
こんにちは。メルカリ Infrastructure & Procurement Management Team(IPM)の@bungoです。約1年前の2021年夏からメルカリにJoinして、エンジニア組織のお金の問題に取り組んでいます。
昨日に引き続き、この記事はMercari Advent Calendar 2022 の7日目の記事です。
前回の記事でも冒頭からドル円レートの話でしたが、2022年はロケットのように上昇する為替レートとの戦いでした。クラウド費用の算定根拠になっている為替レートがどんどん変わるので、日本円で見ると短期間でものすごい費用増になります。
2022年の始めは1米ドルが115円近辺、これが2022年11月には147円まで円安に振れました。例として簡単に言うと1,150万円のクラウド費用を毎月払っていたとすると、年末には1,470万円に値上がりしたことになります。

コストが増えていると見えてしまうため、経営層からは非常に強いプレッシャーを受けることになりました。急速に為替が動く局面では、日本円での費用報告だけでは本質を見失う危険があります。最前線で戦うことになった筆者の悩みと格闘の結果のノウハウをお伝えします。
今回は為替影響が大きい局面で、技術投資の本質を見失わないためにメルカリのFinOpsで定義したKPIと、そのKPIを計算するための地道な会計作業のお話です。なお、文中に出てくる数値はすべてデモ用に作成した架空のものです。
トップレベルKPIの定義
パブリッククラウドを利用すると、予算を超えて請求が発生することが多々あります。このコントロールの問題にエンジニア視点でシグナルとなる指標を出せないかと考えました。
FinOpsは、エンジニアリングとファイナンスとプロダクトが協力する技術投資判断の取組です。ステークホルダーとなる全員が一目で理解できるトップレベルKPIが欲しくなりました。
我々は技術投資判断用のスマートなトップレベルKPIとして、”Infrastruncure cost per transaction”を定義し、毎月のエンジニア向け全体ミーティングで定期報告する形にしました。
”Infrastruncure cost per transaction”とはメルカリでの取引1トランザクションあたりにかかるサーバやツールコストの原価です。円建てとドル建ての2種類を計算しています。1ドル付近で記載した数値はすべて架空ですが下の画面のようなイメージです。
Infrastruncure cost per transaction = (サーバー費用 + ツール費用等の月額) / 月間トランザクション数

このハイレベルKPIは、今月の費用総額何百万円、などという会計的なものよりも、桁数が少なくスッキリ頭に入るということでエンジニアだけではなくCxOクラスからも好評のようです。
さらに、この原価を表すKPIをグラフにすると、以下のような表示になります。
緑の棒が円建て、青い線はドル建て数値です。

