
この記事は Merpay Advent Calendar 2023 の 20 日目の記事です。
こんにちは。メルペイの Payment Core チームでバックエンドエンジニアをしている komatsu です。
普段はメルカリ・メルペイが提供するさまざまな決済機能を支えるための決済基盤の開発・運用をしています。
この記事では、我々が開発している決済基盤マイクロサービスである Payment Service を適切に監視するために、Datadog の Dashboard を大きく刷新した背景や方法について紹介します。
Observability と Datadog Dashboards
本題に入る前に、Observability と Datadog Dashboards について簡単に説明します。
Observability はシステムの内部状態を適切に監視し、外部から可視化することでシステムを理解する能力およびその考え方を指します。
適切に可視化して監視することで、既知の問題のみならず、未知の問題に対しても、より迅速に検知・解決することが可能になります。
Observability を実現するには、次の 3 つの Telemetry の要素が重要だと考えられています。
- Metrics – CPU 使用率やメモリ消費、ネットワークトラフィックなど、システムリソースの使用状況などを示す定量的なデータ
- Trace – システム内を遷移する各リクエストのトランザクションの経路と処理時間を追跡し、E2E でパフォーマンスを可視化するデータ
- Logging – 操作の履歴やエラーメッセージなど、アプリケーションが生成する時系列のイベントデータ
Datadog においても、Metrics は Datadog Metrics、Trace は Datadog APM、Logging は Datadog Log Management というサービス名でそれぞれ提供されています。
これらのサービスはそれぞれの Telemetry を可視化するためのものですが、3 つすべてを一箇所に集約して可視化するために利用されるのが Datadog Dashboards です。
任意の Telemetry を任意のメトリクスや自由度の高いクエリを組み合わせて Widget を作成し、それを自由に並べ替えることで、あらゆる Telemetry データを 1 つのページに可視化することができます。
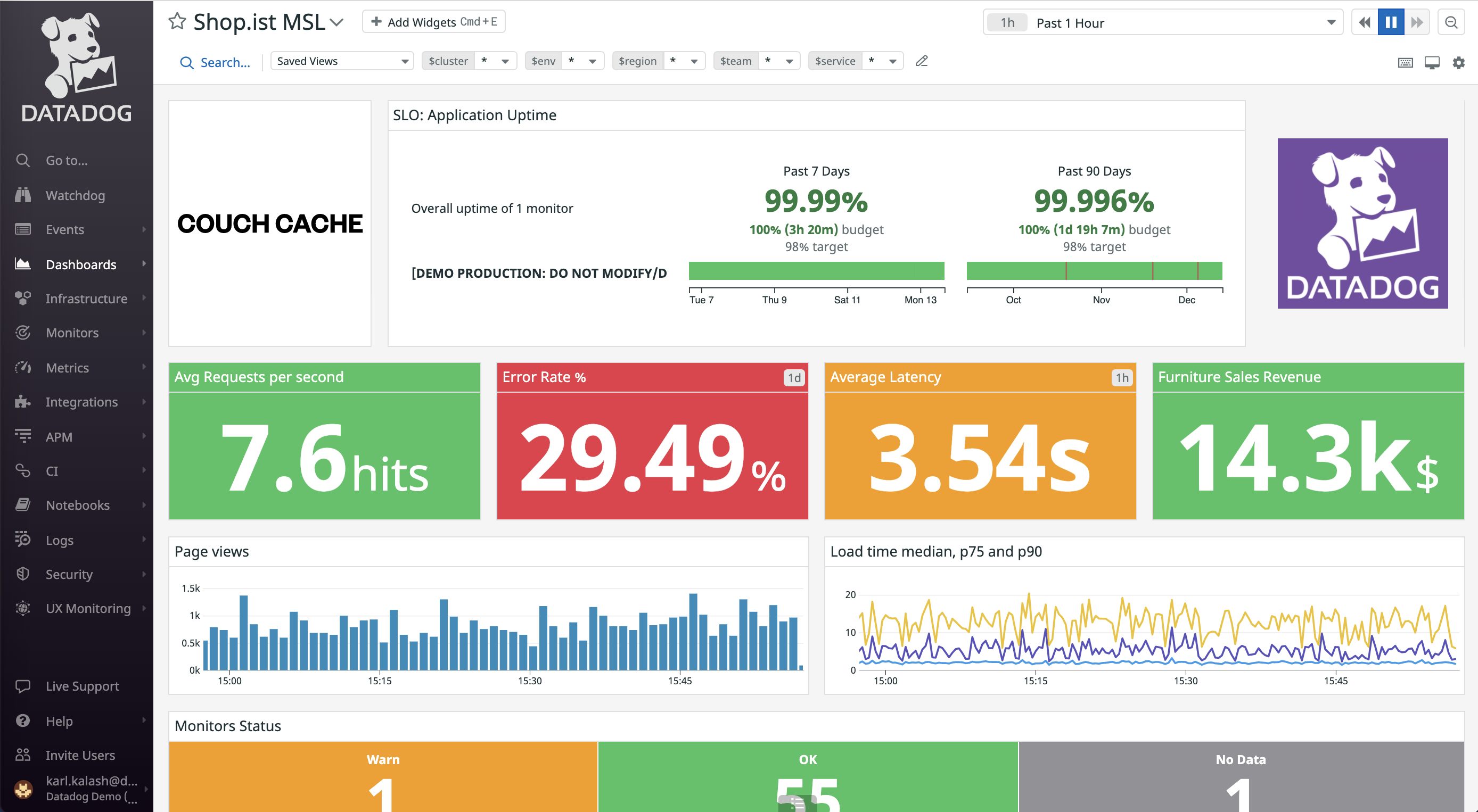
(https://www.datadoghq.com/product/platform/dashboards/ より引用)
基本的な機能は Grafana や New Relic Dashboards、Splunk Dashboards などと同様ですが、メルカリグループでは Datadog を主なクラウド監視ツールとして導入しているため、Payment Core チームでも各マイクロサービスの状態を可視化するために Dashboard を利用しています [1]。
また、Payment Core チームが管理する最も大きなマイクロサービスが Payment Service です。
マイクロサービスにおける決済トランザクション管理 からも分かるように、決済に関するほぼすべてのリクエストは Payment Service を経由して下位のマイクロサービスに伝播します。
そのため、Payment Service の Observability を向上することはメルカリグループ全体のサービスの安定化につながります。
Payment Service の Dashboard が抱えていた問題と刷新の動機
Payment Service には元々システム全体を可視化する Datadog Dashboard がありました。
