Merpay & Mercoin Tech Fest 2023 は、事業との関わりから技術への興味を深め、プロダクトやサービスを支えるエンジニアリングを知ることができるお祭りで、2023年8月22日(火)からの3日間、開催しました。セッションでは、事業を支える組織・技術・課題などへの試行錯誤やアプローチを紹介していきました。
この記事は、「メルコイン決済マイクロサービスのトランザクション管理を支える技術」の書き起こしです。
@susho:それでは「メルコイン決済マイクロサービスのトランザクション管理を支える技術」というタイトルで、Merpay Payment Platform Teamの@sushoが発表します。よろしくお願いします。

僕の名前は、Shota Suzukiです。社内では、@sushoというアカウントで活動しています。所属は、株式会社メルペイのバックエンドエンジニアです。2018年にメルペイに入社し、その後iDやコード決済のマイクロサービスを開発し、現在はメルコインの決済や会計のマイクロサービスを開発しています。

本日のアジェンダです。最初にメルコイン決済マイクロサービスについて説明し、次にトランザクション管理、リコンサイル、最後にまとめです。

最初に、メルコイン決済マイクロサービスについてです。

これは、お客さまの決済処理を担うマイクロサービスで、主にスライドのようなユースケースが存在しています。

次は、マイクロサービスのトランザクション管理の話です。

一般的に、マイクロサービスを跨いだトランザクションでは、マイクロサービスはデータベースをそれぞれ持っているため、依存先マイクロサービスのデータベースのロールバックを実行できないと思います。
また、2フェーズコミットなどに代表される分散トランザクションでは、リソースの状態をロックする必要があるため、サービスの可用性が下がる可能性があります。
そのため、実行した操作を取り消すビジネスロジックを補償トランザクションとして実装し、それらを最後まで順次実行する結果整合性というアプローチを取っています。

