので、気になる方はぜひ実装を読んでみてください。
( このあたりの話は発表時に詳しくしているのでこの記事では割愛します。ぜひ発表動画をご覧になってください )
3. エンコード処理の実行パスを型によって最適化する
今回、この記事で一番書きたかった内容がこの項目になります。
1.で記載したコード中の 「専用処理」をどうやって作るか。という話になります。
開発したライブラリでは、専用処理をバーチャルマシン(VM)方式で実装しています。
ここで言うバーチャルマシンとは、言語処理系の実装で利用される、
言語独自の命令列を評価できるようにした仮想CPUのようなコンポーネントのことです。
今回はエンコード処理になるので、言語処理系でいうバーチャルマシンほど複雑な実装にはなりませんが、原理的には似通ったものになります。
go-json では、型情報からエンコード用の命令列を作る操作をコンパイルと呼んでいます。
3.1. 命令列のデザイン
以降の説明のために、 go-json で利用している命令列のレイアウトを示したいと思います。
命令列は、 opcode という構造体を linked list でつないだ構造になっています。
また、命令列を上から順に処理する際に、処理途中の状態を保存しておく必要があります。
言語処理系ではこれを可変長レジスタなどで表現したりしますが、 go-json では []uintptr で表現します。
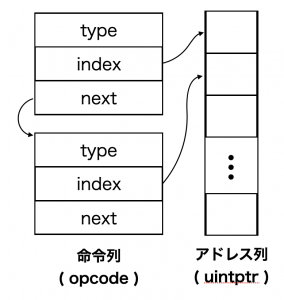
上図のように、 opcode は必ず type , index , next というフィールドを持ちます。実際には様々な命令を処理するためにもっと多くのフィールドを持っていますが、基本はこの3つになります。type は命令の種類です。この値を見て、 switch-case で該当の case にジャンプします。 index はアドレス列のうち、どの部分を参照すれば値の出し入れができるかを表しています。 next には次の opcode へのアドレスが入ります。 next でつないだ最後には、必ず type に opEnd が入った終了用の命令が設定されます。
opEnd の処理でバーチャルマシンの終了処理を書くことで、命令を切り替えるたびに次のような終了判定をする必要はなくなります。
func run(ctx *context, code *opcode) error {
for {
// 工夫しないと、毎回終了判定処理をする必要があり遅くなる
if code.next == nil {
return nil
}
switch code.typ {
case opInt:
code = code.next
}
}
return nil
}opEnd を利用する場合は次のように書くことができます。
func run(ctx *context, code *opcode) error {
for {
// 必ず最後に opEnd になる前提があれば、終了判定は必要ない
switch code.typ {
case opInt:
code = code.next
case opEnd:
return nil
}
}
return nil
}型情報を用いてコンパイルした結果得られる命令列は、グローバルのメモリ領域にキャッシュされます。再び同じ型でエンコードする場合はキャッシュを利用するので高速になりますが、 Go の場合は複数の goroutine から並列にアクセスされるケースも考えなければなりません。
つまり、 opcode 自体に状態をもたせてしまうと、複数の goroutine で同じ opcode を参照した場合に不正な値を読み書きしてしまう可能性があります。
そこで、紹介したように命令列とは別にアドレス列を用い、状態はそちらで管理するようにします。
go-json ではこれを context という型名で管理し、並列に処理する場合であっても、 context を複製することで競合状態が発生しないようにしています。
言い換えれば、複数の goroutine で共有可能な命令列 ( 状態を持たない ) と、
状態だけを管理するアドレス列を利用して処理することになります。
3.2. 命令列の最適化
命令列を処理する際、1命令処理する毎に switch-case による条件分岐が発生します。
このため、この条件分岐の回数を限りなく0に近づけていくことが高速化のカギです。