ある程度グループで分類されてはいますが、300 を超える Widget が貼られており、かなりカオスな Dashboard であることは誰の目に見ても明らかでした。
多くのチームメンバーが Dashboard に不満を抱える一方で、それをリファクタリングしていく作業は地味であり、長い間放置されていました。
この Dashboard が抱えていた課題には次のようなものがありました。
次の 3 つのカテゴリに分類した上で問題点を紹介します。
可視性 (Visibility) の欠陥
可視性の欠陥は、Dashboard 上の可視化されたさまざまな値を見ても理解することが困難であったり、そもそも情報に欠損があるといった問題を意味します。
私たちのチームでは以下のような可視性に関する課題を持っていました。
- 一目でマイクロサービスの健康状況を把握することができない
- この Dashboard はエンジニアだけでなく PdM も確認するため、より簡潔にシステムの状態を表現する Widget の需要がありました。
- 時系列データが示す値が正常なのか異常なのかを判断することが難しい
- Datadog Monitors で管理している Monitor ではしきい値を確認することで “どのくらい危険な状態なのか” を確認できる一方で、しきい値を持たない Widget は現状の値は表現できても、危険度を表現することはできませんでした。
- API のレイテンシを表す Widget において、処理時間に大きく差が生じるパラメータによってグラフが区別されていない
- レイテンシを表現する Widget はありましたが、Payment Service が提供する API は、内部で同期処理にするか非同期処理にするかのリクエストパラメータによってレイテンシが大きく異なったり、決済手段の組み合わせによって速度に差があるため、それらを区別しないグラフは信頼性に欠けていました。特に残高やメルペイのあと払い、チャージ払いなどの決済手段はそれぞれ異なるマイクロサービスに依存しているため、決済手段ごとのレイテンシを表現する必要性がありました。
- canary release 時に既存のデータとの区別がつかない
- 私たちのチームでは、マイクロサービスのリリース時に一部のトラフィックにのみ新しいバージョンの pod を割り当てる canary release を採用しています。しかし多くの Widget は canary の pod やバージョンによってフィルタできるように整備されておらず、ノイズが多いことでリリース時の影響確認が困難でした。
診断性 (Diagnosability) の欠陥
診断性の欠陥は、可視化された Dashboard から問題を適切に区別し、解決に向けたアクションが取りにくいことを意味します。
私たちのチームでは以下のような診断性に関する課題を持っていました。
- 異常な状態を示す Widget があっても次のアクションにつなげにくい
- 仮に異常値を発見しても、APM やログを細かく確認するといった次のアクションにつなげにくい状態でした。
- マイクロサービス内の問題か外部起因の問題かの区別がつかない
- ある異常値が自分たちのマイクロサービス (i.e., Payment Service) に起因するものなのか、依存している他のマイクロサービスや外部の API なのかを区別することが困難でした。Payment Service は多くのプロダクト側のマイクロサービスから呼ばれると同時に、多くのマイクロサービスに依存しているため、次のアクションにつなげるために、どこに原因があるかをすぐに判断できる仕組みが必要でした。
メンテナンス性 (Maintainability) の欠陥
