はじめに
現在メルカリでは CoreDB と呼ばれる巨大な MySQL を TiDB に移行しています[^1]. この記事内でも紹介されていますが, 私たちは移行するために MySQL と TiDB を DM というツールで差分同期を行っています. 本記事ではこの DM を利用しつつ DDL(Data Definition Language) をどの様に実行しているかについて紹介します.
メルカリでの MySQL への DDL 実行
まず, メルカリにおける MySQL への DDL 実行は下記の通り場合分けして実行しています:
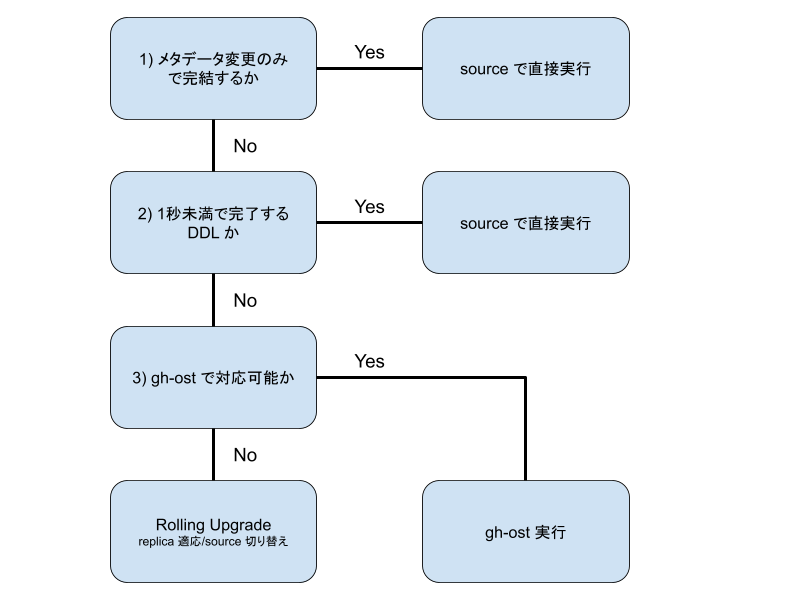
それぞれの条件について簡単に解説しますが, 基本的に source – replica の replication 遅延を最小限に抑えるために場合分けしています.
メタデータのみの変更
まず最初の条件は「メタデータのみの変更かどうか」です. これは Online DDL[^2] のページで [In Place] & ![Rebuilds Table] & [Permit Concurrent DML] & [Only Modifies Metadata] なものが該当します. 例えば Table 名の変更や Column の default 値の変更, ENUM の追加[^3] などです. これはテーブルの再構築などが不要で一瞬で完了するためそのまま source 側で実行します.
metadata のみの変更でも注意すること
metadata のみの変更とはいえ注意すべきこと, それは DDL とクエリのロック競合です. 公式ドキュメント[^4]にあるとおり MySQL では table へのアクセス/変更時に一貫性を保証するために metadata lock を取得しますが, この metadata lock が DDL とアプリケーションが発行するクエリで競合し意図しない影響を及ぼす可能性があります:
-- session 1
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM foo;
Empty set (0.00 sec)
-- // このまま transaction を保持したままにする
-- session 2
mysql> ALTER TABLE foo ALTER COLUMN id SET DEFAULT 0, ALGORITHM=INSTANT;
-- // metadata のみの変更にもかかわらず実行がブロックされる
-- session 3
mysql> SELECT * FROM foo;
-- // DDL の後続のクエリも待たされるこのように session 2 移行の同一テーブルへのアクセスがブロックされていますが, ここで processlist と metadata lock の関係を見てみます:
mysql> SELECT
-> t.PROCESSLIST_ID AS process_id,
-> t.PROCESSLIST_USER AS user,
-> t.PROCESSLIST_DB AS db,
-> t.PROCESSLIST_TIME AS time,
-> t.PROCESSLIST_STATE AS state,
-> t.PROCESSLIST_INFO AS query,
-> ml.LOCK_TYPE,
-> ml.LOCK_DURATION,
-> ml.LOCK_STATUS
-> FROM performance_schema.metadata_locks ml
-> JOIN performance_schema.threads t
-> ON ml.OWNER_THREAD_ID = t.THREAD_ID
-> WHERE ml.OBJECT_TYPE = 'TABLE'
-> AND ml.OBJECT_SCHEMA = 'test'
-> AND ml.OBJECT_NAME = 'foo'
-> AND t.PROCESSLIST_ID IS NOT NULL
-> ORDER BY ml.LOCK_STATUS, process_id;
+------------+------+------+------+---------------------------------+------------------------------------------------------------------+-------------------+---------------+-------------+
| process_id | user | db | time | state | query | LOCK_TYPE | LOCK_DURATION | LOCK_STATUS |
+------------+------+------+------+---------------------------------+------------------------------------------------------------------+-------------------+---------------+-------------+
| 8 | root | test | 516 | NULL | NULL | SHARED_READ | TRANSACTION | GRANTED |
| 9 | root | test | 514 | Waiting for table metadata lock | alter table foo alter column id set default 0, ALGORITHM=INSTANT | SHARED_UPGRADABLE | TRANSACTION | GRANTED |
| 9 | root | test | 514 | Waiting for table metadata lock | alter table foo alter column id set default 0, ALGORITHM=INSTANT | EXCLUSIVE | TRANSACTION | PENDING |
