MySQLと高い互換性を持つデータベースのTiDBでは、DDLが高速かつオンラインで実施されとても有用です。メルカリの運用における気付きとして得られた、主に実行の速度制御とmodify columnの完了時間見積もりの学びについてお伝えします。
背景
メルカリではMySQLと高い互換性を持つTiDBを利用しているため、DDLはオンラインで実行でき、現状のところ大きな問題なく動作しています。
先日、数十億レコード程度のテーブルのALTERを実施した際、実行の完了時刻が予測できない、と感じた事象がありました。この記事ではこの問題について調査して得られた学びを共有したいと思います。DDLにはさまざまなバリエーションがあり、本記事が適用できないケースがあることにご留意ください。
なお、本記事中についてはTiDB CloudのDedicated(Serverlessでない方)を前提にしております。TiDB Cloudではなく、TiDBのSoftware版でもおそらく同じことがいえると思います。
実行中のTiDB障害
本記事では、DDLの実行完了の予測について取り扱いたいのですが、その前にDDLの進捗情報の永続化について整理をするために、まずはTiDBのDDLの障害耐性について整理したいと思います。
長時間のDDL実行における関心事項として、DDL中に障害が発生するとどうなるか、という懸念があげられます。
結論から言えば、障害が発生してもDDLは継続しますが、これにはDDLをどこまで実行したかの状態を永続化して保持し、かつ障害発生時に他のノードで実行を再開する仕組みが必要です。
TiDBでのDDLおよびDDL owner
TiDBでのDDL実行においてはDDL ownerという概念があり、あるTiDBがDDL Ownerの役割を担い、そのTiDBが主体となり実際にデータを保存するTiKVに対するDDLの実処理を実行します
https://docs.pingcap.com/best-practices/ddl-introduction/#tidb-ddl-module
https://pingcap.github.io/tidb-dev-guide/understand-tidb/ddl.html#execution-in-the-tidb-ddl-owner
DDL実行中にDDL ownerであるTiDBに障害が発生した場合どうなるでしょうか?
DDL ownerは、etcdベースで選出がおこなわれ、通常はDDL ownerが定期的にKeepaliveのような死活情報をetcdに報告することにより、etcdリース期間が延長されています。したがって、DDL owner障害時には、このKeepaliveが途絶えることによりetcdリースが失効し、新ownerが選出されます。
したがって、TiDB障害時にもDDLの処理は継続します。
メルカリでも、長時間のDDL中に(意図せず)TiDBのスケールダウンを行ってしまう事象が発生しましたが、その際にも実際に処理が正常に継続することを確認できました。
ただし、TiDBで実行中のプロセス一覧(information_schema.cluster_processlist)からは、ALTERのプロセスは確認できなくなる一方で、ADMIN SHOW DDL JOBSを確認すると処理が継続している、という状況でした。
DDLの実行状況の永続化
次に、DDLの状態の永続化です。DDLに関連するテーブルとしては
https://docs.pingcap.com/tidb/stable/mysql-schema/#system-tables-related-to-ddl-statements
があり、このうちバックフィルの情報はmysql.tidb_ddl_reorgに以下のように保持されます。
mysql> DESC mysql.tidb_ddl_reorg;
+-------------+----------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------+------+------+---------+-------+
| job_id | bigint | NO | MUL | NULL | |
| ele_id | bigint | YES | | NULL | |
| ele_type | blob | YES | | NULL | |
| start_key | blob | YES | | NULL | |
| end_key | blob | YES | | NULL | |
| physical_id | bigint | YES | | NULL | |
| reorg_meta | longblob | YES | | NULL | |
+-------------+----------+------+------+---------+-------+
7 rows in set (0.00 sec)これは次に処理すべきキーの値をstart_keyとして永続化する、という方法によっているようです。これにより処理が中断された場合、この情報を元に再開、継続することが可能となります。
また、実行中の設定や進捗の確認に関しては、mysql.tidb_ddl_jobに永続化されます。
こちらの詳細は記事の後半で再度内容を紹介します。
なお、こちらはDDLの実行が完了すると、mysql.tidb_ddl_historyに移動するため注意が必要です。
mysql> desc mysql.tidb_ddl_job;
