こんにちは、メルペイでSREとして従事している @myoshida です。この記事は Merpay Tech Openness Month 2021 の8日目の記事です。
SREチームはお客さまへよりよいサービス利用体験を提供するため、日々様々な改善活動に取り組んでいます。その活動の一環としてPlaybookの概念を導入し、運用者の運用負担を減らす取り組みを始めました。今回はそのことについて説明してみたいと思います。
概要
メルペイではアプリケーションエンジニアとSREの双方がオンコール制度のもと運用に携わっています。
運用の悩みは様々ですが、そのうちの1つに手順書の取り扱いがあります。
どこに置くべきか、更新はされているのか、何を書けばいいのか、どの場面でどの手順書を利用すればよいのかというような悩みはどこの現場でも少なからず存在すると思います。
そこで、Playbookと呼ばれる体系的なドキュメント群の概念を既存の運用システムに取り入れることで、上記のような悩みを取り除き、オンコール担当者の負担を減らしてよりよい運用体験を目指すことにしました。
また、メルペイですでに取り組んでいるSLOを基準とした運用とリンクさせることで、運用業務の際によりSLOを意識した運用が行えるのではないかと考えています。
以降の文章ではもう少し詳しく現在のメルペイの運用のやり方と、Playbookをどう取り入れたかについて説明します。
Playbookとは
Playbookとは元はアメフトの戦略集などのように主にスポーツの分野で使われていた用語で、現在ではビジネスの分野でも戦略集やノウハウ集のような意味で利用されているようです。
ITの分野では「手順書」の意味で「Runbook」がよく使われますが、Playbookもいくつかの企業が自分たちの考え方で定義して活用している状況です。
メルペイにおけるエンジニアの運用への関わり方
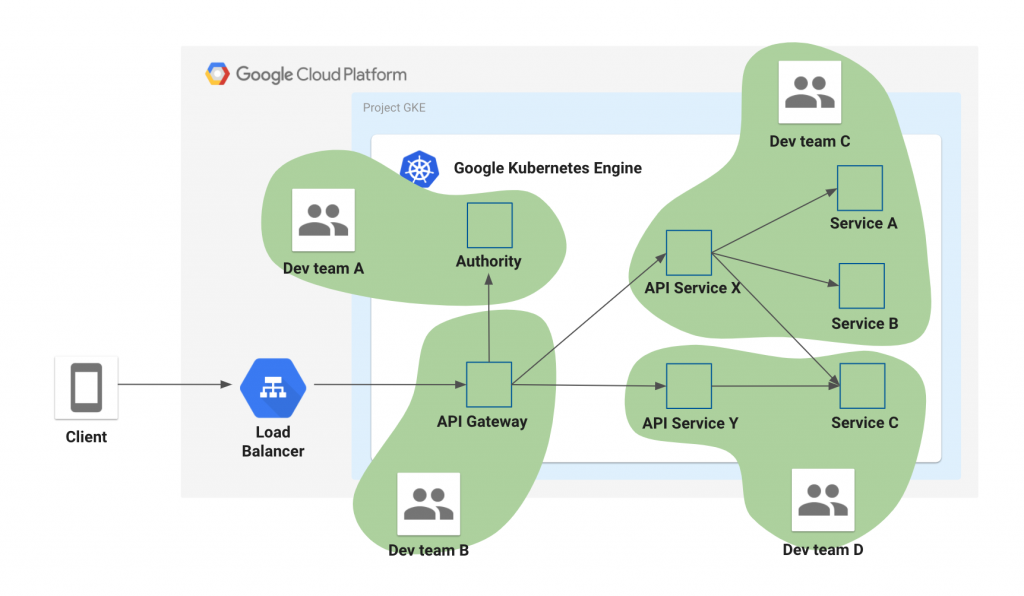
メルペイという1つのサービスを提供するために、マイクロサービスアーキテクチャとよばれるシステム構成を採用し、多数のマイクロサービスを構築して運用しています。
アプリケーションエンジニアのチームはいくつかのマイクロサービスを担当し、開発から運用まで自分たちで面倒を見ています。
SREはその節々において、共通基盤や運用に関する諸所の業務のサポートを行ったり、一緒にアラートの分析を行ったり、改善タスクを分担して対応しています。
また、空き時間を捻出してツールの開発や新しい仕組みの利用促進、SaaSをより効率的に利用するための検証といったProactiveな活動も行っています。
アラートやトラブルが発生してから対応するいわゆるReactiveな「守りの運用」を減らすために、あらかじめ改善を施しておくことでアラート等を減らし、活動時間をより有意義なものにするProactiveな「攻めの運用」を増やすように意識して業務を行っています。
オンコール当番制度
メルペイではオンコールと呼ばれる運用監視担当者の当番制度を敷いており、1週間ごとに当番を入れ替えて監視やその他の運用活動を行います。SREも例外ではありません。
オンコール担当者の責務の範囲は各チームに委ねられていますが、SREとしては、
- アラートの確認と初期処置
- エスカレーションされてきたトラブルシューティングへの対応
- 本番データベースの更新作業や、インフラ基盤のKubernetesに関する作業、Terraformを利用した各種本番インフラの更新作業
- その他各チームから依頼された各種タスク