メンテナンス性の欠陥は、新しい API や機能の追加やしきい値の変更に Dashboard が追従できず、必要十分な状態に保てないことを意味します。
私たちのチームでは以下のようなメンテナンス性に関する課題を持っていました。
- そもそもメンテナンスされていない Widget がある
- Dashboard は Payment Service リリース時に作成されたものであり、基本的にメンバーが自由に変更できるため、統一感がなく、template variables のような機能が適切に設定されていない Widget も散見されました。
- 適切に Widget がグルーピングされていない
- 無造作に Widget が追加されていった結果、どこに何があるのかが分かりにくくなるだけでなく、新たに Widget を追加するときにどこに置くべきか判断しにくい状態でした。
このように、私たちの Dashboard は多くの問題を抱えながらも、長い間放置されていました。
その中で、今年の 1-3 月にこのようなコードべース以外の負債をまとめて解消する時間をチームで作ることができたため、その一環で Dashboard の刷新を行いました。
次の章では、どのようなアプローチによって問題を解決し、どのように新しい Dashboard v2 を実現したかを説明します。
Dashboard の刷新
Critical User Journey を意識する
Dashboard v2 を作る上で大事にした思想が “CUJ を意識する” ということでした。
CUJ は Critical User Journey の略で、ユーザ体験を設計する上で、プロダクトのユーザがそのプロダクトを利用して達成するタスクやプロセス、またはそのシナリオを意味します。
ここで、私たちの CUJ におけるユーザは、メルカリアプリを使用するお客さまではなく、決済基盤である Payment Service を利用するプロダクト側のマイクロサービスの開発者を意味します。
CUJ を意識した Dashboard を作ることで、例えばアラートが発生したときや依存されているマイクロサービスの開発者から問い合わせを受けたときに、Dashboard のどこを見ればよいのか、他にどこに影響が出ているのかなど、決済基盤が知っておくべき状況を理解しやすくすることができます。
CUJ を Dashboard に落とし込む際の考え方として、以下のような流れに沿って行いました。
- CUJ を考える
- 残高を使って決済をする、クレジットカードの登録をする、決済をキャンセルする、など
- CUJ を満たす基準を考える
- SLO の考え方に近い
- 99.9% の決済は成功する、99.9% のクレカ登録は 0.1 秒以内に完了する、など
- CUJ を満たせない場合に発火するアラートを作成する
- アラートと同様の定義を Dashboard の Widget として表現する
このような流れで適切な粒度で CUJ を監視できる形に変化させます。
どのように Dashboard を刷新したか
CUJ を意識した上で、前章の問題点についてそれぞれ次のような仕組みや機能によってアプローチしました。
可視性の向上 – 健康状態の可視化
私たちは前述の考え方から、“システムが健康である” ことを、”アラートが発生していない状態” と定義しました。
これは、GitHub や Slack を始めとする多くの Web アプリケーションが status ページを持っていることを参考に、アラートベースで健康状態を定義することがもっともシンプルだからです。
Dashboard が担当するドメインはあくまで可視化であるべきなので、すでに持っている Datadog Monitors や蓄積されている Metrics を用いることが合理的です。