+------------+------------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+------------+------+------+---------+-------+
| job_id | bigint | NO | PRI | NULL | |
| reorg | int | YES | | NULL | |
| schema_ids | mediumtext | YES | | NULL | |
| table_ids | mediumtext | YES | | NULL | |
| job_meta | longblob | YES | | NULL | |
| type | int | YES | | NULL | |
| processing | int | YES | | NULL | |
+------------+------------+------+------+---------+-------+
7 rows in set (0.00 sec)
mysql> desc mysql.tidb_ddl_history;
+-------------+------------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+------------+------+------+---------+-------+
| job_id | bigint | NO | PRI | NULL | |
| job_meta | longblob | YES | | NULL | |
| db_name | char(64) | YES | | NULL | |
| table_name | char(64) | YES | | NULL | |
| schema_ids | mediumtext | YES | | NULL | |
| table_ids | mediumtext | YES | | NULL | |
| create_time | datetime | YES | | NULL | |
+-------------+------------+------+------+---------+-------+
7 rows in set (0.00 sec)DDL実行中の速度制御
大容量テーブルに対する物理的なDDL(Reorg DDL)は、TiKVのリソース(CPUやI/O)を消費しながらデータのバックフィルを行うため、実行に時間がかかったり、リソースを過剰に消費するので、これらのコントロールが必要になることがあります。
すでに実行中のDDLジョブの速度を動的にコントロールするにはADMIN ALTER DDL JOBSを使用します。
現在の設定値や、どのような操作をするかにより設定可能な項目などは異なりますが、MODIFY COLUMNに区分される実態の再構築(Full Reorg)が必要なDDLでは、
- THREAD: DDLジョブのワーカー数
- BATCH_SIZE: ワーカーが1回のバッチで処理する行数
の変更が有効です。
ADMIN ALTER DDL JOBS <job_id> THREAD = 16, BATCH_SIZE = 1024;これらのパラメータはTiKVのリソースの消費量と、DDLの実行速度に影響し、負荷を抑えたい場合は、一時的なDDLの中断/再開も可能ですし、スレッド数を減らして実行することもできます。逆にTiKVのキャパシティーに余裕があり、高速に完了させたい場合にスレッド数やバッチサイズを増やしたりすることが有効です。
また、これらの初期値として、
を変更することが可能です。
通常、ADMIN ALTER DDL JOBS を実行するとその設定変更は即時で反映されることが期待されます。1点注意が必要なのは、特定のバージョン(v8.5.2, v8.5.3 など)において、特定のDDL(MODIFY COLUMN のcharからvarcharへの変更など)に対してADMIN ALTER DDL JOBSを実行しても、ワーカー数などの設定が実質的に反映されない不具合が報告されています。
- 関連Issue: #63201 ADMIN ALTER DDL JOBS can’t adjust the modify column job concurrency
- 関連PR: #63605 ddl: fix dynamic parameter adjustment failure in txn and local ingest mode
こちらに関しては、設定変更後に、PAUSE/RESUMEをすれば設定が反映されることを確認しています。
- PAUSE: https://docs.pingcap.com/tidb/stable/sql-statement-admin-pause-ddl/
- RESUME: https://docs.pingcap.com/tidb/stable/sql-statement-admin-resume-ddl/
DDLを実行の際はご利用のバージョンを確認し、必要に応じてPAUSE/RESUMEを試してみてください。
また、現状設定している値の確認に関しては先ほどの、mysql.tidb_ddl_jobから確認できます。
mysql> SELECT job_id, JSON_EXTRACT(CONVERT(UNHEX(TRIM(LEADING '0x' FROM HEX(job_meta))) USING utf8mb4), '$.reorg_meta.concurrency') AS concurrency, JSON_EXTRACT(CONVERT(UNHEX(TRIM(LEADING '0x' FROM HEX(job_meta))) USING utf8mb4), '$.reorg_meta.batch_size') AS batch_size FROM mysql.tidb_ddl_job WHERE job_id = 149;