| 16 | root | test | 512 | Waiting for table metadata lock | SELECT * FROM foo | SHARED_READ | TRANSACTION | PENDING |
+------------+------+------+------+---------------------------------+------------------------------------------------------------------+-------------------+---------------+-------------+この様に DDL(id=9)が Exclusive lock を取ろうとして親の transaction(id=8)を待っていて, DDL の後続(id=16)が更に待たされている事がわかります. これを避けるために, たとえ metadata lock のものであっても下記のように lock_wait_timeout を十分短い値に指定することでこの例の後続のクエリになるべく影響を与えない様に実行することが重要です. 例えばここでは 5s に設定した場合のそれぞれの挙動を確認します:
-- session 1
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM foo;
Empty set (0.02 sec)
-- session 2
mysql> SET SESSION lock_wait_timeout=5;
mysql> SELECT NOW(); ALTER TABLE foo ALTER COLUMN id SET DEFAULT 0, ALGORITHM=INSTANT; SELECT NOW();
+---------------------+
| NOW() |
+---------------------+
| 2026-03-05 01:59:32 |
+---------------------+
1 row in set (0.01 sec)
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
+---------------------+
| NOW() |
+---------------------+
| 2026-03-05 01:59:37 |
+---------------------+
1 row in set (0.00 sec)
-- session 3
mysql> SELECT NOW(); SELECT * FROM foo; SELECT NOW();
+---------------------+
| NOW() |
+---------------------+
| 2026-03-05 01:59:34 |
+---------------------+
1 row in set (0.01 sec)
Empty set (3.03 sec)
+---------------------+
| NOW() |
+---------------------+
| 2026-03-05 01:59:37 |
+---------------------+
1 row in set (0.00 sec)1秒未満で完了するか
続いての条件は「1秒未満で完了するかどうか」です. これについては具体的なケースを紹介することは難しいのですが, 例えば CREATE TABLE 文, 空もしくは十分少ないレコード数に対するメタデータの変更で完結しない DDL[^5] などがこれに当たります. ここでなぜ「1秒未満」という条件を付与しているかについてですが, MySQL の DDL はたとえ online としても replication を構成しているときには下記の制限があります[^6]:
Long running online DDL operations can cause replication lag. An online DDL operation must finish running on the source before it is run on the replica. Also, DML that was processed concurrently on the source is only processed on the replica after the DDL operation on the replica is completed.online DDL としても replica で実行される前に source で完了している必要があり, また source で並行で実行されている DML は replica での DDL が完了した後に実行されます. つまり, source で並行実行されている DML は replica では DDL が完了するまでブロックされるということです. これは source 側で(online) DDL による source 側の table definition の変更と並行実行されている DML の対応が replica 側でも同様にして再現される必要があります. そのため replica 側でも table defintion の変更と DML の整合性を担保するためにこのような仕組みとなっています.
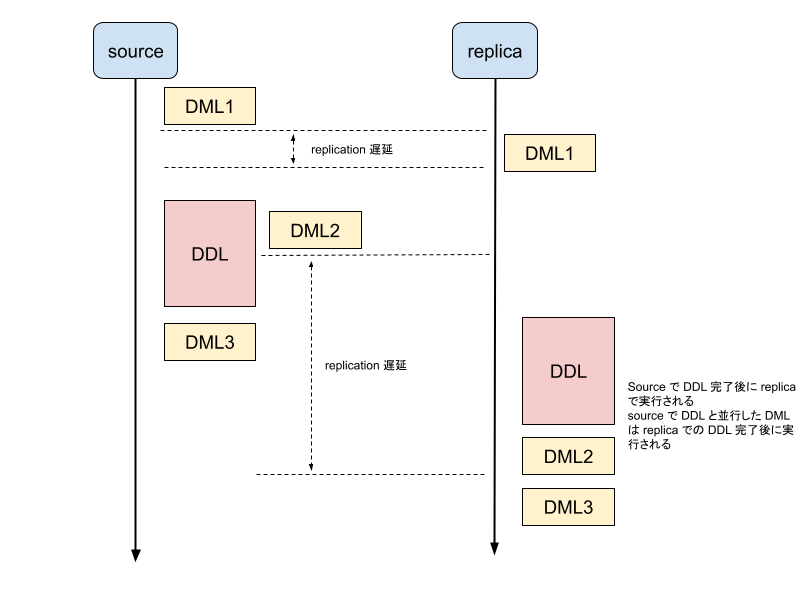
冒頭の記事のようにメルカリのデータサイズは非常に巨大で中には DDL 完了に1日以上かかるものもあり, そのようなテーブルへの DDL による replication 遅延を防ぐために, 基本的に即座に終わらない DDL はそのまま実行しないようにしています. 実際に DDL が 1s 未満で完了するかどうかは経験則に基づくことが多いですが, 例えばサービスで稼働していないホストで SET sql_log_bin=0 を実行してバイナリログに出力しないようにして実測するなどで計測可能です.
