
こんにちは。Mercari Ads teamのEngineering Managerの@ogataka50です。
この記事は、Mercari Advent Calendar 2025 の15日目の記事です。
1. はじめに
Mercari Ads では、メインの DB として TiDB を採用しています。HTAP(Hybrid Transactional and Analytical Processing)により、広告設定などのオンライン処理(OLTP)と、impression・conversion の集計などのバッチ処理(OLAP)を単一クラスタで運用しています。しかし、ワークロードの多様化とトラフィック増加に伴い、リソース競合による性能劣化が次第に顕在化しました。具体的には次のような事象です。
- バッチ処理や集計処理が TiDB に過度な負荷をかけると、広告管理ツール(Ads Manager)の操作のレスポンスが悪化し、サービス品質(UX)に悪化
- 逆に、オンライン処理が重くなったときにバックグラウンドのレポート集計やバッチ処理が大幅に遅延。これによりレポートの生成やデータ更新が遅れ、期待どおりの動作にならない
このような異なるワークロード同士のリソース競合によって、システムの安定性やパフォーマンスが低下する課題に直面していました。
そこで、TiDB の Resource Group を使って、用途(オンライン/バッチ/レポートなど)ごとにリソースを論理分離し、干渉しないよう制御することにしました。
本記事では、Resource Group の概要と、どのように導入を進めたかを共有したいと思います。
2. Resource Control の概要
Resource Group は、TiDB におけるリソース制御機能のひとつで、論理的な「グループ 」に分け、各グループに対して CPU/I/O/ストレージへのアクセス量を制御できます。
この制御の単位となるのが Request Unit (RU)になります。RU は CPU 時間やディスク I/O、IOPS など複数リソースの消費量を統合して評価する抽象的な単位です。
TiDB の公式ドキュメントでは以下のように RU の消費定義が示されています。
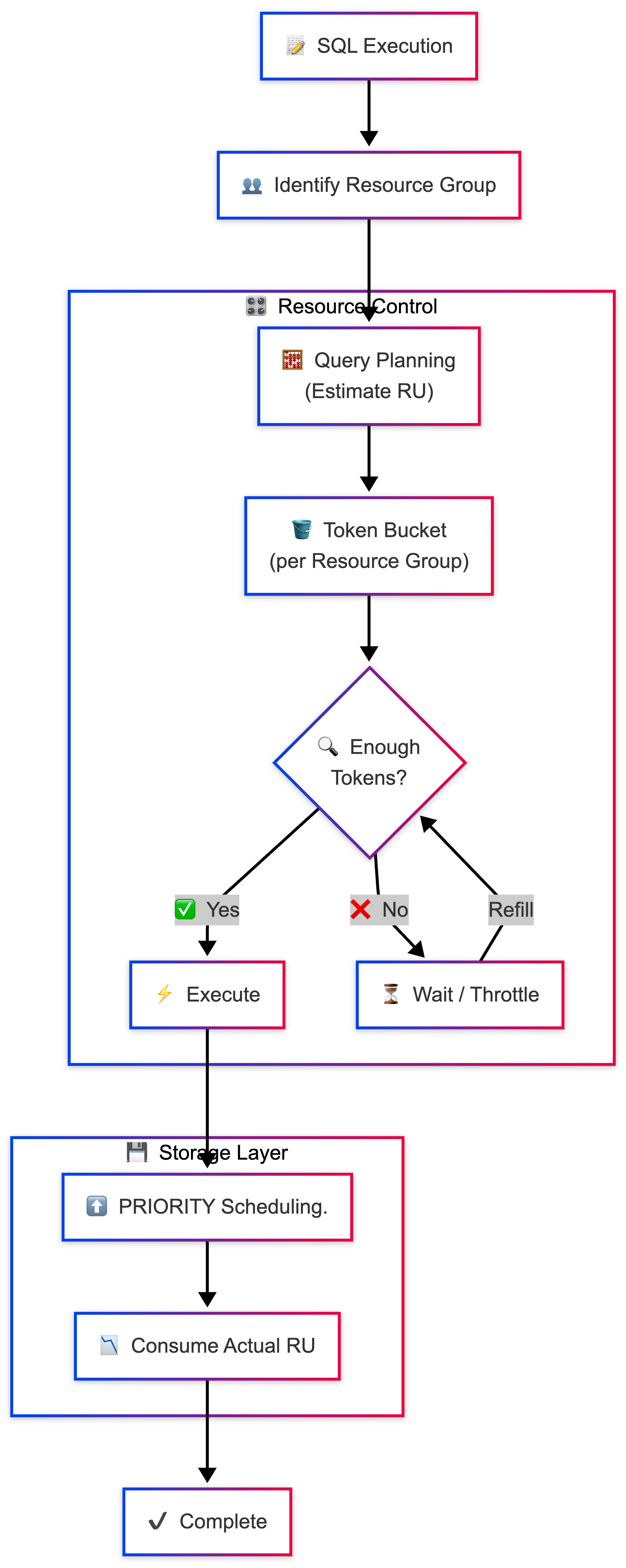
Resource Group を使い、複数のワークロードで必要なTiDBのリソースを論理的に分離して、リソース競合を防ぎつつ、必要に応じてリソースを割り当て直すことができます。具体的には以下のような処理です。
- オンライン処理には高めの RU を割り当てる + 高優先度で処理させる
- バッチ/分析には必要最小限の RU を割り当て、低優先度で処理させる
この仕組みによって、オンライン処理のレイテンシを維持しつつ、バッチや分析処理も同時に安定して実行できるようにすることを目指しました。
3. 実際の導入方法
3.1 サービスごとに SQL ユーザーと Resource Group を分離
Mercari Ads では、各マイクロサービス (広告管理 UI、レポート生成バッチ、分析サービスなど) ごとに SQL ユーザーを分け、それぞれに専用の Resource Group を割り当てるようにしました。
クエリ単位でヒントを使って Resource Group を設定することも可能ですが、多数のサービス/クエリが混在すると運用が煩雑になりやすいため、SQLユーザー単位での分離することから始めました。
3.2 Resource Group の定義例
まずは Resource Group を作り、それを SQLユーザーに紐付けるような流れになります。
次の SQL で Resource Group を作成します。
-- create Resource Group
CREATE RESOURCE GROUP IF NOT EXISTS rg_online
RU_PER_SEC = 2000
PRIORITY = HIGH
BURSTABLE;
CREATE RESOURCE GROUP IF NOT EXISTS rg_batch
RU_PER_SEC = 500