+--------+-------------+------------+
| job_id | concurrency | batch_size |
+--------+-------------+------------+
| 149 | 8 | 1024 |
+--------+-------------+------------+
1 row in set (0.00 sec)DDL完了時間の見積もり
DDLについては実行完了時間の見積もりができることが望ましいと思います。
まず、前提条件としてTiDBでDDLを発行した際、ADMIN SHOW DDL JOBSコマンドで、information_schema.ddl_jobsのROW_COUNTという値が観測可能であり、これはDDLの実行に伴って値が増えていきます。
: ALTER文の実行
mysql> ALTER TABLE test_alter_row_count MODIFY COLUMN value INT NOT NULL; Query OK, 0 rows affected (0.28 sec)
: ADMIN SHOW DDL JOBSコマンドで実行結果/実行中の状況が確認可能
mysql> admin show ddl jobs 1;
+--------+---------+----------------------+---------------+--------------+-----------+----------+-----------+----------------------------+----------------------------+----------------------------+--------+----------+
| JOB_ID | DB_NAME | TABLE_NAME | JOB_TYPE | SCHEMA_STATE | SCHEMA_ID | TABLE_ID | ROW_COUNT | CREATE_TIME | START_TIME | END_TIME | STATE | COMMENTS |
+--------+---------+----------------------+---------------+--------------+-----------+----------+-----------+----------------------------+----------------------------+----------------------------+--------+----------+
| 151 | mercari | test_alter_row_count | modify column | public | 116 | 143 | 100000000 | 2026-02-27 01:45:35.549000 | 2026-02-27 01:45:35.549000 | 2026-02-27 02:03:25.748000 | synced | |
+--------+---------+----------------------+---------------+--------------+-----------+----------+-----------+----------------------------+----------------------------+----------------------------+--------+----------+
1 row in set (0.00 sec)この値を利用してどのように、完了時刻見積もりができるか、をバージョンごとに確認したのが本エントリの内容です。
v8.5.3まで
TiDB v8.5.3で下記のテーブルを作成し、1000行のデータにインデックスを作成していきました
CREATE TABLE test_alter_row_count (
id BIGINT UNSIGNED NOT NULL,
value INT UNSIGNED NOT NULL,
label VARCHAR(255) NOT NULL DEFAULT '',
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id) CLUSTERED
);
-- 1000行を挿入後、value カラムを参照するセカンダリインデックスを 0〜4 本作成
インデックス作成後に、INT UNSIGNEDから INTへの変更を伴う次のDDLを発行した際のROW_COUNTの変化を観測します。この変更は、UNSIGNEDとSIGNEDではバイト列のエンコーディングが異なるため、行データとインデックスの両方を書き換える必要があり、TiDB内部で、ModifyTypeReorg (Full Reorg)に分類されるものとなります。
ALTER TABLE test_alter_row_count MODIFY COLUMN value INT NOT NULL;結果としては、テーブルの行数をR、変更対象のカラムを含むインデックス数をnとした際に、下記のように変更対象のカラムに関連するインデックス数の2乗のオーダーのROW_COUNTとなること(R x (1 + n²))が観測されました。
| インデックス数 (n) | ROW_COUNTの値 | R x (1 + n²) |