また, DDL 自体が 1s 未満で完了するとしても先の metadata lock による影響は考慮する必要があるため, この場合も同様に lock_wait_timeout を調整する必要があります.
gh-ost で対応可能か
時間のかかる DDL を実行する場合, メルカリでは gh-ost を採用しています. gh-ost を利用できるかどうかについてはリソース的な制限(テーブルコピーを伴うため余剰なディスクサイズが必要, 通常の更新と gh-ost による backfill/差分同期による replication 遅延影響)や機能的な制限(UNIQUE KEY の一部に ENUM が含まれる場合の性能劣化[^7])がない限り gh-ost を利用しており, DDL 実行オペレーションで最も数の多いケースです. もしそれらを満たさない場合には Rolling Upgrade, つまり全 replica に対して DDL を実行し最後に source を切り替えるといったことを行います.
なぜ ENUM を含む場合に性能劣化するのか
MySQL の公式ドキュメントによると ENUM は文字列順ではなく内部 index 順でソートされますが, これは Go 言語[^8]の文字列によるハンドリングと異なります. この ENUM の取り扱いの不一致による iteration 時のデータ欠損を避けるために, gh-ost では UNIQUE KEY に ENUM が含まれる場合には CONCAT(...) により明示的な文字列として取り扱われます[^9]. この時, ORDER BY CONCAT(...) ASC が実行されることになり結果として iteration のたびに Creating Sort Index が発生し性能, 負荷ともに劣化する可能性があります.
DM を用いた DDL 実行
ここから TiDB の話に移ります. 前述の通りメルカリでは移行に伴う停止時間をなるべく短くするために DM を用いて MySQL と TiDB で差分同期をしつつ切り替えを進めています:
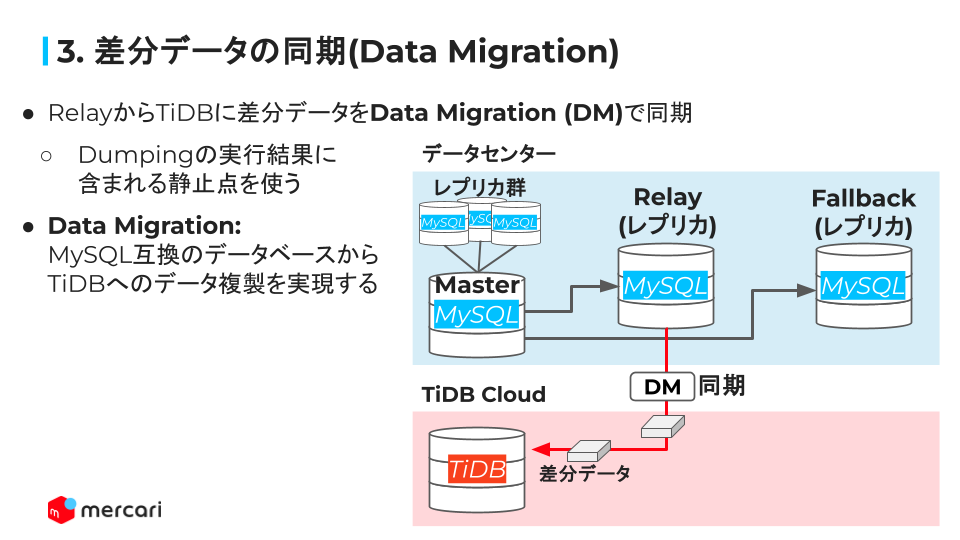
この時, 前述の条件 3 の場合にどのような挙動になるかを考えてみます. こちらのドキュメントの通り, DM には online-ddl というフラグがあり pt-osc や gh-ost といった online migration tool のユースケースをカバーしています. ここからは gh-ost を例にして説明していきます.
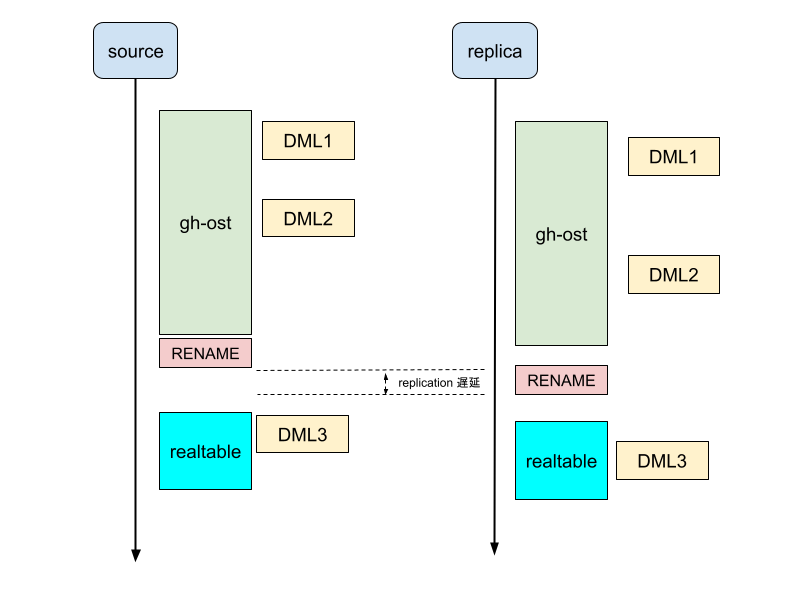
まず, gh-ost で test database の foo table に DDL が適応される流れについて説明します:
- メタデータテーブル(ghc) を作成
Create /* gh-ost */ table test._foo_ghc
- realtable をもとに切り替え後のテーブル(gho)を作成
Create /* gh-ost */ table test._foo_gho like test.foo
- gho に DDL の適応
ALTER /* gh-ost */ table test._foo_gho ...