実際、仮に分岐回数を 0 回にできるとすれば、チューニングの行き届いたコード生成型のライブラリと同等のパフォーマンスを出すことができるはずです。
ここでは、 go-json がどのように命令列を最適化しているかを説明しようと思います。
説明にあたって、以下のような構造の型 T をエンコードすることを考えます。
type T struct {
A int `json:"a"`
B string `json:"b"`
}この型情報をもとにコンパイルすると、次の4つの命令からなる命令列が作られます ( 以降命令列を図示する際は適宜 opEnd を省略します )
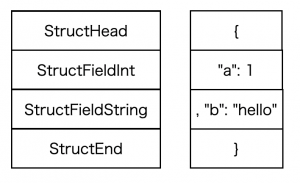
各命令の type の情報だけを表したものを左に、その命令を処理する過程でエンコードされる内容を右に書きました。
ここで、この命令列を減らすことができないかを考えます。
減らすには、前後の命令を連結することができるかで考えるのが定石です。
一方で例えば2つの命令を1つにするということは、その2つの命令の意味を併せ持った1つの命令を作ることとも言い換えられます。その際に、命令の組合せ爆発が起こらないかもあわせて考える必要があります。
この例では、 StructHead と1番目のフィールドに対応する命令である StructFieldInt を合成することを考えます。
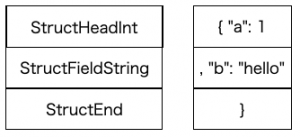
合成すると、上記のようになります。命令列が4つから3つに減りました。
代わりに、新しく StructHeadInt という命令が利用されています。
次にもうひとつ別な例を紹介します。
これはエンコード結果が最適化前と同一にならないため ( JSON としては問題ない )、デフォルトで有効にすることは考えていませんが、非常に効果の高い最適化です。
type T struct {
A string `json:"a"`
B string `json:"b"`
C int `json:"c"`
D string `json:"d"`
E int `json:"e"`
}上記のような型をコンパイルして命令列を書き下すと、最初は以下のようになります。

この状態から、同じ型のフィールドが複数あった場合に、それらをひとつにまとめることを考えます。異なる型どうしをまとめようとすると組み合わせが膨大になってしまいますが、同じ型のものであればそこまで命令の種類を増やさずに対応できます。まとめる数ごとに命令をStructFieldString2 (2つ) , StructFieldString3 (3つ) とあらかじめ用意しておき ( 用意する数は好みですが、5つほど用意すれば十分だと思います )、それに置き換えます。
今回の例では、最適化を行うと以下のように命令列が置き換わります。
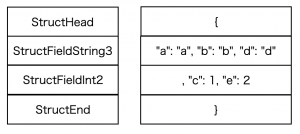
7命令あったものが、4命令まで減りました。ここからさらに、 StructHead と StructFieldString3 をまとめた StructHeadString3 といった命令を用意しておけば、それに置き換えることで3命令まで減らすことができます。
このように、最適化用の命令を用意することで、命令数を減らすことができるのが面白いところです。命令の種類が増えることでソースコードが複雑化していくデメリットがあるため、トレードオフにはなりますが、最適化の面白さが伝われば嬉しいです。
他には、命令数を減らすという考え方以外に、各命令の中で条件文などが存在する場合はその条件を排除した最適化された命令を用意して、特定の場合はその命令に置き換えるなどといったアプローチも存在します。
例えば go-json では omitempty タグがついたフィールドとそうでないもので命令を分けることで、 omitempty のときに必要な処理のオーバーヘッドが通常のフィールドの処理に及ばないようにしています。
3.3. 再帰構造 と interface{}
言語処理系のVMを実装する上で、実装者の腕の見せどころとして、
関数呼び出し、特に再帰関数呼び出しの実装があげられます。
VMのエンジンを巨大な switch-case を内包するループととらえたとき、
関数呼び出しの最も容易な実装は次のようになります。
func run(ctx *context, code *opcode) error {
for {
