Kubernetes CronJobと仲良くなりたい
この記事は、Merpay Tech Openness Month 2020 の17日目の記事です。
こんにちは。メルペイのSREの駒崎(@komattaka)です。
暑かったり台風だったりと大変な日々が続いていますが、ご自愛ください。
目次
- 対象読者
- 得られるもの
- 説明しないこと
- はじめに
- CronJobの仕組
- そもそもCronJobとは何か
- パラメータの解説
- CronJobが作成される流れ
- メルペイでは何に困っていた?
suspend: trueにしていたCronJobがfalseにした後もJobを生成しない- (GKE特有) NodeがCluster Autoscalerによって停止されると、そのNodeで稼働していたJob(Pod)のEvictをCronJobが正常終了したと誤解しconcurrencyPolicy: Forbid(Replace)なのに並列稼働した
- ユースケース別に設定方法を解説
- Timezone UTCな環境で毎月1日0:00(JST)に実行したい
- 長時間のバッチなのでPreemptible Nodeで動かしたくない(Anti Node Affinity)
対象読者
- Kubernetes CronJobを使っている方
- ジョブコントローラからCronJobに移行しようと思っている方
得られるもの
- CronJobを設定する上で気を付けるべきオプションを理解できる
説明しないこと
- Cronについて
- 常に動いている(Deploymentから生成されるような)Pod内でCronのような挙動を行う方法 (https://github.com/robfig/cronのようにCronJob Controller内でも使われているものもあり、弊社でもこのユースケースがありますが、本題とずれるので割愛します)
はじめに
メルペイでは、スケジュールされたジョブを何度も実行するユースケースがあります。例えば、お客様の決済情報を定期的に調査して自動的に修復(リコンサイル)したり、毎月のレポートを作成したりとユースケースは多岐にわたります。
私たちはGKEをベースにサービスを提供しているため、基本的にKubernetes CronJobでそういったジョブを動かすようにしています。
今までの私たちの知見を共有することで、既にCronJobを使っているもののCronJob独特の挙動に悩んでいる方、別のジョブスケジューラと比較検討して何を使おうか悩んでいる方の参考になれば幸いです。
ここで記載する用語ですが、Kubernetes Jobを「Job」と表記し、Kubernetesに限らない一般的なジョブのことを「ジョブ」と表記することで区別します。
Kubernetes 1.19でのCronJobの挙動を解説しているため、それ以上のバージョンに関しては公式ドキュメントをご参照ください。
CronJobの仕組み
そもそもCronJobとは何か
まずはCronJobとは何かを簡単に説明します。CronJobは、Cronと同じフォーマットでいつジョブを実行するかを指定します。指定した時間になるとCronJobがジョブを実行するのではなく、CronJobはJobを生成し、そのJobはPodを生成することで、Podが任意のジョブを実行する仕組みです。
CronJob, Job, Podの守備範囲をはっきりさせておきましょう。
CronJob
- Cronフォーマットによる時間の管理
- 重複するジョブの制御など(詳細は後ほど)
- Jobのステータス管理
- Jobが正常に完了したかどうかをモニタリング
- 過去履歴の保持(成功/失敗それぞれ)
Job
- Podのコンフィグ管理
- Podのステータス管理
- 失敗時のリトライ有無
- 失敗時のタイムアウト時間
- 並行実行数
- "成功"と判定するために必要な完了数
Pod
- Jobが持つPodのコンフィグを継承、任意のイメージで任意のジョブを実行する(Deploymentのように継続実行ではなく、ジョブを終えるとexitすることが期待される)
パラメータの解説
CronJobに指定することのできるオプションを簡単に解説します。詳細は公式ドキュメント(https://kubernetes.io/docs/tasks/job/automated-tasks-with-cron-jobs/など)をご参照ください。