- realtable から gho への backfill
- backfill 完了後 realtable から gho への差分同期
- 差分同期完了後 RENAME 文を使って cutover
RENABLE TABLE foo TO _foo_del, _foo_gho TO foo
このフローで online-ddl が有効化されている場合に DM はどのような挙動になるでしょうか.
メタデータテーブル(ghc) を作成DM は ghc テーブルを作成しないrealtable をもとに切り替え後のテーブル(gho)を作成DM は gho テーブルを作成しない, その代わりにメタデータテーブルdm_meta.{task_name}_onlineddlを初期化するDELETE FROM dm_meta.{task_name}_onlineddl WHERE id = {server_id} and ghost_schema = {ghost_schema} and ghost_table = {ghost_table};
gho に DDL の適応DM が実行される DDL をメタデータテーブルdm_meta.{task_name}_onlineddlに保存する- この DDL は後に利用される
realtable から gho への backfillDM は realtable への更新のみ TiDB に同期する- gho への更新はすべて破棄される
backfill 完了後 realtable から gho への差分同期4 と同様に realtable への更新のみ同期差分同期完了後 RENAME 文を使って cutoverDM は cutover の RENAME 文を分割し, gho table から realtable への RENAME 実行の際に下記を実施する- 3 で保存した DDL を取得
- DDL の gho を realtable に置換
- 置換された DDL を実行
ALTER table test.foo ...;