Datadog Monitors がすでに整備されていることが条件ではありますが、チーム内では同時期に Datadog Monitors の整備やインフラ関連の定義の CUE 言語への置き換え [2] などを行っていたため、タイミングがとても良かったです。
下の図は、Dashboard の一番上に位置している System-wide status の中の 1 つの Widget です。
Datadog Monitors を 1 つの Widget にまとめてリッチに表示することができる Monitor Summary Editor を利用しています。
各 Monitor はどのマイクロサービスのものなのかという情報をタグで持っているため、フィルタを設定することで Payment Service のアラート状況のみをまとめることができます。
エンジニアであれば他の方法でアラート状況の確認ができる場合もありますが、PdM や他のチームの開発者が見たとしても理解しやすく、Payment Service の status ページの役割も兼ねていると言えるでしょう。

可視性の向上 – しきい値の可視化
ある API のレイテンシや DB のタイムアウト数を表現する時系列データが “問題になり得るレベルより安全側にいるのか” や “問題になり得るレベルと現状の差” を表現するために、下図のように各 Widget にマーカーを設定しました。
これによって Widget を見た人は "12 月 17 日の朝にレイテンシが少し高くなったが、アラートレベルではない" ということを一目で理解することができます。

各しきい値は同様の Monitor がある場合はその値と同じ値を採用しています。
Dashboard は Monitor と違って手で編集しているため、Monitor の定義が変更されると Dashboard と差分が生じる問題も議論の中ではありましたが、しきい値の変更は頻繁にはないことを理由に許容しています。
また、当初は時系列の Widget をそれぞれ作成するのではなく、Alert Graph (Moitor をひとつ選択して Dashboard に貼ることができる Widget の種類) を利用することを検討していました。
これによって過半数の Widget はその定義を Monitor に移譲することができるからです。
しかし、Monitor は本番環境全体を監視するものしか持っていなかったため、他の問題点でもある canary pod の状態のみを表示したり、本番環境ではなく開発環境でフィルタしたいときに不都合でした。
可視性の向上 & 診断性の向上 – APM resource の細分化
Payment Service の Dashboard には元々レイテンシを計測する指標として各 API の Trace がありましたが、前述の通り決済手段の組み合わせやその他のリクエストパラメータによってレイテンシが大きく異なるため、CUJ に沿ってこれを細分化しました。
具体的には、gRPC interceptor に Trace を細分化する処理を追加し、決済手段の組み合わせごとに別の APM resource として認識させることで、Dashboard からも別々のレイテンシを取得できるようにしました。
これによって残高払いのみを利用した時のレイテンシ、あと払いのみを利用した時のレイテンシ、2 つを組み合わせた時のレイテンシを区別することができるようになりました。
この利点は単に Widget が示す値の信頼性を高めるということだけでなく、例えば残高払いのレイテンシが跳ねたときにあと払いのレイテンシも跳ねていれば DB やネットワークの問題などの共通部分の問題を疑うことができ、片方だけであれば依存するマイクロサービスや周辺の実装を疑うことができるため、調査もより楽になりました。