PRIORITY = LOW;- RU_PER_SEC: 1 秒あたりに補充される RU の量 (トークン・バケットの回復速度) を指定
- PRIORITY: ストレージ層 (TiKV / TiFlash) 側でのタスク優先度 — 高優先度なら他より先に処理される
- BURSTABLE: 状況に応じて余剰リソースの利用を許可する設定。負荷が低いタイミングでは余裕を使える
どの Resource Group をどの SQL ユーザーに割り当てるかを、以下の SQL で設定します。
-- bind Resource Group and SQL User
ALTER USER 'ads_service_sql_user' RESOURCE GROUP rg_online;
ALTER USER 'batch_job_sql_user' RESOURCE GROUP rg_batch;optimizer hintsを追加することでSQL単位でResource Group を指定することも可能です。
-- SQL 単位で Resource Group を指定する例
SELECT /*+ RESOURCE_GROUP(rg_name) */ * FROM table_name;3.3 モニタリング → 設定の見直しサイクル
次のようなサイクルで適切な設定値の調整をしていきました。
- まずは制限なしのRU_PER_SEC (default / unlimited 相当) での Resource Group を作成し、各サービスの「通常負荷時」のリソース消費を観測
CREATE RESOURCE GROUP IF NOT EXISTS rg_monitoring RU_PER_SEC = 2147483647; - 1週間程度監視し、通常時のRU 使用量、I/O/CPU 負荷、クエリ数などを把握する
- 用途 (オンラインかバッチなど) に応じて RU_PER_SEC・PRIORITY・BURSTABLE を設定し直す
- オンライン処理: RU_PER_SEC 高め / HIGH 優先度、必要なら BURSTABLE を使うことを検討
- バックグラウンド(バッチ/分析)処理: RU_PER_SEC 控えめ / LOW 優先度
このサイクルを継続し、各 Resource Group の RU_PER_SEC を徐々に適正化しました。

4. 平均値ベースだけではなく、瞬間的な RU の消費も考慮する
Resource Group を SQL ユーザーごとに分け、RU_PER_SEC の設定を進めていく中で、意図通りにいかなかったケースがありました。あるサービスは、平常時はほとんど TiDB にアクセスしないのですが、ユーザが期間の長い広告レポートをリクエストした際にだけ、大量のデータを読み取る集計処理が発生し、瞬間的に多くの RU を必要とするケースがありました。このような場合平均値ベースの RU 消費は小さく見えます。しかし実際には、1 回のリクエストで数千〜数万 RU を消費するようなスパイクがあり、平均値を基準に RU_PER_SEC を設定していたため、このスパイク時に上限に達してしまい、必要な RU を確保できず著しくパフォーマンスが低下する状況が生まれてしまいました。

そのため、RU_PER_SEC の設定では平均値だけではなく、瞬間的なスパイクにも対応できるよう考慮する必要があります。こうしたユースケースでは、必要に応じて BURSTABLE を有効化し、一時的に余剰リソースを利用できるようにすることも効果的です。
5. Runaway Query の制御と管理
Resource Group によるリソース分離だけでなく、想定以上にリソースを消費するクエリを制御、管理する機能があります。
Resource Group 定義に、QUERY_LIMIT オプションを追加することで、あるクエリが長時間実行される、または過剰にリソースを消費するような クエリを検知し、強制終了 (KILL)、優先度変更といった制御が可能です。
TiDB では、このような予想以上にリソースを消費するクエリを Runaway Query と呼んでいます。