このようにして DM は OnlineDDL ツールを利用する際に realtable から gho への同期に伴う処理を削減しています(online-ddl=false を指定した場合は通常通り gho/ghc などが作成される).
まとめると下記のようになります:

| MySQL | TiDB |
|---|---|
| メタデータテーブル(ghc) を作成 | ghc テーブルは作成しない |
| realtable をもとに切り替え後のテーブル(gho)を作成 | gho テーブルは作成せず DM のメタデータテーブルを初期化 |
| gho に DDL の適応 | 実行予定の DDL をメタデータテーブルに保存 |
| realtable から gho への backfill | realtable への更新のみ TiDB に同期 |
| backfill 完了後 realtable から gho への差分同期 | realtable への更新のみ TiDB に同期 |
| 差分同期完了後 RENAME 文を使って cutover | RENAME 文を分割し保存していた DDL を実際に realtable に対して実行 |
gh-ost 利用時の DM の挙動の比較
DDL 実行時のトラブル
メルカリでは online-ddl=true & gh-ost による DDL 実行で運用しており, 特に大きな問題もなく運用できていました. しかしある時の DDL 実行で問題が発生します. その問題とは DM の replication lag が通常 1~2s 未満だったものが突如 1h 以上遅延するという事象でした.
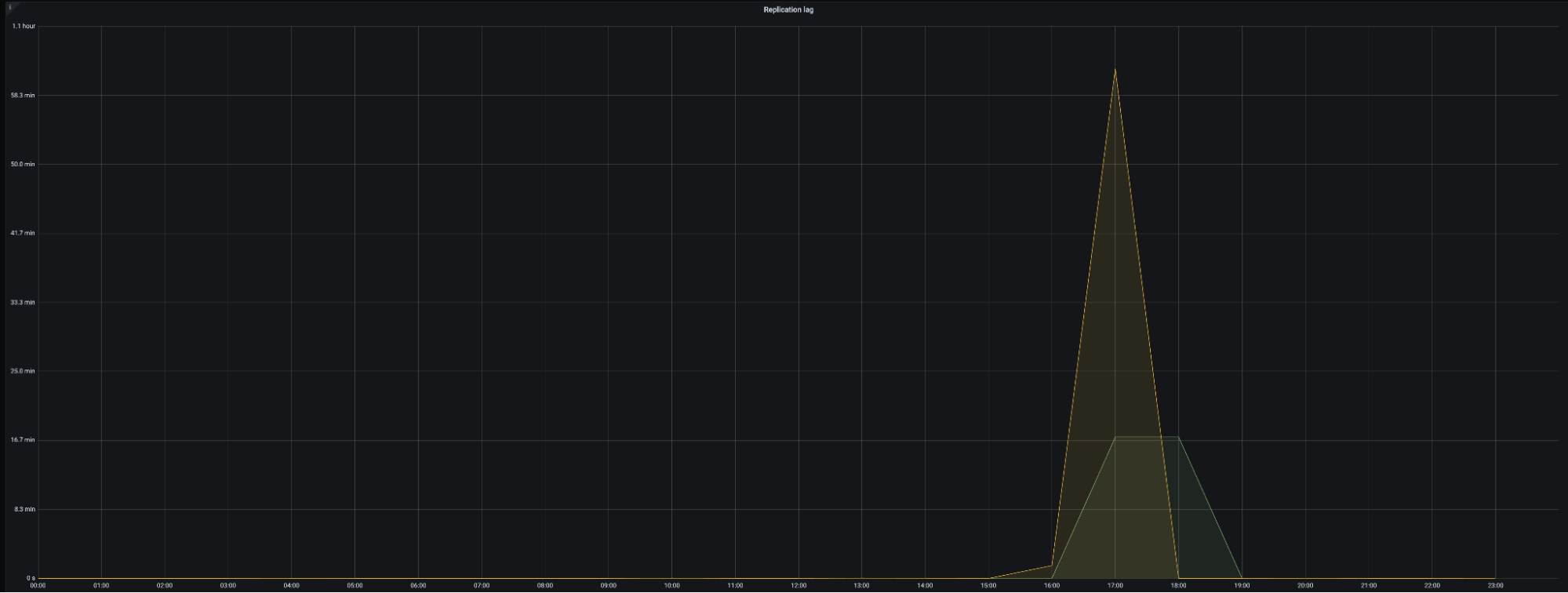
DM の status は RUNNING にも関わらずこの様に Replication QPS(DM syncer の完了した Job 数)が 16:00 頃から 0 になっており, DML が何も実行されなくなっていました:
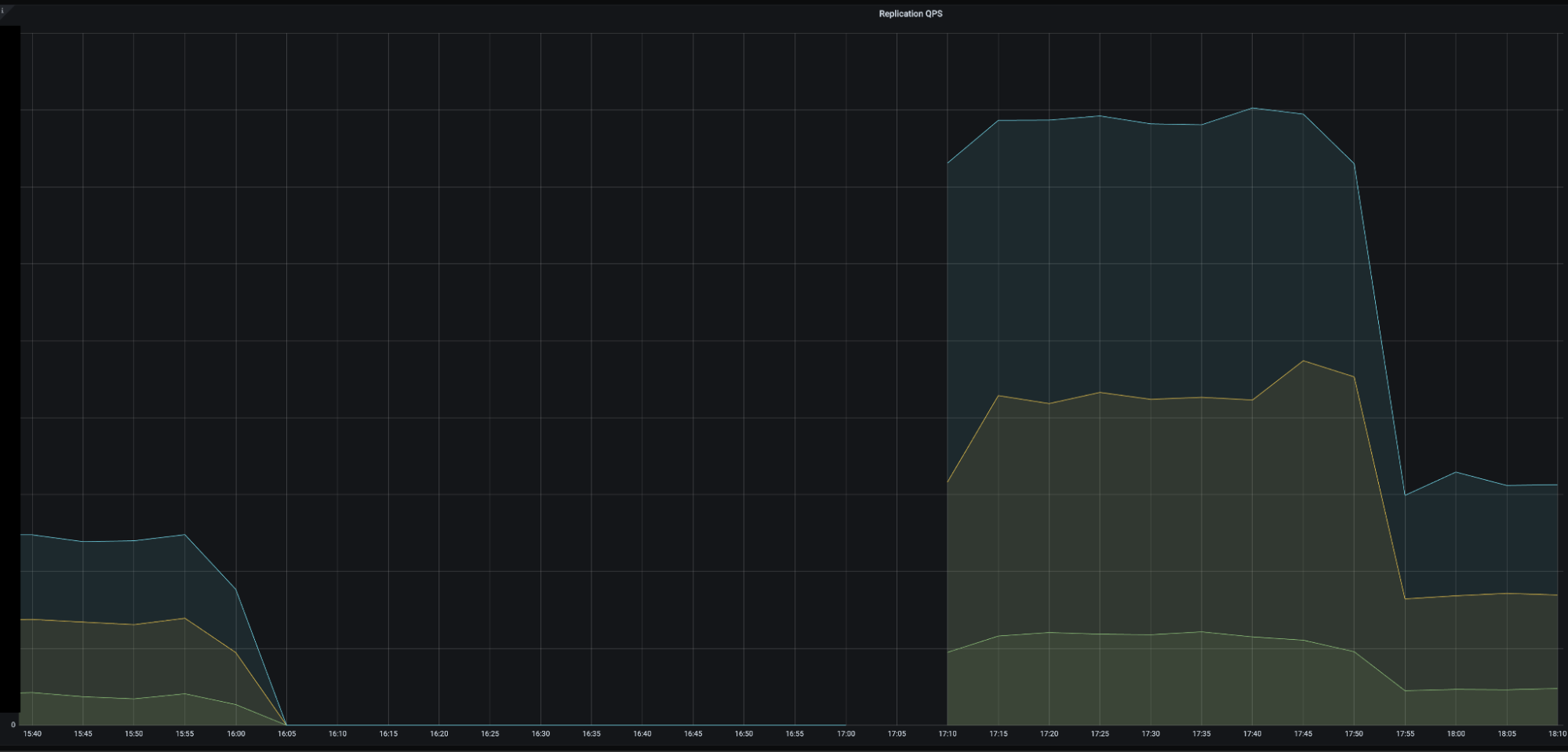
TiDB のサポートチームとともに調査したところ, この QPS が停止したタイミングで下記の DDL が実行されていたことがわかりました.