|---|---|---|
| 0 | 1,000 | 1,000 |
| 1 | 2,000 | 2,000 |
| 2 | 5,000 | 5,000 |
| 3 | 10,000 | 10,000 |
| 4 | 17,000 | 17,000 |
複合インデックス(例: (value, created_at, updated_at))におけるROW_COUNTに対する寄与も確認し、これは単一カラムインデックスと同じ寄与で、インデックスに含まれるカラム数は無関係であることを確認しました。
処理の実態と発生条件
ROW_COUNTの観測により、DDLの完了時刻をなるべく正確に推測することを目標とすると、
この R x (1 + n²) という式が、ROW_COUNT の集計上のバグなのか、それとも実際に n² に比例する処理が走っているのかを切り分ける必要があります。
OSS の最新のmasterブランチを解析すると、masterのMODIFY COLUMNはカラム書き換えとインデックス再構築が別ステージに分離されており、n² パターンを説明できるコードパスは見つかりませんでした。
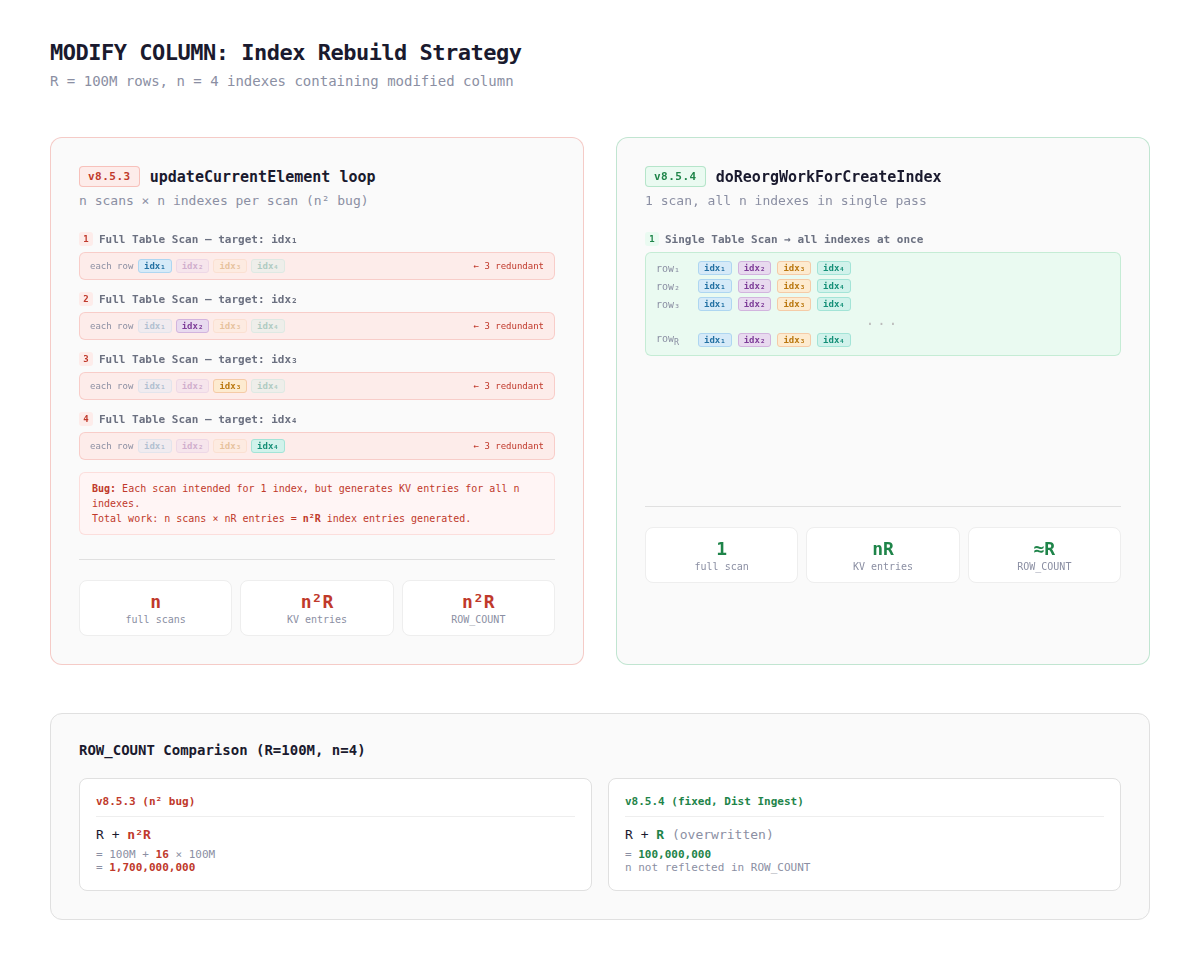
8.5.3に関してはMODIFY COLUMN(Full Reorg)はupdateCurrentElementという関数で処理され、この関数にはインデックスを逐次的に処理するループがありました。
https://github.com/pingcap/tidb/blob/release-8.5-20251107-v8.5.3/pkg/ddl/column.go#L523-L597
// pkg/ddl/column.go L523-596 (v8.5.3)
func (w *worker) updateCurrentElement(ctx context.Context, t table.Table, reorgInfo *reorgInfo) error {
// Phase 1: カラム書き換え(全 R 行の値を変換)
if bytes.Equal(reorgInfo.currElement.TypeKey, meta.ColumnElementKey) {
err := w.updatePhysicalTableRow(ctx, t.(table.PhysicalTable), reorgInfo)
}
// Phase 2: インデックス再構築ループ(n 回実行)
for i := startElementOffset; i < len(reorgInfo.elements[1:]); i++ {
reorgInfo.currElement = reorgInfo.elements[i+1] // 現在の要素を idx_i に設定
err = w.addTableIndex(ctx, t, reorgInfo) // インデックスを再構築
}
}ここからインデックス再構築でRx n²の操作が発生することになっている実装上の要因2点を説明します。細かい話なので読み飛ばしていただいて構いません。
1. Worker が「現在のインデックス」ではなく「全インデックス」を受け取る
addTableIndexの内部ではbackfill workerが生成されます。このとき、reorgInfo.elements(カラム+全 n インデックスを含む完全なリスト)がそのまま渡されます。
// pkg/ddl/backfilling_scheduler.go L280-281 (v8.5.3)
idxWorker, err := newAddIndexTxnWorker(b.decodeColMap, b.tbl, backfillCtx,
job.ID, reorgInfo.elements, reorgInfo.currElement.TypeKey)
// ^^^^^^^^^^^^^^^^^^
// 「全要素リスト」が渡されるWorkerはこのリストからインデックス型の要素をすべて抽出して保持します。
// pkg/ddl/index.go L1892-1900 (v8.5.3)
allIndexes := make([]table.Index, 0, len(elements))
for _, elem := range elements {
if !bytes.Equal(elem.TypeKey, meta.IndexElementKey) {
continue
}
indexInfo := model.FindIndexInfoByID(t.Meta().Indices, elem.ID)
index := tables.NewIndex(t.GetPhysicalID(), t.Meta(), indexInfo)
allIndexes = append(allIndexes, index) // 全 n インデックスが入る
}つまり、ループの i 番目のイテレーションでcurrElementがidx_iを指していても、Workerは idx₁ からidx_nまでの全インデックスを処理します。
その結果、テーブルの全行をスキャンする際に各行からn個のidxRecordが生成されます。
// pkg/ddl/index.go L2027-2032 (v8.5.3)
for _, index := range w.indexes { // w.indexes は全 n 個
idxRecord, _ := w.getIndexRecord(index.Meta(), handle, recordKey)