- 日々の運用状況のサマリ作成とチーム内共有
などを行っています。
運用に関するシステム構成
メルペイでは監視の基盤としてDatadogを採用しており、ほぼすべてのマイクロサービスからアプリケーションのログや各種メトリクスが送られています。
アラートが発生したら、設定に応じいくつかのSlackチャンネルに通知が飛ぶようになっており、オンコールの担当者はそれを受け取って内容を確認します。
エラーの内容によってはPagerDutyに設定された担当者の携帯電話にも自動で電話がかかるようになっています。
課題
オンコール担当者になってみて感じた課題としては以下のようなものがありました。
- 問題がないような状況でもアラートが多数発生しSREやマイクロサービスの担当エンジニアが不必要に呼び出されたり起こされたりする
- 組織が成長し仲間が増えるのに従ってマイクロサービスの数も増えて複雑度が増しており、あるアラートが発生した場合にお客さま目線で何が起こっているのかが捉えにくくなっている
- SREから見て、そのアラートが何をもって問題ないとされているのかが理解しづらい
- 運用手順書が複数のドキュメントプラットフォームに自由に配置されており、各エンジニアの熱意と善意によって管理されている
上記のような課題に対して、すでにいくつかのアプローチを行っているのですが、1つの施策としてPlaybookの共通管理を導入し、運用手順書側から整備を行うことでエンジニアの運用業務の効率化に挑戦することにしました。
メルペイにおけるPlaybookを定義する
既存の運用システムにPlabyookの管理機能を追加するにあたり、Playbookとはどのようなものであるかについて議論を行いました。議論には、すでにPlaybookの概念を取り入れて活動を行っている社外の情報を参考にしました。
考え方1 – PagerDuty社の例
いわゆる運用手順書は Runbook と呼ばれ、それらを包括するより大きな概念をPlaybookと呼びます。
Runbookがレシピまたは料理の本(Cookbook)である場合、Playbookは、特定の社交イベント、たとえば結婚式を主催するためのガイドブックになります。食事を効果的に調理するにはCookbookが必要ですが、料理はイベント全体の1つの側面にすぎません。
具体的には、Runbookは、サーバーへのパッチ適用やWebサイトのSSL証明書の更新といった定期的に発生するタスクの概要を示します。
(参考)
考え方2 – Amazon Web Services社の例
Playbookは障害発生時に使用されます。問題を特定するために実行する手順が記されています。
十分なスキルを持つものの、対象のシステムに精通していないようなチームメンバーでも、Playbookを参照することで情報の収集、障害内容の特定、問題の根本原因の特定などを行えるようにします。
Playbookは、組織の制度的知識を保持します。知識を共有し、より多くのチームメンバーが同じ結果を達成できるようにすることで、主要な担当者の負担を軽減します。
(参考)
メルペイのPlaybookの考え方
メルペイのPlaybookはSLOに紐づきます。SLOに紐づくアラート(後半で説明します)が発生した場合に、エンジニアが何を行い、どのように考える必要があるかといった、SLOアラート対応時の一連の流れを示します。
その中の対応作業の各手順のうち、オペレーション部分の再利用可能なものはRunbookとして切り出します。実際には既存の手順書のなかで再利用性の高いものをすでに切り出されているRunnbookと位置づけ、Playbookから辿れるようにしたりすることが考えられます。