switch code.typ {
case opCall: // 関数呼び出し用の処理
// 現在の opcode から何かしらの方法で呼び出す関数の命令列を取得する
funcCode := code.funcCode
// ctx を新しく生成して run() を呼ぶことで、
// 現在の ctx を汚さずに関数呼び出しを行う
localCtx := &context{}
if err := run(localCtx, funCode); err != nil {
return err
}
// 何かしら処理結果を反映したい場合は、
// ここで localCtx から ctx へ値を受け渡す
code = code.next // 次の命令に移動
}
}
return nil
}通常、関数を呼び出す際にはスタックやレジスタの情報をどこかに退避させておいて、関数呼び出し中に書き換えられないように注意しなければなりません。VMの実装でもそれは同じで、命令を処理していく中で変化した状態を何かしらの方法で退避させなければなりません。
そこでその実装を容易にするため、値の退避を処理系側にまかせてしまうという手法を取ることができます。
しかし、これは実装が容易な反面、 run 関数を再帰的に呼び出すので、関数呼び出しのオーバーヘッドが発生します。関数呼び出しはご存知の通りとても重い処理なので、できれば避けるべきです。
さらに、Go では再帰呼び出しのたびにスタックを消費するので、
再帰構造の深さの限界がスタックの長さに依存してしまうことにもなります ( 通常は問題にはならないと思います )。
これに対するアプローチとして、 run を再帰的に呼び出す実装をやめて、値の退避を処理系に任せずに自ら実装する方法があります。 CALL ( 関数呼び出し ) から JMP ( 関数先頭の命令への移動 ) への変換です。
エンコーダを実装する上でも再帰処理を意識する場面があります。
例えば次のような構造体をエンコードすることを考えます。
type Recursive struct {
A *Recursive
}
json.Marshal(&Recursive{
A: &Recursive{
A: &Recursive{}
}
})これをエンコードすると、期待値としては {"A":{"A":{"A":null}}} とならなければならないのですが、構造体のフィールドとして自分自身の型を指定している点がポイントです。
こういった型をエンコードする場合、普通はフィールド A のエンコード時に、エンコード用の関数を再帰的に呼び出しながら行います。
また、再帰構造でない場合でも、 interface{} 値をエンコードする場合には、エンコード処理中に型判定を行う必要があります。通常の実装では、型判定してエンコードするという処理を再帰処理として実装するでしょう。
VM方式の実装でも同様で、 interface{} が内包する型から命令列を生成し、その命令列に対して処理を続ける必要があります。
func run(ctx *context, code *opcode) error {
for {
switch code.typ {
case opInterface:
ifaceValue := // interface値を得る
// そのときの値を使って命令列を得る
compiledCode := compile(ifaceValue)
// 再帰構造のとき同様、生成された命令列を run を再帰呼び出しすることによって処理する
localCtx := &context{}
if err := run(localCtx, compiledCode); err != nil {
return nil
}
code = code.next
}
}
return nil
}go-json ではこの手の再帰構造や interface{} のエンコードに上記のような実装を用いず、 関数呼び出しを一切行わずに 実装しています。
次項でその実装方法について説明したいと思います。
3.4. 再帰構造を関数呼び出しをせずに処理する
考え方としては、処理系が関数呼び出し時に行っているレジスタやスタックの値の退避と
同じことを自分でやるということになるのですが、エンコード処理に限って言えば言語処理系のそれに比べると大分シンプルになります。
ここでは、以下のような型 T をエンコードする場合で説明します。
type T struct {
A string