w.idxRecords = append(w.idxRecords, idxRecord)
}R行 × nインデックス = n×R 個のレコード。これがn回のイテレーションそれぞれで生成されるため、合計 n × n × R = n²R 個になります。
2. DupKeyCheckSkip による重複書き込みの黙認
仮に1があっても、2 回目以降のイテレーションでは「すでに同じインデックスエントリが存在する」ため、重複キーエラーで処理がスキップされれば実害は小さいはずです。しかし、BackfillDataではDupKeyCheckSkipフラグが指定されています。
// pkg/ddl/index.go L2349-2354 (v8.5.3)
handle, err := w.indexes[i%len(w.indexes)].Create(
w.tblCtx, txn, idxRecord.vals, idxRecord.handle, idxRecord.rsData,
table.WithIgnoreAssertion,
table.FromBackfill,
table.DupKeyCheckSkip, // 重複チェックを完全にスキップ
)DupKeyCheckSkipはindex.Create内部で以下のように作用します。
// pkg/table/tables/index.go L259-278 (v8.5.3)
skipCheck := opt.DupKeyCheck() == table.DupKeyCheckSkip // true
if !distinct || skipCheck || untouched {
err = txn.GetMemBuffer().Set(key, val) // 既存エントリを無言で上書き
continue // ErrKeyExists は発生しない
}重複チェックをスキップしているため、MemBufferへのSetは既存エントリを上書きするだけでエラーになりません。BackfillDataに戻るとtaskCtx.addedCount++が無条件に実行され、全 n×Rレコードがカウントされます。
v8.5.4での修正(2025年11月)
PR #63970 "modify column: support ingest/DXF mode to recreate indexes" により、MODIFY COLUMNの処理アーキテクチャが刷新されたことにより、この問題は解消しました。
TiDBの変更にはいくつかの種類があり、通常のインデックス追加はデフォルトではIngestという物理ImportであるTiDB lightningと同じ方式の高速な処理方法が適用されます。DXFというのは分散実行の仕組みで、これも通常Indexの追加に利用されます。
https://docs.pingcap.com/tidb/stable/tidb-distributed-execution-framework/
このPRの変更内容は、カラムの変更であるmodify columnの際のインデックス再構築にこの処理を利用可能にしたものです。
これにより、修正後のアーキテクチャでは、MODIFY COLUMNが 3 つの明示的なステージに分離されました。
Stage 1: ReorgStageModifyColumnUpdateColumn → カラム書き換えのみ
Stage 2: ReorgStageModifyColumnRecreateIndex → 全インデックスを一括再構築
Stage 3: ReorgStageModifyColumnCompleted → 完了updateCurrentElementのインデックスループは完全に削除され、modifyTableColumnにリネームされた関数はカラム書き換えのみを担当します。インデックス再構築は doReorgWorkForCreateIndexに委譲され、全インデックスを1 回の呼び出しで一括処理します。
// v8.5.4 pkg/ddl/column.go
func (w *worker) modifyTableColumn(...) error {
if bytes.Equal(reorgInfo.currElement.TypeKey, meta.ColumnElementKey) {
err := w.updatePhysicalTableRow(ctx, t, reorgInfo) // カラムのみ
}
return nil // インデックスループは存在しない
}この修正により n² 問題は解消され、doReorgWorkForCreateIndexはpickBackfillType でIngest / TxnMergeを動的に選択できるため、MODIFY COLUMNでもIngest(Lightning ベース)パイプラインが利用可能になりました。
また、詳細は割愛しますが、本問題は7.4.0から発生していたように思われます。
v8.5.4以降
さて、8.5.4以降でのバージョンで、modify columnで必要以上に時間がかかる構造は解消されていそうなことがわかりました。どのようにカウントされるようになったのでしょうか。
| インデックス数 (n) | ROW_COUNTの値 |
|---|---|
| 0 | 1,000 |
| 1 | 1,000 |
| 2 | 1,000 |
| 3 | 1,000 |
| 4 | 1,000 |
インデックス数に依存しないレコード数に等しい値となることが確認できました。
それでは、これのROW_COUNTの値を利用して、どのように実行の完了時間を予測できるでしょうか。