たとえば、以下のように定義することで、「30秒以上実行されるクエリは自動的にkillする」などの制御ができます。
-- configure QUERY_LIMIT on resource group
CREATE RESOURCE GROUP rg_online_limited
RU_PER_SEC = 10000
QUERY_LIMIT = (EXEC_ELAPSED = '30s', ACTION = KILL);こうした制御を入れることで、意図せぬ重たいクエリや無限ループ/誤った SQL による極端なリソース消費や、他ワークロードへの影響を防ぐ一助になります。
発生した Runaway Query は、次の SQL で確認できます。
-- select Runaway Query by Resource Group
SELECT *
FROM mysql.tidb_runaway_queries
WHERE resource_group_name = 'rg_online_limited'
ORDER BY start_time DESC
LIMIT 100;6. まとめ & 今後の展望
Resource Groupの導入によって、オンライン処理に必要な RU を安定して確保できるようになり、Ads Managerのレイテンシがバックグラウンド処理の影響を受けにくくなりました。また、バックグラウンド処理側も過剰にリソースを奪わない範囲で着実に実行されるようになり、ワークロード間の競合による性能劣化が減少しました。
実施した内容をまとめると、以下の通りです。
- 現状のワークロード把握
- 各SQL user(≒サービス)ごとにどのようなシステム要求があるかリストアップ (オンライン/バッチ/Background/分析用途など)
- 最初は制限なし (default / UNLIMITED 相当) で動かし、どれくらい RU を消費するか観測
- モニタリング期間 (数日〜1週間)
- 通常時のRU 消費を計測
- 特にバッチや分析クエリのピーク時の消費量に注意する
- ワークロードごとに Resource Group の設定値を設定
- オンライン処理: 応答性重視 → RU_PER_SEC を比較的高め、PRIORITY = HIGH、必要なら BURSTABLE を使うことを検討
- バックグラウンド処理: RU_PER_SEC を控えめ、PRIORITY = LOWで必要以上のリソースを消費しないようにした
- 必要に応じて Runaway 制御 (QUERY_LIMIT) を設定
- 継続的な運用とレビューサイクル
- 定期 (週次/月次) で RU 消費状況、遅延・タイムアウト・失敗のログをチェック
- 発生したRunaway Queryの確認
- 必要に応じてResource Group 設定を調整
今後は引き続き下記のような改善、調整を行っていこうと考えています。
- スパイクが発生するケースでは、一時的に割当を調整するなど、Resource Group と Runaway 制御を組み合わせた運用改善
- 定期レビューの自動化。どのサービスがどれくらい RU を使っているか/どの程度余裕があるかなどを可視化と調整
本記事が TiDB 運用の一助となれば幸いです。
明日の記事は @Snehaさんです。引き続きお楽しみください。
7. Refs
- Use Resource Control to Achieve Resource Group Limitation and Flow Control
- CREATE RESOURCE GROUP
- Manage Queries That Consume More Resources Than Expected (Runaway Queries)
- TiDB Resource Control: Stable Workload Consolidation of Transactional Apps
- Managing Resource Isolation: Optimizing Performance Stability in TiDB