B *T
C int
}上記をエンコードする際の命令列は以下の図のようになります。
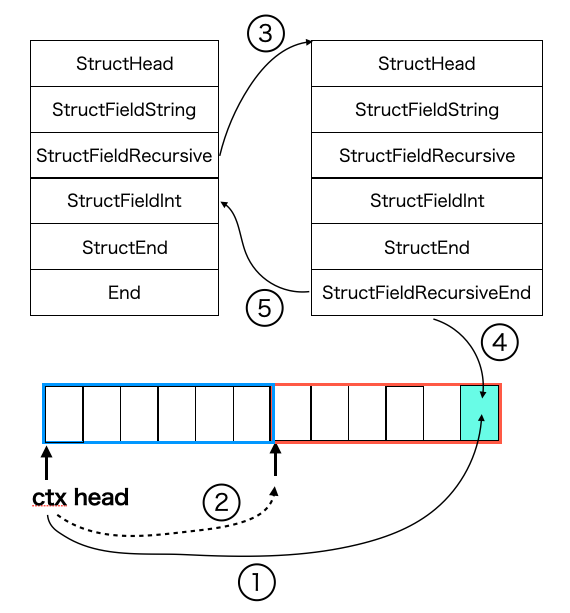
注目する点は、 StructFieldRecursive という命令で、これが再帰処理用の命令を表します。図の左側の命令列は一番はじめに評価される命令列、右側は StructFieldRecursive を処理する過程で評価される命令列を表しています。再帰構造の深さのぶんだけ、図中の StrucrFieldRecursive の右に命令列が存在するイメージです。
ここで図の下に、アドレス列を図示しました。これは実際には []uintptr で表現されていると説明しましたが、青枠で囲われている部分は左側の命令列から参照され、赤枠で囲われている範囲は右側の命令列で参照されることを表しています。
ここで、 ctx head と書かれているのは、[]uintptr の先頭アドレスです ( 実際は reflect.SliceHeader.Data の先頭アドレス )。はじめは 0番目の位置と同じ箇所を指していますが、再帰処理の過程で先頭からずれた箇所を指すようになります。わかる方には、スタックポインタをずらす操作と同様のものだと説明したほうが早いかもしれません。
それでは、図の番号に従って再帰処理の流れを説明します。
事前準備として、
- 再帰処理で実行する命令が利用するアドレス領域のぶんだけ
[]uintptrを伸長する - 再帰命令の最後の命令を
opEndからopStructFieldRecursiveEndに書き換える
ということを行います。その上で、
- 現在の ctx の先頭アドレスを再帰命令列の最後にある
StructFieldRecursiveEndが読み書きするindexの位置に保存する - ctx の先頭アドレスを現在の命令列で利用するアドレス領域外に移動する
StructFieldRecursiveの次の命令を再帰命令の先頭に変更するStructFieldRecursiveEndでは、自身のindex値を使って再帰前の ctx の先頭アドレスを読み出す- ctx の先頭アドレスを再帰前のものに戻しつつ、
StructFieldRecursiveの次の命令に移動する
といったことを行います。
まとめると、再帰で利用するアドレス領域を確保しつつ、現在の状態を退避するために先頭アドレスをずらすと同時にアドレス値を保存しておき、再帰処理の最後で保存したアドレスを読み取って先頭アドレスを戻すといった操作を行います。
単純に run を呼び出す実装と違って実装しなければいけない手順が多く、
またデバッグも大変ですが、それに見合ったパフォーマンス上のメリットも得られます。
interface{} を処理する場合も同様に処理することができるため、詳細は割愛します。
おわりに
8月はじめに mercari.go #14 で発表させていただいた後も goccy/go-json の開発は積極的にしており、今では encoding/json のエンコード処理に関するほとんどのテストをパスするまでに至っています(デコードはこれから詰める段階)。
今後はまず、encoding/json に存在するテスト可能なテストケースをすべてパスしたいと思っており、それが終わって晴れて encoding/json と完全互換だと胸をはって言えるようになったら、 json-iterator/go や gojay に goccy/go-json をベンチマークに追加してもらうよう PR を投げようと考えています。
その過程でライブラリの認知度や実績が上がってきたら、それをもって最終的に Go 本体に取り込んでもらえるよう動きたいとも思っています。そのため、ライブラリはGoの標準ライブラリのみで書かれています。
これらは簡単なことではありませんが、 encoding/json 自体が速くなる恩恵は大きいはずなので、もし応援して頂けるなら、 使ってみたの類の記事やバグ報告、GitHub star や GiHub Sponsor など何かしらのリアクションを頂ければ大きな活力になりますので、ぜひよろしくお願いいたします!
最後になりますが、
今回紹介したライブラリはメルペイ入社前に前職の有給消化期間を使って趣味で開発したものになります。
ですので、次回ブログを書く機会を頂いた際は、メルペイ入社後に業務で開発したものに関して書いてみたいと思います。