schedule (required)
.spec.scheduleは、先程「Cronフォーマットによる時間の管理」と表現した通りでCronと全く同じフォーマットが使われます。
例えば「5 4 * * *」とすれば毎日04:05に起動します。毎時0分に起動したい場合は「0 * * * *」でも良いですし「@hourly」と記載もできます。
startingDeadlineSeconds (optional)
.spec.startingDeadlineSecondsは、何らかの理由でscheduleに指定されて時刻になってもJobが起動出来なかった場合でも、何秒後までなら起動しても良いかを指定することができるオプションです。必須オプションではありませんが、個人的には必須オプションです。
このオプションは何らかの理由でJobを起動できなかった場合の起動保証のためだけに使うものではありません。
CronJobは、生成するJobが100回連続して失敗するとCronJob自体を再作成しない限り二度とJobを生成できなくなります。以下はCronJob Controllerからの引用です。
if len(starts) > 100 {
// We can't get the most recent times so just return an empty slice
return []time.Time{}, fmt.Errorf("too many missed start time (> 100). Set or decrease .spec.startingDeadlineSeconds or check clock skew")
}引用元: https://github.com/kubernetes/kubernetes/blob/release-1.19/pkg/controller/cronjob/utils.go#L142-L145
ここに先程「個人的には必須オプション」と述べた理由があります。
この100回の失敗とは、startingDeadlineSecondsの指定がない場合は期限なく100回連続の失敗でそのCronJobはJobを生成しなくなりますが、startingDeadlineSecondsの指定があると、この数値の間で100回連続で失敗していない限りはCronJobは指定時刻になるとJobを生成し続けます。つまり、startingDeadlineSeconds: 120としていると、過去120秒間に100回連続失敗していない限りはそのCronJobはJobを生成し続けます。
ちなみに、「なぜ100回なのか」についても同ソース中にコメントで触れられています。意訳ですが「毎時実行のCronJobが、金曜の午後(つまりエンジニアが家に帰る時間)から失敗し続け、三連休明けの火曜にエンジニアが帰ってきても100回には満たない回数(80回前後)なので停止されずに済むので、取り敢えず三連休でも問題ないよう100回にした」と記載があります。ただし、ゴールデンウィークや年末年始などの大型連休、または毎時ではなく30分毎としている場合など、この論理は簡単に崩れがちです。
引用元: https://github.com/kubernetes/kubernetes/blob/release-1.19/pkg/controller/cronjob/utils.go#L125-L141
concurrencyPolicy (optional)
.spec.concurrencyPolicyは並列稼働のためのポリシーです。省略可能です。
前回の起動時刻に起動したJobが次の起動時刻になってもなお稼働中の場合に、次のJobを生成して並列稼働にするのか、それとも生成しないのかを、制御することができます。
- Allow (default): 並列稼働を許容する
- Forbid: 並列稼働を許容しない。前回の起動時刻に起動したJobがRunning状態である場合、
startingDeadlineSecondsの設定次第で起動を取りやめる(詳細は後述) - Replace: 前回の起動時刻に起動したJobがRunning状態である場合、そのJobを停止して新たなJobを生成する
concurrencyPolicyのそれぞれのケースを毎時(@hourly)実行されるように指定したCronJobで説明します。便宜上、順番に生成されるJobをJob1, Job2, Job3と記載します。