リクエストパラメータの中には今回の支払手段のように実行時間に大きく影響を与えるものもあれば、内部の if 文に影響があるような小さいもの、まったく与えないものがあります。
どのレベルまで分けるかというのはそのマイクロサービスの役目やドメインによって異なるものですが、マイクロサービスの依存関係や主要な CUJ を意識することで適切なレベルで分割が可能になります。
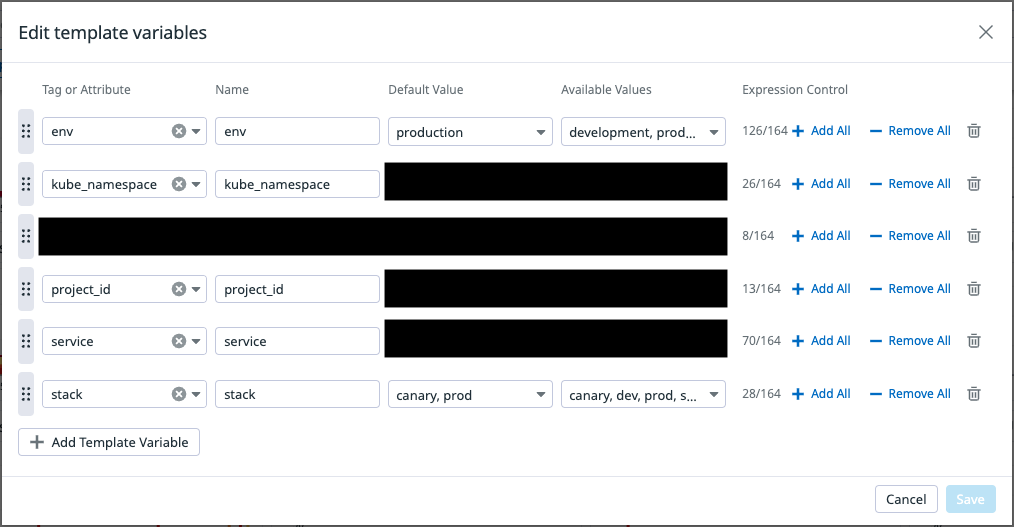
可視性の向上 & メンテナンス性の向上 – 適切なタグ管理と template variables の整備
canary 環境のみを可視化することは、私たちが安全にソフトウェアをデリバリーする上で非常に重要な機能でした。
canary 環境かどうかという情報は、インフラ観点では Kubernetes の stack として保持していますが、Metrics をフィルタする上では能動的にタグを付与する必要があります。
そのため環境変数として Deployment に stack 情報を記載し StatsD [3] に Metrics を送信する段階で stack の情報も付与するようにしました。
これによって、Dashboard 上の Widget を stack でフィルタすることが可能になりました。
各 Widget は Metrics を選択する際の変数の指定方法として、直接 stack:canary のように記述することも可能ですが、Dashboard 全体で変数を定義できる template variables を利用することで、 各 Widget 内では stack:$stack として定義しています。
この機能を使うことで、すべての Widget の stack タグを変更してフィルタしたり、その設定を View として保存することができます。
メンテナンス性の観点からも、新しい stack が追加されるなどの変更に追従しやすい設計が可能となります。
Dashboard v2 では次のような template variables と View を持っています。

診断性の向上 – Context Links による Widget と Logs や Traces の接続
Dashboard の Widget のグラフをクリックすると、下図のようなポップアップが表示されます。
この例では、”View related traces” をクリックすることで、このグラフに関連する Datadog APM Traces を一覧で表示してくれます。
これによって Widget 内で異常な値があったときにすぐにリクエストのどこに問題があるかを調査する次のステップに進むことができます。
一方で、この例では “No related logs” となっていて、Datadog Logs に飛んでログを確認することはできません。
これらの機能は Widget に設定されている条件 (from 句) を参考に自動で生成されていますが、Metrics と Logs で同じフィールドを持っていないと正しくヒットしなかったからです。
そのため、アプリケーション内の logger に APM と同じタグを付与したり、Context Links を編集して APM や Logs と適切にリンクされるようにしました。

メンテナンス性の向上 – 適切なグルーピング
Dashboard のメンテナンス性は引き出しに整理整頓していくようなもので、その引き出しがなんのためのものかがわからなければ新しい物を置くときに困ってしまいます。
メンバーが誰でも手動で編集できてしまうため、シンプルに保つことが大切です。
Datadog Dashboard は Empty Group と呼ばれる Widget によって複数の Widget を 1 つのまとまりとして視覚的にグルーピングできます。