ALTER TABLE `mercari`.`foo` MODIFY COLUMN `bar_id` int(10) UNSIGNED NOT NULL;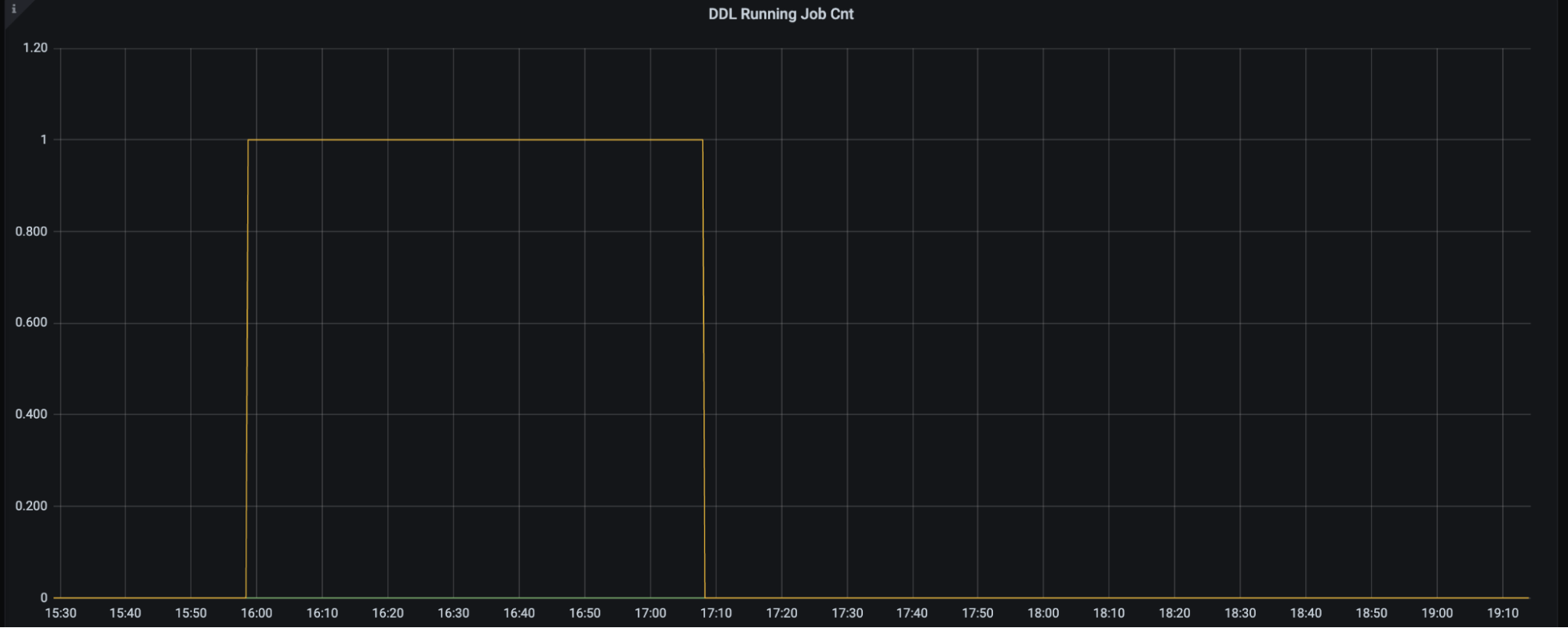
この DDL は先の MySQL における DDL 実行パターンにおいて gh-ost を利用するものであったため, 先で紹介した cutover(RENAME TABLE) 実行時に ALTER が実行されておりこの DDL により DM の遅延が発生していることがわかりました.
原因はわかりましたが, なぜ DM が遅延したのでしょうか. これは先に紹介した Online DDL の replica で実行される制限と同じ理由で, TiDB が直接 MySQL の binlog を読めないため DM が先の source/replica での table defnition と DML の整合性担保を保証するための仕組みとなっています. では v8.5.3 を例に実際にコードの中をみてみましょう[^10]:
// dm/syncer/syncer.go#L713
func (s *Syncer) Process(ctx context.Context, pr chan pb.ProcessResult) {
// ...
err := s.Run(newCtx)
if err != nil {
// returned error rather than sent to runFatalChan
// cancel goroutines created in s.Run
cancel()
}
// ...
}
// dm/syncer/syncer.go#L1741
func (s *Syncer) Run(ctx context.Context) (err error) {
// ...
s.runWg.Add(1)
go s.syncDML()
s.runWg.Add(1)
go func() {
defer s.runWg.Done()
// also need to use a different ctx. checkpointFlushWorker worker will be closed in the first defer
s.checkpointFlushWorker.Run(s.tctx)
}()
s.runWg.Add(1)
go s.syncDDL(adminQueueName, s.ddlDBConn, s.ddlJobCh)
// ...