Job1--->
Job2---->
Job3------->
---|-------------|-------------|-------------|--------------> t
04:00 05:00 06:00 07:00デフォルトであるconcurrencyPolicy: Allowの場合、並列稼働を許容するため、Jobが次の起動時刻に起動していても次のJob(Job2)は起動されます。
Job1------------------->
Job2------->
Job3------->
---|-------------|-------------|-------------|--------------> t
04:00 05:00 06:00 07:00concurrencyPolicy: Forbidの場合、並列稼働は行われません。最初のJobが起動中の場合、次のJob(Job2)は起動を諦めます。
ただし、startingDeadlineSecondsで指定した時間中に前回のJobが完了すると、次のJobは起動することに注意します。
Job1------------------->
Job2 X
Job3------->
---|-------------|-------------|-------------|--------------> t
04:00 05:00 06:00 07:00concurrencyPolicy: Replaceの場合、前回起動しているJobがあるとそれを停止し次のJobが起動されます。
Job1--------->(DELETE)
Job2----->
Job3------->
---|-------------|-------------|-------------|--------------> t
04:00 05:00 06:00 07:00successfulJobsHistoryLimit, failedJobsHistoryLimit (optional)
先述の通り、CronJobはJobを生成します。Jobはkubectl get jobによって一覧を取得することができますが、.spec.successfulJobsHistoryLimit, .spec.failedJobsHistoryLimitは終了したJobをいくつ残すかを決定します。successfulJobsHistoryLimitは正常終了したJobを指し、failedJobsHistoryLimitは失敗終了したJobを指します。Jobが残るということはPodも残るので、特に失敗したJobからPodを特定しログを見ることで失敗原因を掴むことができます。ちなみにCronJobから生成されたJob名はエポックタイムが末尾に付くので、いつ起動されたかをJob名から特定可能です。(Job名がcronjob-test-1586444400であれば2020-04-09 15:00:00に起動したと分かります)
デフォルトではそれぞれ3, 1が設定されています。間隔が短いCronJobはどんどん履歴が消えていくので、特にfailedJobsHistoryLimitをデフォルトから伸ばし、失敗原因を特定できるようにすると良いでしょう。
suspend (optional)
.spec.suspendをtrueに指定すると、CronJobを一時的に停止することができます。一時的なメンテナンスなどでCronJobがJobを生成するのを避けたい場合に使います。
注意点が2つあります。
まず、suspendは内部的には失敗と捉えられるため、これをtrueにしてから100回スケジュールされる時間が経つと、CronJobはJobを生成できなくなるためCronJobの再作成が必要になります。ただし、startingDeadlineSecondsが設定されていると、その時間内での失敗回数のみをウォッチするようになるため、CronJobが停止することを防ぐことができる場合があります。こうした意味でも、必ずstartingDeadlineSecondsを設定するようにしてください。(例えばsuspendしてから100000回失敗し続けていても、startingDeadlineSeconds: 100とした上でそのCronJobが毎時実行であればstartingDeadlineSeconds中に100回カウントされないので、そのCronJobは停止しません)