上記のグラフ例では、ドル建てで見ると微増なのに円建てだと大きく直近増えている事象を表しています。パブリッククラウドを使っている多くの会社では同じような傾向をしめしているでしょう。
「直近でインフラコストが急増している」という経営企画側からの問合せに対して、エンジニア部門の説明責任として「ドル建てにおいてコスト増を抑えており、増分は為替の影響」と即答できるようになりました。
泥臭い計数管理の作業
このように変動要素をシンプルに削って、トラッキングするKPIを「余計な物はまったくなく、足りない物が一つも無い」スマートな状態にするのは、元となるデータを作る地道で泥臭い作業が必要になります。
ここからはその筋道を紹介します。
コストの明細を作成し、分析していくという、明細コスト情報という基本的なデータ管理を行います。製造業のエンジニアの仕事に例えればBOM(Bill of Materials: 部品表)に近い立ち位置だと思います。
可視化ツールについて
メルカリで利用しているGoogle Cloudに対応したFinOpsツールは、AWSに対しサポートが少し遅れ気味のため、一般的なBIツールを使って課金データに取り組み試行錯誤をしています。
メルカリではFinOpsのBI基盤としてGoogle Looker Studio 旧名Data Studio に加えDomoを利用しています。
FinOpsにDomoを使う理由は主に4つです。もともと経営管理向けダッシュボードツールとして開発された経緯があるため、お金に関するスプレッドシートなどのデータを頻繁に扱うFinOpsと相性が良いと感じています。
- 予算マスタ表となるCSVやGoogle Sheetのピボットデータをハンドリングするのが楽
- ノーコードでデータ変換のETLを高速開発できることができる
- 定期的なデータ読み出しとデータ変換でダッシュボード管理を自動化できる
- BigQueryからデータを取得し、GoogleSheetの手動入力データを合わせて使える
専用のFinOpsツールを使わず、いまある仕組みでFinOpsをスタートするときは、対前月比・対前年度比とUPSERT処理あたりを解決できる、担当者が習熟しているBI環境を使うと良いと思います。
コスト可視化のためのデータ加工テクニック 初級編
このデータストーリーテリングのダッシュボードのソースデータとするために、メルカリではGoogle Cloudの月次Billing DataをUPSERT処理(後述)で結合した蓄積型データとして保存しています。
このBilling Dataに対してGoogle Cloudプロジェクトごとに前月比計算を行って、どのプロジェクトでどれだけ増えたかを表示しています。
差分表示でいちばん良く使うのは、MoM(Month on Month 対前月比)です。経営レポートではおなじみです。SQLで集計するには、会計エンジニアが良く使うMoM/YoY計算のテクニックを利用します。
SQLのWindow関数で、N行前の数値を返すLAG関数を利用します。具体的には利用月を昇順にしてCostをLAG ,1します。パーティションをプロジェクト単位に設定してあげると、プロジェクトごとにCost LastMonthのカラムに先月の数値が入ります。
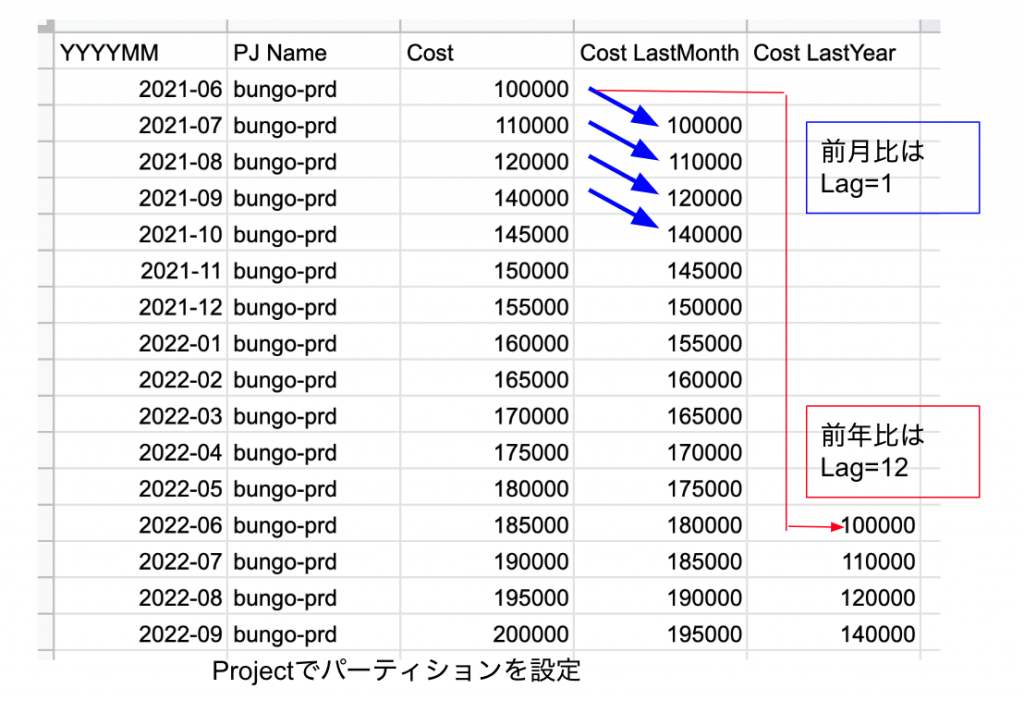
上のような表になったところで、当月-前月の計算をすると、対前月比を算出できます。前月と当月の差分が出る、というだけの簡単なことで、一般的な棒グラフにアクセントがつくようになりました。棒が綺麗に並んでいれば良いですが、突然おかしな動きの線が出ているときは要注意です。
次のグラフは、サンプルデータを元に可視化したもので、対前月比を青線で出しています。注目すべきは青線が上向きにはねているところです。数字や棒グラフだけだと見落としがちなマイナーな部分でも、青線でスパイクしている表現を加えることでで、何かが起きたと気がつくことが出来ます。