これを確認するため、1億レコードのテスト用のテーブルと、4つのインデックスを事前に作成、これらに対してDDLを実行し、ROW_COUNTの推移を実際に観測してみました。

ROW_COUNTは最終的にはレコード数Rになるのですが、最初のカラムの書き換えがおわり、インデックスの再構成が発生する際に一度0にクリアされ、n本のindexが同時構築されるため再度増加しRに達する、という挙動が観測されました。また、Step 2のIngestは高速な処理が行われることも合わせて確認できると思います。
また、ROW_COUNTがRに達した後も何らかの処理が継続されますが、現状この状態の進捗を何らかの方法で確認する方法は確認できておりません。
なお、このステージおよび、ROW_COUNTについては、先ほどのmysql.tidb_ddl_jobにより確認可能で、今回検証でこのDDLの進捗確認に利用したスクリプトを共有します。
import pymysql
import time
import csv
import sys
JOB_ID = 151
INTERVAL = 5
conn = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="",
database="test",
autocommit=True
)
cursor = conn.cursor()
cursor.execute("SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED")
log_file = f"ddl_job_{JOB_ID}.csv"
with open(log_file, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["elapsed_sec", "timestamp", "row_count", "state", "schema_state",
"stage", "reorg_tp", "concurrency", "batch_size",
"task_id", "task_state", "subtask_row_count"])
META_QUERY = """
SELECT
JSON_EXTRACT(CONVERT(UNHEX(TRIM(LEADING '0x' FROM HEX(job_meta))) USING utf8mb4), '$.reorg_meta.stage'),
JSON_EXTRACT(CONVERT(UNHEX(TRIM(LEADING '0x' FROM HEX(job_meta))) USING utf8mb4), '$.reorg_meta.reorg_tp'),
JSON_EXTRACT(CONVERT(UNHEX(TRIM(LEADING '0x' FROM HEX(job_meta))) USING utf8mb4), '$.reorg_meta.concurrency'),
JSON_EXTRACT(CONVERT(UNHEX(TRIM(LEADING '0x' FROM HEX(job_meta))) USING utf8mb4), '$.reorg_meta.batch_size')
FROM mysql.tidb_ddl_job
WHERE job_id = %s
"""
print(f"Monitoring JOB_ID={JOB_ID} every {INTERVAL}s → {log_file}")
print(f"{'elapsed':>8} {'row_count':>14} {'state':<10} {'stage':>5} {'reorg_tp':>8} {'thr':>3} {'batch':>6} {'task_id':>7} {'task_state':<10} {'subtask_rows':>14}")
print("-" * 110)
start = time.time()
while True:
try:
# ROW_COUNT (real-time from memory)
cursor.execute("""
SELECT JOB_ID, ROW_COUNT, STATE, SCHEMA_STATE, NOW()
FROM information_schema.ddl_jobs
WHERE JOB_ID = %s
LIMIT 1
""", (JOB_ID,))
ddl_row = cursor.fetchone()
# Stage/config from job_meta (persisted)
stage = reorg_tp = conc = bs = ""
try:
cursor.execute(META_QUERY, (JOB_ID,))
meta_row = cursor.fetchone()
if meta_row:
stage = meta_row[0] if meta_row[0] is not None else ""
reorg_tp = meta_row[1] if meta_row[1] is not None else ""
conc = meta_row[2] if meta_row[2] is not None else ""
bs = meta_row[3] if meta_row[3] is not None else ""
except Exception:
pass
# Dist task progress (only exists during Stage 2)
task_id = ""
task_state = ""
subtask_row_count = ""
try:
cursor.execute("""