次に、Sagaについてです。これは、結果整合性を使ったアーキテクチャの一つと言われています。弊社でもこれを採用していて、トランザクションを複数のトランザクションに分割し、それらを順次実行します。
途中でリトライ不可能なエラーが発生したら、逆処理となる補償トランザクションを順次移行していくことを指します。自分たちで開発しているマイクロサービスでもこのアプローチを採用してトランザクションの設計をしています。
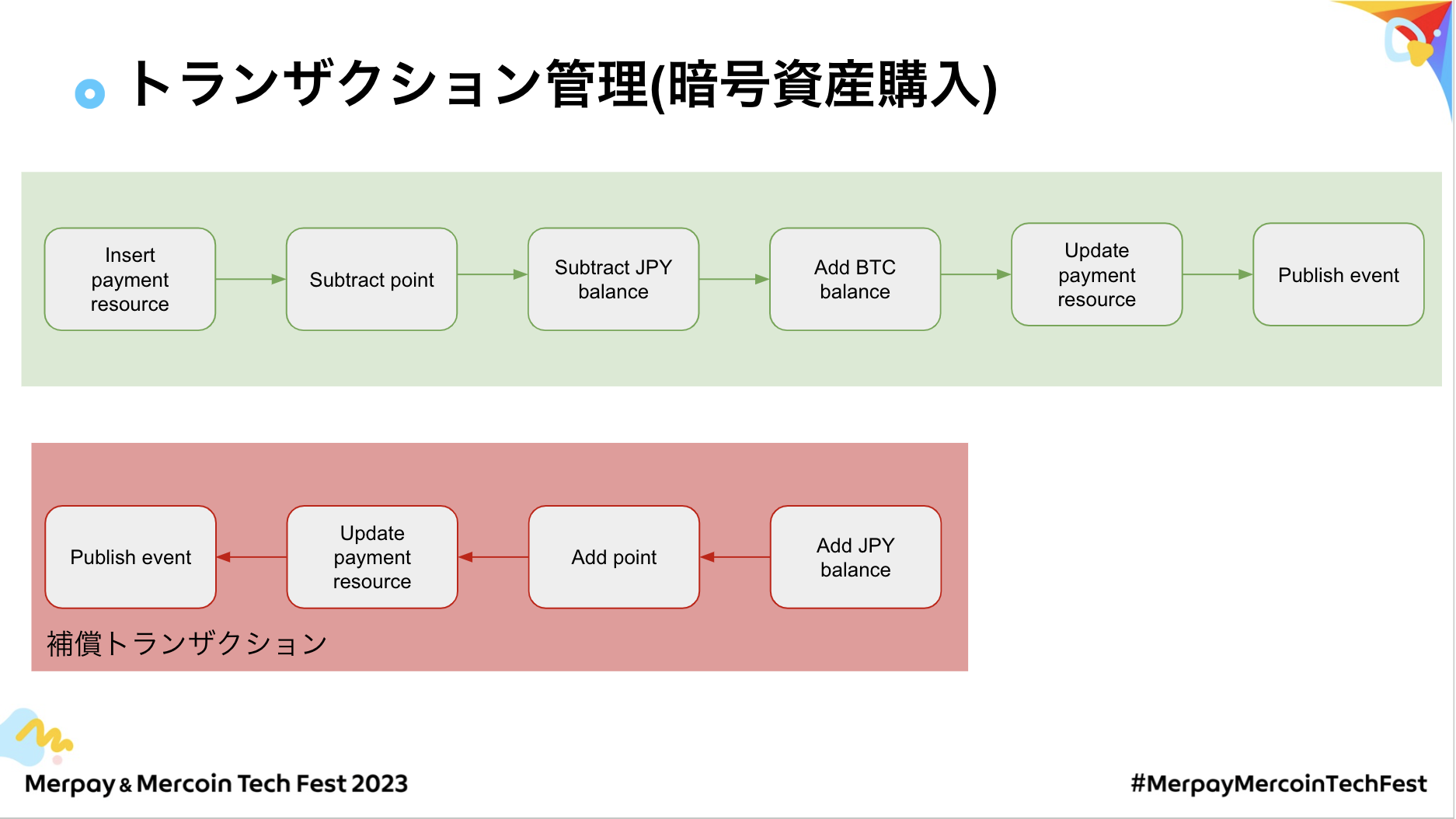
トランザクション管理がどのようなものかを、メルコイン決済マイクロサービスの「暗号資産購入」というユースケースに絞って説明します。
左上から見ていくと、決済マイクロサービス自身で状態を管理したいので、自分たちのDBにリソースを書き込みます。その後、購入に利用するメルカリポイントの減算処理を実行するのが次のトランザクションです。
それが成功したら、メルコイン残高のJPYを減算します。続いて、加算した分のBTCの残高を加算処理し、自身のリソースを更新します。最後にEventとして、リソースの状態をPublishします。この計六つのトランザクションとなっています。
補償トランザクションの定義は、スライドの通りです。例えばBTCの加算処理を失敗した場合、JPYの減算処理の逆処理となるJPYの加算処理を補償トランザクションとして提起し、メルカリポイントの減算処理の逆処理となる加算処理を次の補償トランザクションとして定義し、その後リソースの更新、EventのPublish処理を定義しています。

続いて、各処理で失敗したときの実行順序を見ていきます。例えば、BTCの加算処理が失敗した場合、JPYの加算処理、メルカリポイントの加算処理リソースの更新、PublishEventの順に実行していきます。

もしJPYの減算処理で失敗した場合には、一つ前の逆処理となるメルカリポイントの加算処理から逆順に補償トランザクションを実行します。

次に、メルカリポイントの加算処理に失敗した場合には、リソースを更新してEventをPublishするという補償トランザクションの実行順になります。
このようにトランザクションの設計をすることで、途中でリトライ不可能なエラーになったとしても、安全にロールバックできます。

これらをどのように実装するかを検討したところ、弊社ではクラウドサービスとしてGCPを利用しているため、オープンソースのプロダクトかGCPの製品が候補として挙がり、スライドにある2つを検討しました。
一つ目は、GCP Workflowsです。これは、各トランザクション処理をHTTPのAPIのエンドポイントとして実装する必要があるので、開発時にユニットテストがしづらいという懸念があります。
またオープンソースの製品であるCadenceやTemporalは、弊社が利用しているCloud Spannerに対応していないため、自社で開発するのが良いという結論に至りました。