2つ目の注意点は、suspendをtrueからfalseに切り替えた時、scheduleで指定した時刻からstartingDeadlineSecondsの時間内であると即座にJobが生成されることです。
suspendをtrueにするのは簡単です。RBACを持ちkubectl edit cronjob <CRONJOB>をすれば簡単に変更できます。ただ、falseにする際にはこれらの注意点が伴うため、trueからfalseにする際にはCronJobを再作成するオペレーションとすると良いかもしれません。
jobTemplate (required)
.spec.jobTemplateはJobのコンフィグを指定します。Jobの.spec配下を記載します。Jobの詳細は以下の公式ドキュメントをご参照ください。
https://kubernetes.io/docs/concepts/workloads/controllers/job/#writing-a-job-spec
CronJobがJobを作るまでの流れ
CronJob自体もいくつかのコンポーネントによって動作しているので、簡単に紹介します。
まず、Kubernetesにはkube-controller-managerという仕組みがあります。これの一部がCronJob Controller(ソース中では"CronJob Manager"と呼ばれることもあります)としてCronJobを管理しています。(kube-controller-managerにCronJobのControllerのエントリ関数があります: https://github.com/kubernetes/kubernetes/blob/release-1.19/cmd/kube-controller-manager/app/batch.go#L45)
続いて、CronJob Controllerが呼ばれるのですが、jobTemplate以外の範囲をCronJob Controllerが担当し、Jobの作成をJob Controllerに任せるようにしています。
https://github.com/kubernetes/kubernetes/blob/release-1.19/pkg/controller/cronjob/cronjob_controller.go
よって、Kubernetes resourceとしてCronJob → Job → Podという関係性がありますが、管理層に関してはkube-controller-manager → CronJob Controller → Job Controller → kube-scheduler(Podを作成)という関係性であることが分かります。
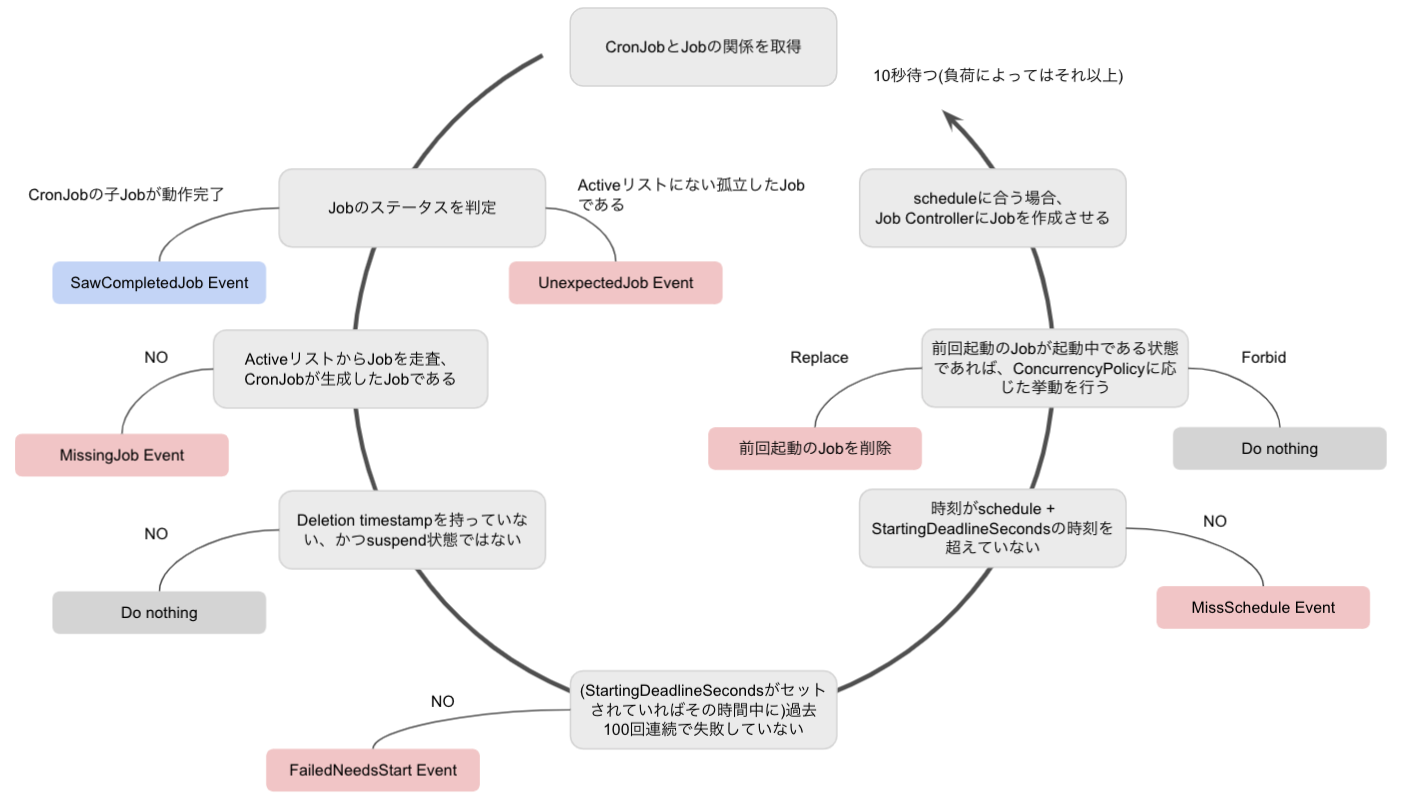
さて、各パラメータの復習も兼ねて、CronJobがJobを生成するまでの流れを簡単に記載します。
- 10秒毎(*)に以下を処理していく
(* ソース中コメントはevery 10 secondsと書いてありますが、全ての処理が終わる毎に10秒待つので、CronJobが大量にある環境など処理が追いつかないケースでは10秒毎とは言えないことに注意します) - すべてのCronJobから生成されたJobとCronJobオブジェクトをAPI Serverから取得
- JobがCronJobのActiveリスト(既に実行済みのJobが入っています)に存在するかどうかを判定
- i. 存在していない、かつ完了もしていなければ
UnexpectedJobEventを発生 - ii. 存在していて、かつ完了済みであれば
SawCompletedJobEventを発生
- i. 存在していない、かつ完了もしていなければ
- CronJobが生成したJobではないJobがActiveリストにあるかを判定し、もしあれば
MissingJobEventを発生させ、そのJobをActiveリストから削除 - DeletionTimestampを持っている(つまり削除される間際の)CronJobまたはSuspendされているCronJobには何もしない
- 100回連続で失敗している場合などに