SELECT id, state FROM mysql.tidb_global_task
WHERE task_key LIKE CONCAT('ddl/%%/', %s, '%%')
ORDER BY id DESC LIMIT 1
""", (JOB_ID,))
task_row = cursor.fetchone()
if task_row:
task_id, task_state = task_row
cursor.execute("""
SELECT COALESCE(SUM(summary->'$.row_count'), 0)
FROM mysql.tidb_background_subtask
WHERE task_key LIKE CONCAT('ddl/%%/', %s, '%%')
""", (JOB_ID,))
st_row = cursor.fetchone()
if st_row:
subtask_row_count = st_row[0]
except Exception:
pass
elapsed = int(time.time() - start)
if ddl_row:
job_id, row_count, state, schema_state, ts = ddl_row
row_count = row_count or 0
line = (f"{elapsed:>7}s {row_count:>14,} {state:<10} {stage:>5} {reorg_tp:>8} "
f"{conc:>3} {bs:>6} {str(task_id):>7} {str(task_state):<10} {str(subtask_row_count):>14}")
print(line)
with open(log_file, "a", newline="") as f:
writer = csv.writer(f)
writer.writerow([elapsed, ts, row_count, state, schema_state,
stage, reorg_tp, conc, bs,
task_id, task_state, subtask_row_count])
if state in ("synced", "cancelled", "paused"):
print(f"\nJob finished: state={state}, final ROW_COUNT={row_count:,}")
break
else:
print(f"{elapsed:>7}s job not found")
except Exception as e:
print(f" error: {e}")
conn.ping(reconnect=True)
cursor = conn.cursor()
cursor.execute("SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED")
time.sleep(INTERVAL)
cursor.close()
conn.close()なお、mysql.tidb_ddl_jobテーブルのjob_meta属性にはJSONの値が格納されていますが、この中の構造に現れるreorg_meta.stageは8.5.4による、DDLの実行方式の変更に伴い新設されています。これにより、8.5.4以降ではStage 1完了後に一度ROW_COUNTがリセットされるものの、現状どちらのStageを処理しているかの判別ができます。
最終的にバージョン間で差分が見られるインデックス再構築の箇所のみに焦点を当て、それぞれのバージョンでどうなっていたか、という結論を図にまとめたものが以下になります。
まとめ
今回はDDL実行中の速度制御の方法と、完了時間の見積もりについて紹介しました。
速度制御については、ADMIN ALTER DDL JOBSで可能である一方、コマンド実行により変更が反映されないバグが含まれるバージョンがあり、PAUSE/RESUMEにてこれを反映できることを説明しました。
完了時間見積もりについては、DDLがmodify columnに分類される場合、ROW_COUNTの値で見積もりが可能です。TiDB 8.5.3までは、対象のカラムを含むインデックス数の2乗のオーダーに比例する不具合があり、また、ROW_COUNTが統計上の値が増えているだけではなく、実際に発生するI/Oなどにも直接影響し注意が必要です。
また、TiDB 8.5.4以降では、インデックス再構築が、従来とは異なる方式で実施されるようになり、重複して実行される不具合は解消し、かつ高速になりました。ROW_COUNTは最終的には、レコード数に近い値になるものの、インデックス構築フェーズで値が一度ゼロにリセットされ、再度カウントアップする挙動となっていた検証結果を共有しました。
マイナーバージョンによる不具合などについては、公式ドキュメントをよく読んでいるだけではわからないことが多く、他のDBMSなどをみても、この類の情報が充実してくると、利用者としても安心できる状況に近づくのではないかと考えています。
メルカリではTiDBの運用を進めており、このような想定と異なる挙動の遭遇はまだまだ多く、避けられないものです。このような、想定外の挙動に対し、生成AIなどを活用し状況を理解し、世の中に発信しユーザーや製品に還元していけるような仲間を求めています。
また、現在当チームのマネージャーポジションが募集中となります。興味ある方はぜひご応募ください。
https://apply.workable.com/mercari/j/7AD4EF9218/