2 段階以上のグルーピングができない点は不便ですが、Dashboard v2 では Text Widget と組み合わせてサブグループも表現しました。
ここで意識したのは Widget を追加するときにどこに追加すればよいかが明示的であるように視覚的なブロックを作成することで、誰が追加しても同じ様になるような簡潔さとグルーピングを実現しました。
例えば以下は簡単な例ですが、縦軸にマイクロサービスが、横軸に Metrics が並んでいることは誰でも一目で理解できます。
ある開発で新しいマイクロサービスへの依存が増えたとき、一行下に追加すれば良いことは明らかで、ただ 9 つの Widget を端から並べるより可視性もメンテナンス性も向上します。

これらは今回実施した改善の一例ですが、新しい Dashboard は on-call 対応時やインシデントへの反応速度、PdM などの開発者以外のステークホルダーとのコミュニケーションがより早く、より円滑になりました。
多くの不要な Widget を削除することができた結果、300 を超えるWidget は 113 個まで減り、検索性も向上しました。
今後の展望
Widget の CUE 化
今回のプロジェクトでは多くの Widget を新しく作り直す必要があったことから、GUI 上で可視化しながら編集をしました。
私たちのチームでは Datadog Monitors を CUE 言語で管理していることもあり、既存の Widget も同様に CUE 言語で定義し、Dashboard から参照するような形が理想的だと思っています。
これは IaC の考え方と同じですが、Widget が意図せず編集されてしまうことを避けることができます。
また、複数の Widget を編集するときなど、統一的な操作をしたいときにコードとして定義されていることは大きな恩恵をもたらすでしょう。
Monitor の整理と調整
Payment Service の状態を監視する Monitor は 1408 個ありますが、一部の Monitor は設定の不備や厳しすぎるしきい値設定によってアラートが常に発火しているなど、正しくシステムの正常性を表現できていないものもあります。
これは Dashboard の展望とは異なりますが、システムの状態の可視化はすべての Monitor が正しく設定され動いていることが前提にあります。
そのため、チーム内で継続的に Monitor を見直し、しきい値の調整などを通して “正常とは何か” ということを常に定義し続けていく必要があります。
おわりに
今回の記事では私たちのチームにおいて、より安定した決済基盤を社内に提供するために、柔軟性が高く、可視性と診断性に強い Dashboard を作成した話を紹介しました。
マイクロサービス利用者の CUJ を意識しながら、多様な決済手段の組み合わせや依存関係を可視化する仕組みを作成できたことは、今後のより堅牢な決済基盤の開発を支えてくれると信じています。
明日の記事は myoshida さんです。引き続きお楽しみください。
注釈
[1] メルカリグループでは Production Readiness Checklist が存在し、Dashboard を整備することも一定のマイクロサービスをリリースするための条件となっています。
[2] メルカリグループでは Kubernetes のマニフェストを始めとし、Datadog の Monitor や Widget も CUE 言語で定義できる環境が整備されています (ref. https://engineering.mercari.com/blog/entry/20220127-kubernetes-configuration-management-with-cue/)。
[3] 正確には DogStatsD。