続いて、自社で開発したWorkflow Engineのアーキテクチャの概要を説明します。基本的にWorkflow Engineは、アプリケーションサーバーと同じポットやサーバーでデプロイされることを想定しています。
Goランタイムで動くようになっていて、SDK・Libraryのような使い方で利用していくことを想定しています。
アプリケーションはWorkerと呼ばれるものを、ライブラリのインターフェース経由でアクセスします。主に二つのインターフェースを使ってコミュニケーションをします。
一つ目は、Register Workflow Functionです。トランザクションは、Goのコードなので、エンジン側にどのようなWorkflowを使うかを登録します。そのためのインターフェースがこれです。Workerは登録の要求が来たら、自分たちのインメモリのRegistryに格納し、実行するときは、リフレクションを使って実行します。
もう一つが、Workflowを実行するインターフェースです。これが呼び出されると、Workerは、まず最初にEngine Serverと呼ばれる、Spannerで、WorkflowやActivityの実行状態を管理する単純なプラットのgRPCのサーバーなのですが、どのようなインプット・functionネームで実行するかをWorker側がEngine Serverに書き込みます。その後、WorkerはChannelにWorkflowが開始したというEventをPublishします。
するとWorker側はそのEventをSubscribeして、Goのreflect.ValueOf.Call()関数を使って実行します。それが完了したら、WorkerはEngine Serverに実行結果を保存するためにWorkflowのコンプリートのリクエストを投げ、ChannelにcompletedEventを投げます。
その後、Workflowの実行結果を、アプリケーションで確認したい。アウトプットを受け取って、クライアントなどにレスポンスを返したいという要件もあると思うので、Workerは非同期に、アプリケーションが待ち受けている処理にレスポンスを返します。
途中で失敗してコンプリートを呼べない場合も想定されます。その場合はリカバリーWorkerというものが動作し、Engine Serverに対してコンプリートになっていないWorkflowやActivityをリストし、リトライします。このようにして、アプリケーションのWorkflow Engineを実行管理しています。

続いて、それぞれの用語についてまとめました。
Workflowは、複数のActivityを使ったビジネスロジックと定義しています。先ほど説明した、「全体のトランザクション」をイメージしていただければ良いかなと思います。Activityがビジネスロジックの最小単位です。「それぞれのトランザクション」をイメージしてください。

次に、Workerです。Workerはアプリケーションサーバーから要求に従ってEngine Serverへコミュニケーションします。また、ChannelからEventをSubscribeして、Eventの種別に沿った処理を実行します。
リカバリーWorkerは、Workerとほとんど役割が同じですが、完了していないワークの一覧を取得し、トライするものです。
アプリケーションから渡されたGoのコードをインメモリの構造で管理しているのが、Workflow Function Registryです。

続いて、Channelです。これは、WorkflowやActivityの状態遷移Eventハブとなります。
現状では4種類のEventが存在していて、WorkflowStarted、WorkflowCompleted、ActivityStarted、ActivityCompletedの4種類です。StartedはWorkflowを実行するためのEventでこれを受け取ったら、Workerはリフレクトを使って関数を呼び出します。その後Completedが、このEventハブに届くので、完了した後に、アプリケーションレスポンスを返すためのEventです。
ActivityStarted・ActivityCompletedは、Workflowとほとんど同じ利用用途です。
Engine Serverは、Workflowの状態を管理するシンプルなCRUDのgRPCサーバーです。WorkflowやActivityの渡されたインプットやアウトプットも保存しています。
これにより、途中で失敗してリトライするときに、以前まで実行していたActivityのアウトプットが保存されているので、再度実行せずにアウトプットをただ返して冪等に処理することが可能です。

続いて、先ほどの暗号資産購入のトランザクションを、Workflow Engineを使うとした場合の構成を見ていきます。
全体として、「暗号資産購入」というWorkflowを定義し、それぞれのトランザクションをActivityとして定義します。同様に補償トランザクションもActivityとして定義し、これらをどの順序で実行するかをGoのコードで書きます。

コードサンプルを見ていきます。appという構造体を用意し、初期化処理の中で、実行に使うWorkflow、Activityを事前に登録しておきます。
RunSayHelloというメソッドが呼び出された場合を見てみると、これはWorkflowとしてSayHelloを実行して、レスポンスを受け取るシンプルなコードです。
これによってWorkerでSayHelloの関数が実行され、レスポンスを受け取れます。SayHelloの中身を見ると、このSayHelloはHelloというActivityを実行して、そのレスポンスを待ち受けています。
これによってWorkflow SayHelloが実行されて、そのSayHelloは、ActivityHello
を実行するようにアプリケーション側で定義されているので、その順番で成功するまでリトライし続けられ、完了します。
このようにして、先ほどメルコインのユースケースで紹介したWorkflowをGoのコードに落とし込んで実行することで、トランザクション管理をしています。