FailedNeedsStartEventを発生 StartingDeadlineSecondsがセットされていて、かつその時刻を超えている場合はMissScheduleEventを発生- 前回起動したJobが次の起動時刻になっても稼働している場合、
ConcurrencyPolicyの設定内容に応じて以下を実行(Allowの場合は次へ進みます)- i. Forbid: 前回起動したJobがActiveリストにいる場合は何もせずに終了
- ii. Replace: 前回起動したJobがActiveリストにいる場合はそのJobを削除し次へ
- Jobを作成するため、
jobTemplateをJob Conrtollerに渡す
メルペイでは何に困っていた?
過去、弊社で困っていたことと、その解決方法をいくつか紹介したいと思います。
suspend: trueにしていたCronJobがsuspend: falseにした後もJobを生成しない
事象
数日間に渡ってCronJobを停止しないといけなくなったため、suspend: trueに設定した。数日後、それを再開するためsuspend: falseにしたが、CronJobは二度とJobを生成しなかった。
原因と解決方法
前述のとおり、CronJobは100回の連続失敗による停止という仕様を持ちます。今回の原因はstartingDeadlineSecondsを指定していないまま、数日間のsuspend: trueによって100回の失敗が記録されたことでした。(suspendによる起動の抑制は内部では失敗とみなされています)
一度この状態になるとCronJobは再作成しないと正常に戻りません。
よって、このケースはstartingDeadlineSecondsを指定し再作成することで、回避することができます。
(GKE特有) NodeがCluster Autoscalerによって停止されると、そのNodeで稼働していたJob(Pod)のEvictをCronJobが正常終了したと誤認識しconcurrencyPolicy: Forbid(Replace)なのに並列稼働した
Googke Kubernetes Engine(GKE)特有のケースかと思います。
事象
オートスケールを有効にしたGKEのNode Poolを使っている環境で、あるconcurrencyPolicy: Replaceが設定されているCronJobに管理されているJobが生成したPodがNodeのオートスケールインによって別Nodeにevictされると、CronJobがそのJobに対してSawCompletedJob Eventを発生させた(つまり、Jobはジョブが強制終了されたと認識しているのに、CronJobには正常にジョブが完了したとみなされてしまった)。evictされたPodはJobによって別Nodeで動き出し、さらに次のschedule時刻に達すると別Jobが生成されて並行稼動してしまい、Jobがスタックした。
原因と解決方法
GKE特有のはずなので稀なケースかと思いますが、オートスケールを有効にしているGKE Node Poolで発生する可能性があります。これは2020/09/07現在、バグとして認識されているため、いつか修正されると信じています。
オートスケールが有効な場合、Nodeの稼働率が低くなるとCluster Autoscalerによってスケールイン(あるNodeが停止)しますが、停止するNode上で稼働していたPodは、evictされた後に上位リソース(ReplicaSet, Jobなど)によって別のNodeにて再作成されます。しかし、この際にCronJobはJobの停止を正常終了したことを指すSawCompletedJob Eventによって、Jobの管理を止めてしまいます。ただ、その孤立状態になったJobはその下位リソースであるPodが正常終了していないことを知っているので別Nodeにevictさせるという矛盾が生じるため、concurrencyPolicy: Replaceであっても、次の起動時刻になるとさらにJobを生成し並列稼働する可能性があります。
CronJob Controller: Now the Job1 has been successfully completed, lets create the next(Job2)
↓
Job1--->(evict,recreate)-------->
Job2-----------------> (stack!!)