また、社内の誰もが共通の場所で閲覧できるようにすることで、Amazon Web Services社の考え方のように知識の共有やオンボーディングにも利用できます。
Playbookのテンプレート
具体的には、以下のようなドキュメントのテンプレートを用意しておき、必要箇所を埋めたものをPlaybookとしてGitHubで管理します。
---
title: Playbook1(Maybe similar to monitor name)
severity: <critical|warning>
---
## Effects
### Customer
- some effect for customers(free text)
### Employee
- some feature degradation(free text)
## What
- description of what happened
## Why
- description of why alert is kicked
## Who to contact
- Merpay SRE
- Platform Group Platform Infra
## Investigation
### Case A
- Run 1
- Run 2
- Run 3
### Case B
- Run 1
- Run 2
- Run 3
## Mitigation
### Case A
- Run 1
- Run 2
- Run 3
### Case B
- Run 1
- Run 2
- Run 3
## Post Check for Recovery
### Case A
- Run 1
- Run 2
- Run 3
### Case B
- Run 1
- Run 2
- Run 3各項目について簡単に説明します。
Title
そのPlaybookのタイトルを記載します。
Severity
メルカリ・メルペイにはより詳細なSeverityの定義があり活用されていますが、ここではその定義のうち、お客さまに影響するものをCritical、影響しないものをWarningとし、そのどちらかを選択してもらうようにしています。
Effects
このPlaybookが参照される際に発生している問題が起こったときの、影響範囲や内容について記載します。
マイクロサービスの種類によってはお客様だけでなく社内のメンバーにも影響があるものや、社内に限定して影響があるものなどがあるため、CustomerとEmployeeの項目を用意しています。
What
このPlaybookを読む必要が出た際に起こっている事象は何なのかの説明を記載します。
Why
このPlaybookを読む必要が出た際に起こっている事象はなぜ発生したのかの説明を記載します。
Who to contact
このPlaybookを読む必要が出た際、誰に連絡を取ればよいかを記載します。チーム単位のSlackIDなどを記載する想定です。
Investigation
調査方法や切り分けの考え方などについて記載します。複数のケースの記載が必要であれば項目を分けて書くようにします。
Mitigation
暫定対応の手順について記載します。複数のケースの記載が必要であれば項目を分けて書くようにします。既存の手順書が流用できる場合はそのリンクを貼ります。
Post Check for Recovery