}
// dm/syncer/syncer.go#L1419
func (s *Syncer) syncDDL(queueBucket string, db *dbconn.DBConn, ddlJobChan chan *job) {
defer s.runWg.Done()
var err error
for {
ddlJob, ok := <-ddlJobChan
if !ok {
return
}
// ...
if !ignore {
// ...
affected, err = db.ExecuteSQLWithIgnore(s.syncCtx, s.metricsProxies, errorutil.IsIgnorableMySQLDDLError, ddlJob.ddls)
// ...
}
}
}
// dm/syncer/ddl.go#L221
func (ddl *DDLWorker) HandleQueryEvent(ev *replication.QueryEvent, ec eventContext, originSQL string) (err error) {
// ...
if err = ddl.flushJobs(); err != nil {
return err
}
return ddl.strategy.handleDDL(qec)
}
// dm/syncer/syncer.go#L3210
func (s *Syncer) flushJobs() error {
flushJobSeq := s.getFlushSeq()
s.tctx.L().Info("flush all jobs", zap.Stringer("global checkpoint", s.checkpoint), zap.Int64("flush job seq", flushJobSeq))
job := newFlushJob(s.cfg.WorkerCount, flushJobSeq)
_, err := s.handleJobFunc(job)
return err
}
// dm/syncer/syncer.go#L1115
func (s *Syncer) handleJob(job *job) (added2Queue bool, err error) {
// ...
s.addJob(job)
// ...
}
// dm/syncer/syncer.go#L1016
func (s *Syncer) addJob(job *job) {
// ...
tp := job.tp
switch tp {
case flush:
s.jobWg.Add(1)
s.dmlJobCh <- job
case ddl:
s.updateJobMetrics(false, adminQueueName, job)
s.jobWg.Add(1)
startTime := time.Now()
s.ddlJobCh <- job
s.metricsProxies.AddJobDurationHistogram.WithLabelValues("ddl", s.cfg.Name, adminQueueName, s.cfg.SourceID).Observe(time.Since(startTime).Seconds())
// ...
}
}
// dm/syncer/syncer.go#L1617
func (s *Syncer) syncDML() {
defer s.runWg.Done()
dmlJobCh := s.dmlJobCh
if s.cfg.Compact {
dmlJobCh = compactorWrap(dmlJobCh, s)
}
causalityCh := causalityWrap(dmlJobCh, s)
flushCh := dmlWorkerWrap(causalityCh, s)
for range flushCh {
s.jobWg.Done()
}
}
// dm/syncer/syncer.go#L1419
func (s *Syncer) syncDDL(queueBucket string, db *dbconn.DBConn, ddlJobChan chan *job) {
defer s.runWg.Done()
var err error
for {
ddlJob, ok := <-ddlJobChan
if !ok {
return
}
// ...
if !ignore {
// ...
affected, err = db.ExecuteSQLWithIgnore(s.syncCtx, s.metricsProxies, errorutil.IsIgnorableMySQLDDLError, ddlJob.ddls)
// ...
}
}
}この部分で binlog から DDL イベントが来たときに, まず DML の flush を行います. これは DML queue に入っている DML を一度すべて下流(TiDB)にて実行するため, s.jobWg.Wait() それらの完了を待機します.
その後 DDL job を DDL queue に投入し, 再び s.jobWg.Wait() で下流(TiDB)で DDL 実行が完了するまで待機します.
この DDL による wait で待機している間 binlog イベント処理ループはブロックされるため, DDL が完了するまで DM は後続のイベントを処理しないということになります.
online-ddl=true 設定時に gh-ost を利用した DDL の実行は下記のようになります:
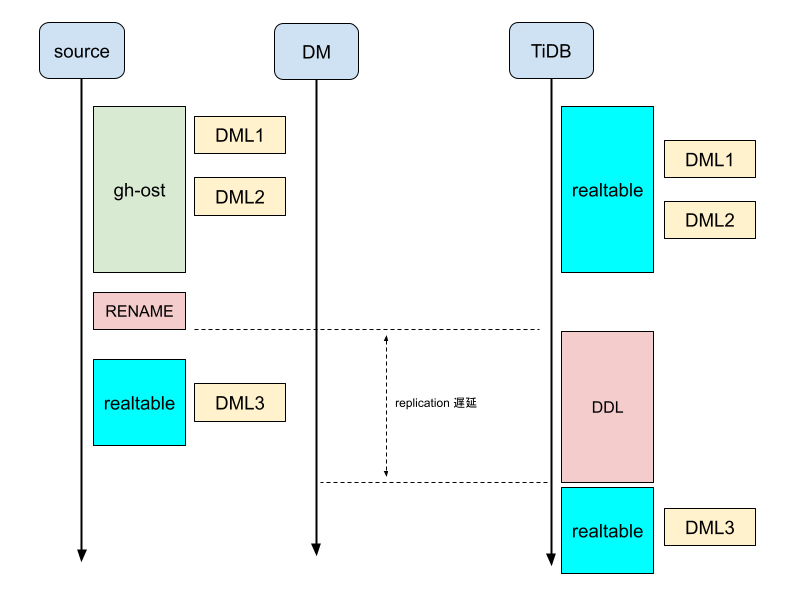
この様に gh-ost の cut-over(RENAME) 実行時に downstream 側で実際の DDL が発行されそれが完了するまで DML はブロックされるため, DDL が完了するまで replication が遅延することになります.