---|-------------|------------------------------------------> t
04:00 05:00解決方法は、オートスケールを発生させないことです。
Pod Annotionにcluster-autoscaler.kubernetes.io/safe-to-evict: "false"を指定します。CronJobで指定するには.spec.jobTemplate.spec.template.metadata.annotationに指定します。
このAnnotationを持つPodはPodDisruptionBudget(PDB)でminAvailable: 100%が指定してあることと同じ意味を持つため、稼働中のそのPodを持つNodeはスケールインの対象になりません。
ただ、一般的なPDBの設定の理論と同様に、無闇にこれを設定することは勧めません。なぜなら、この設定を持つPodで溢れるとオートスケールインは全く働かなくなり、コストダウンが望めません。そもそもcontainerizedな環境では冪等性を担保し、並列稼働しても問題なく作られていることが理想です。
ユースケース毎にCronJobの設定をする
最後に、いくつか特徴的なユースケースがあったので、それらを紹介します。おまけパートとしてご参照ください。
Timezone UTCな環境で毎月1日0:00(JST)に実行したい
GKEユーザなど、Kubernetesのマネージドサービスを利用する場合、kube-controller-managerはUTCで動作します。ただ、日本でサービスを行っていると、他社依存の機能やレポーティングなどで、どうしても毎月1日 0:00 JSTにJobを実行したくなるケースがあります。
そこで、愚直ではありますが、CronJobをJSTで月初になる可能性のある毎月28~31日 UTCに起動するようにします。ここでは、一番ヒトに優しくないBusybox dateでの例を記載しますが、明日(1日後)の日付を取得し○月1日の場合にだけ任意のコマンドを実行するようにしています。(Unix Timeで1日後を作り、エポックタイムに足すことで明日を表現。厳密に行うにはUTC-JSTの差分である9時間としてください)
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: beginning-of-month
spec:
schedule: "0 15 28-31 * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: beginning-of-month
command:
- "sh"
- "-c"
- |
if [ $(date +'%d' -d 1970.01.01-00:00:$(( $( date +%s ) + $(( 24 * 60 * 60 )) ))) -eq 1 ]; then
<COMMAND>
else
echo Skip today because it is not the beginning of the month
fi長時間のバッチなのでPreemptible Nodeで動かしたくない(Anti Node Affinity)
CronJobの主旨とは外れますが、CronJobはJobのコンフィグを持つことができ、JobはPodのコンフィグを持つことが出来るので、一般的なPod同様にAnti Node Affinityを指定することができるという紹介です。メルペイでは機械学習のモデリングなど長時間かかるCronJobをPreemptible Node(安価であるが、24h以上は稼働できないNode)で稼働されることを避けるために指定しています。(弊社では、他にもそのチーム専用のNode Poolを設けることでも対処していますが割愛します)
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: anti-node-affinity
spec:
schedule: "10 15 * * *"
jobTemplate:
spec:
template:
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: cloud.google.com/gke-preemptible
operator: DoesNotExist
containers:
...おわりに
Kubernetes CronJobについて解説しました。
CronJobはCron同様にスケジュールを設定できる他にも、並列稼働、時間外の実行やリトライ(Jobの機能)まで対応しています。
いくつかの落とし穴がありますが、明確な回避策がありますので、理解した上で利用していくとCronJobとうまく付き合っていけると思います。