問題が解消されたと判断するための手順を記載します。複数のケースの記載が必要であれば項目を分けて書くようにします。既存の手順書が流用できる場合はそのリンクを貼ります。
SLOについて
メルペイの各マイクロサービスはSLO(Service Level Objective) を定義し、それに基づいて運用しています。SLOとはざっくりいうと、お客さまの期待や満足度に焦点を当てた信頼性の目標です。
SLOの詳細については先日、おなじSREチームの @foostan が Merpay Tech Fest 2021 にて発表しましたので、そちらをご参照いただければ幸いです。
SLOに紐付いたPlaybook
メルペイではSLOに基づいた運用を重視しているため、SLOを達成できているか、その上でお客さまの満足度を向上させるための機能開発ができているか、という点で既存の運用を評価しています。
具体的にはマイクロサービス毎にいくつかのSLOを設定し、さらにそのSLOごとにアラートを設定して、アラートが発生する=エラーバジェットが減りSLOの達成が遠ざかるという認識でアラート対応を行っています。
つまり、SLOを達成するためにはアラートはできるだけ発生しないようにしたいし、発生したとしても素早く解消したいということになります。
アラートに対して適切なPlaybookを素早く参照し、事前に定義された手順や考え方のもと確実に事象を解消させることができれば、エラーバジェットの損失も少なく済み、信頼性をより維持・向上しやすくなります。
そのような状況を実現するために、Playbookを作成し、適切なSLOのアラートに紐付ける仕組みを今回開発しました。
Playbookシステムの仕組み
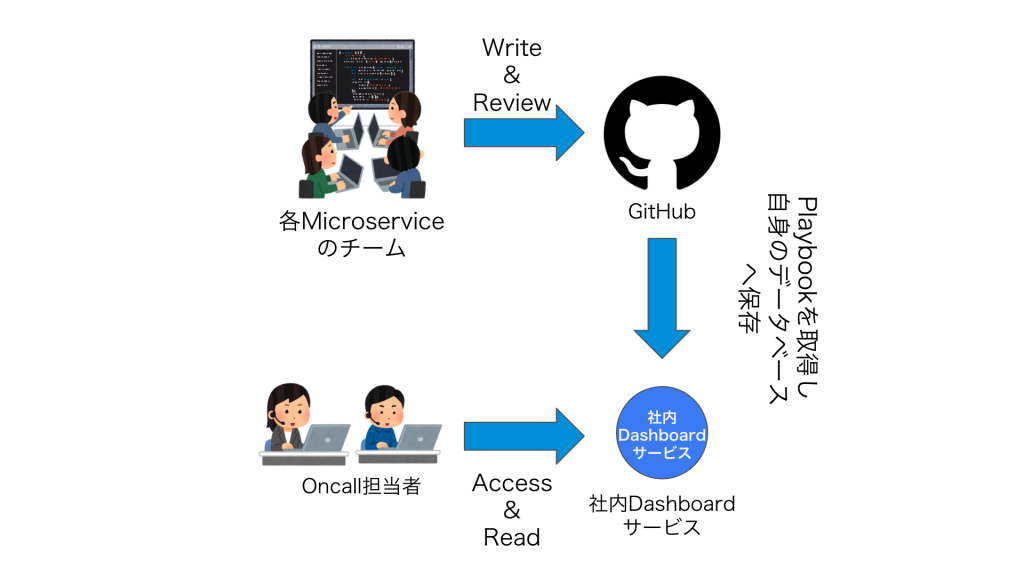
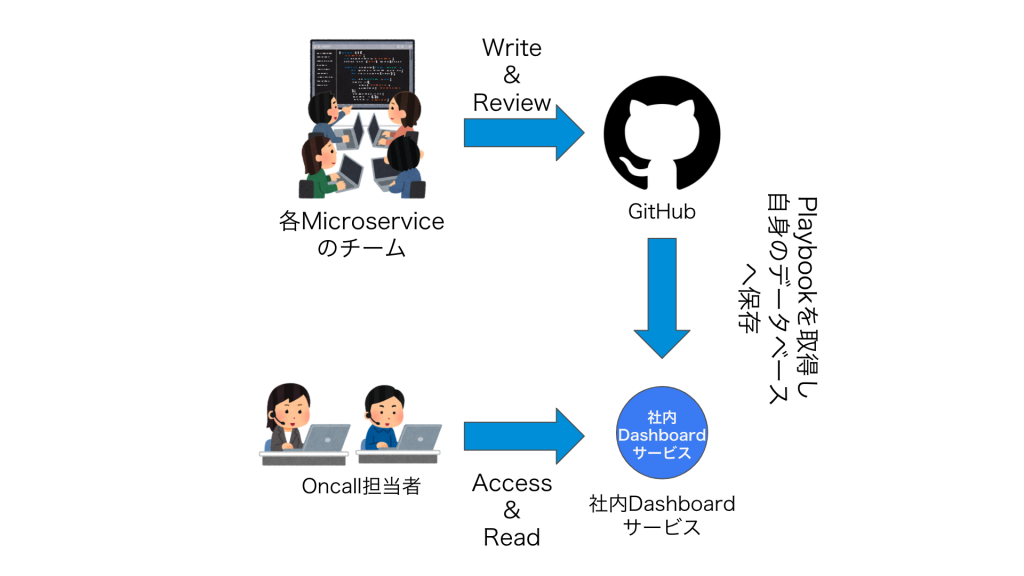
Playbookは指定されたGitHubリポジトリ上の指定されたディレクトリ内に作成する必要があります。そのリポジトリは社内のマイクロサービスの定義を集中管理しているTerraformのリポジトリです。
リポジトリにPlaybookをいくつか(ひとつでもいい)追加し、Pull Requestを作成します。レビューをしてもらい、問題なければマージします。マージされると、社内Dashboardサービスがそれを取り込みます。
社内Dashboardサービスでは、マイクロサービスに関する様々な情報を一元的に管理して検索・閲覧ができるようになっています。
今回はその社内Dashboardサービス上にPlaybookを取り込む機能と、Playbookを表示する機能の追加を行いました。
また、SLOを定義するとTerraformが実行され自動でDatadogのモニターを作成する仕組みがすでに存在します。そこにも手を加えてSLOの定義にPlaybookを指定できるようにしました。
あるSLOに対応するPlaybookを指定すると、モニターのアラートのメッセージの中に、Playbookへのリンクが埋め込まれます。これによって、オンコール担当のエンジニアは、アラートメッセージを受け取るとそこに書かれてあるリンクから社内Dashboardサービス上のPlaybookを閲覧し、より素早く確実に想定された対応を行うことが可能となります。

SLOに関する監視リソースの自動生成については、 Merpay Advent Calendar 2020 でおなじSREチームの @T が紹介記事を書いていますので、そちらをご参照いただければ幸いです。
Playbookシステム導入の利点