DM を利用しつつ安全に DDL を実行するには
この様に online-ddl は gh-ost など online schema change tool の利用時に同期に必要な無駄を削減させるためのものなため, 指定したとしても下流(TiDB)での DDL の実行完了を待つ必要があります. これは冒頭の無停止で段階的に移行していく際にいくつか問題がある場合があります. MySQL から TiDB へ移行する際にはサービスへの影響が少ないもの(分析基盤のための CDC など)から読み込みを移行させていきますが, これらの中には大きな遅延が許容できないものもあるため, 数時間実行にかかる DDL は影響を与える可能性があります. 一方でメルカリのデータベースはいずれも巨大であり TiDB Dumpling や TiDB Lightning による export/import でも数日以上かかり, DDL 実行のために DM を停止, つまり TiDB Cluster を再作成するというオペレーションも現実的ではありません. そのため, メルカリでは下記のように DDL の実行方法をケース分けしています:
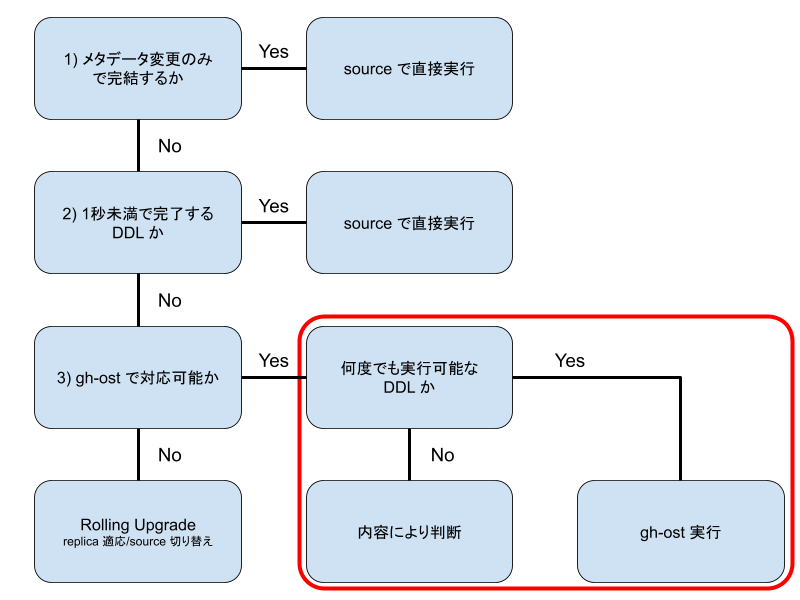
先の紹介のように online-ddl を有効化すると MySQL 上で cutover(RENAME TABLE) されたタイミングで TiDB 側で DDL が実行されます. 仮にこの DDL が例えば MODIFY COLUMN のように何度でも実行可能な場合は, 先に TiDB 側のみ DDL を実行しておいて gh-ost をすることで2回目の(実質意味がない) DDL では即座に終了するため, 実際の DDL が長時間でも DM の遅延を最小に抑えることが可能です. 前のブログにあるようなレコード数が多くさらに INDEX で多数利用されているような column に対する MODIFY COLUMN などには有用と言えます. それ以外の場合(例えば INDEX 追加など)は実行時間やビジネス要件によってかわりますが, 遅延を許容して gh-ost を実行する, Binlog Event Filter により該当の DDL だけ除外するなど対応が考えられます.
まとめ
今回は DM で MySQL と TiDB を同期しているときに DDL をなるべく安全に実行する方法を紹介しました. DM を利用する際に参考にしていただけると幸いです. 現在メルカリでは DBRE の EM を募集しています, 詳しくはこちらをご覧ください.
[^1]: ref: https://pingcap.co.jp/case-study/mercari-tidb-cloud/
[^2]: ref: https://dev.mysql.com/doc/refman/8.4/en/innodb-online-ddl-operations.html
[^3]: 末尾追加かつ要素の個数が byte を跨がない場合のみ該当
[^4]: ref: https://dev.mysql.com/doc/refman/8.4/en/metadata-locking.html
[^5]: 例えば INDEX や column の操作(追加/削除/タイプ変更)
[^6]: ref: https://dev.mysql.com/doc/refman/8.4/en/innodb-online-ddl-limitations.html
[^7]: ref: https://github.com/github/gh-ost/blob/master/doc/requirements-and-limitations.md
[^8]: ref: gh-ost は Go 言語, pt-osc は Perl で実装されている
[^9]: ref: https://github.com/github/gh-ost/issues/273
[^10]: ref: https://github.com/pingcap/tiflow/blob/v8.5.3/