次はリコンサイルを説明します。

リコンサイルとは、依存先マイクロサービスと整合性が取れているかを突合して検証するプロセスです。

サービスの特性上、お客さまの資産を預かるため、マイクロサービス間で不整合が起きていないことを、トランザクション管理とは別プロセスで検証したいという目的があります。
また、自分たちのマイクロサービスだけではなくて、依存している全てのマイクロサービスで検証しその結果整合性が取れていることを確認した上で、会計処理を実施したいという目的のもと、実行していきます。

そこで開発したのが、Processing Tracerというマイクロサービスです。これはマイクロサービスのリコンサイル処理をフックし、リコンサイル状況の監視・アラートするためのマイクロサービスです。

概要を見ていきます。こちらも、暗号資産購入の場合を想定しています。このときにOrder、Payment、Balanceが、マイクロサービスがこの暗号資産購入の取引に依存しているとします。
Orderがこのトランザクションのエントリーポイントとなるので、まず最初にOrderがProcessingIDというものを生成し、その後Paymentにリクエストを投げるときに、そのProcessingIDをつけます。
その後、PaymentはBalanceにリクエストを投げるときにのProcessingIDをつけます。そうすることで、この三つのマイクロサービスでProcessingIDが伝播されます。
OrderはProcessing TracerにRegister ProcessingIDというAPIを呼び出して、生成したProcessingIDを登録します。
Processing Tracerは、CronJobによって、このProcessingIDがOrderから登録されていることがわかるので、Orderサービス専用のPub/Subトピックに対して、リコンサイルのEventをPublishします。
するとOrderサービスは、トピックに紐づいたサブスクリプションを作成し、リコンサイル処理を実装します。Eventが呼び出されたら、リコンサイル処理が実行されることになります。
中身としては、Paymentに問い合わせてリソースの状態を突合し、OKだった場合は、Processing Tracerにリコンサイルレポートという形で、gRPCのリクエストを投げます。
このとき、OrderはPaymentに依存しているので、レポートの中にPaymentという識別子を付加してレポートを投げます。
そうすることで、Processing Tracerは新しくこのProcessingIDはPaymentに依存しているとわかるので、CronJobによってPaymentのPub/Subトピックに、Eventを投げてPaymentはBalanceと突合します。
その後レポートにBalanceという識別子を含めて投げることで、Processing Tracerは、後でBalanceにPub/SubのEventをPublishして、全体としてリコンサイル処理が伝播されます。
もしBalanceなどがリコンサイルできていなかった場合は、それを補足してSlackにアラートを飛ばす仕組みがあります。

それぞれの用語について説明します。
まず、ProcessingID。これは、リコンサイル処理を一意に識別するためのIDです。基本的に処理のエントリーポイントとなるマイクロサービスが生成し、ユニーク性担保のために生成には専用のSDKを利用します。
Register ProcessingIDは、ProcessingIDを登録するもの。Reconcile Eventは、ProcessingIDが登録され、一定期間後に、マイクロサービスそれぞれのPub/Subトピックに向けてEventを発行するものです。
Report Reconcileは、各マイクロサービスがリコンサイル処理を実施して成功したレポートを送信するものです。アラートは、リコンサイルされていないProcessingIDについて、そのマイクロサービスのオンコールChannelにメッセージを投稿するものです。

最後に、メルコインマイクロサービスのリコンサイル処理について、軽く説明します。
Processing TracerからReconcile Eventを受け取ったら、Paymentは、ProcessingIDから自身のリソースを見つけて、PaymentやBalanceにリクエストを投げます。
このときに自分の状態と依存しているマイクロサービスの状態を突合し、OKだったらレポートを投げます。

最後に、まとめです。

まずトランザクション管理についてです。複数のマイクロサービスを跨いでトランザクション処理を実行するために、Sagaを採用したWorkflow Engineを開発し利用しています。
リコンサイルでは、サービスの特性上、リコンサイルすることで、最終的にその処理が想定通り実行されているかを確認する必要があります。それをProcessing Tracerというマイクロサービスを開発することで処理の共通化をしています。

以上です。ご清聴ありがとうございました。