Playbookを各マイクロサービスで利用してもらうことにより、次のような利点があると考えています。
- Playbookの置き場所がGitHubに統一される
- PlaybookはGitHubにPull Requestを出して作成・更新するものだというのが自然に理解できる
- Pull Requestとレビューの機能が利用可能になる
- テンプレートを用意しているので何を書けばいいかが分かりやすくなる
- これまで内容や粒度は個人の裁量に完全に任せていたがガードレールを設けることでPlaybookの質がより均一化される
- 書かれてある項目が同じなので、慣れていないマイクロサービスの対応時にも手順書が読みやすくなる
- アラートメッセージからすぐに参照できるようになるので、オンコール対応時にすばやくPlaybookにたどり着ける
- その結果エラーバジェットの損失を少なくしSLOを達成しやすくなる
- Playbookを充実させることにより新しいメンバーのオンボーディング教材の一部として利用可能になる
今後は
この取り組みはまだ始まったばかりですので、まずは各マイクロサービスのエンジニアに使ってもらってフィードバックをもらいながら、よりよい仕組みになるように改善できればと考えています。
たとえば、社内Dashboardサービスにはマイクロサービスを管理するチームの一覧や各チームのメンバーを確認できる機能がありますが、それをうまく使ってチーム単位でPlaybookを検索できるようになれば、オンコール対応のエンジニアはより安心してアラート対応に臨めるかもしれません。
また、このPlaybookはSLOと結びついています。SLOの運用がより洗練されると、それに伴ってPlaybookもより使いやすいものになると思っています。
SLOに関連する機能との二人三脚での見直し、改善が行えればと思います。
仲間を募集しています
現在メルペイでは立ち上げ中のメルコイン社への協力などを行っていることもあり、より多くの仲間を募集しています。
SRE、そしてSREマネージャーの職種もオープンしておりますので、ご興味がありましたらぜひご応募ください。
- ソフトウェアエンジニア (Site Reliability) [Mercoin / Merpay]
- エンジニアリングマネージャー (Site Reliability) [Mercoin / Merpay]
Merpay Tech Openness Month 2021では引き続きメルペイの技術やエンジニア組織に関する発信を行っていきます。
次は来週月曜日に @kenken_merpay さんによる 「なめらかな立ち上がりのためのメルペイAndroidチームのオンボーディング」が公開されます。そちらもよろしくお願いします。
参考にした情報
- American football plays – Wikipedia
- What Is a Playbook in Business? | Indeed.com
- What is a Runbook? | PagerDuty
- Playbook – AWS Well-Architected Framework
- Merpay Tech Fest 2021_メルペイにおけるSLOの活用事例 – 信頼性を定義しよう / Use case of SLOs in Merpay Let’s Define Reliability – Speaker Deck
- Maintain SLO 2020 | メルカリエンジニアリング