さらに変化率というシグナルを用意すると、異常発生が一目瞭然です。ヒートマップを使ったり、もっと単純に赤信号や青信号のシグナル表示を作っても良いでしょう。
下の図では、シグナルが赤くなっているところ、緑が濃くなっているところが要注意ポイントです。

UPSERT処理について
先に記載したUPSERT処理について、なじみのない方が多いと思うので簡単に紹介します。
このテクニックは課金データだけでなく、色々なバラバラのデータを扱うのに便利です。
経理チームへの報告用のデータとして、Google CloudコンソールからダウンロードするCSVファイルを利用しています。歴史的経緯により、BigQuery側に連携されている課金データは使えていません。
Google CloudやAWSから毎月提供されるBillingデータは、確定が第5営業日や第7営業日付近なのですが、課金集計システムの挙動により内容は頻繁に更新されます。
経理チームへの費用報告は、第三営業日などもっと早い時期に行わなければいけないビジネス要件があります。
確定したデータであれば、シンプルにデータをUNIONで縦に連結すれば良いのです。しかし更新が行われているのであれば、最新データの再投入をするとデータが二重になりますし、不正確なデータが残ります。
我々が利用するのは、データの再投入時に重複が発生しないようにUPDATE + INSERTをデータに応じて適切に行う、通称UPSERTの処理です。
簡単に説明すると、新しく届いたCSVファイルを送り込んで、蓄積用ファイルに書き込みます。蓄積用ファイルと新しいファイルを照合して、完全に新しい行はそのまま追加。既存の行で金額や利用量が更新されていない行はそのままスキップ。金額が更新された行を検出して、更新された内容で上書きしていく方法です。
下のようなデータフローのETL(Extract, Transform, Load: 主にデータのクレンジングと分析形式への加工を行う)処理を書いて、線をつないで、重複検出の設定を行っています。こんなシンプルなものですが、ちゃんと動きます。

複数CSVファイルでばらばらになったデータをまとめるのは非常に面倒なのですが、UPSERT処理を駆使して1つのデータファイルにまとめられたので、長期間の分析が可能になりました。
BillingデータはGoogle Cloudから直接BigQueryに転送できる日次ベースのデータセットもあるのですが、現状では最終的な請求画面側Billingデータを費用のSingle Source of Truthとして扱っています。可能であればBigQuery側を使った方が、日次データでも分析できるので有利でしょう。
意外な強敵 予算と実績のピボットデータ
メルカリのEngineering部門でも、部門の予算データはスプレッドシートで管理しています。筆者のチームでは単なる予算シートではなく、コスト管理という意味でCost Management Fileと呼んでいます。もちろん入力は心を込めた手作業です。経営企画チームがここの予測値から経営層向けレポートを作成しているので、入力ミスをすると経営企画チームからお叱りを受けます。

問題は、スプレッドシートの構造です。ビジネス要件として、Budget(予算)、Forecast(予測)、Actual(実績)の3つの数字を管理しています。
Actualには社内の会計システムから出力されたデータを入力していきます。予算番号などの突合のキーがあれば一発、と考えるのですが、出力された会計データには様々な事情でうまく突合できないものがあり、この作業が泥臭く非常に大変です。
さらにその後、可視化を行うためのデータ加工があります。
これをBIツールで可視化するためには、ピボット表を変換しリスト形式でDBに格納するためにunpivotの処理が必要になります。unpivotの処理は、上に示した表A(横もちスプレッドシート形式)から、下に示した表B(データベース格納形式)への変換のことです。
サンプルのスプレッドシート表(表A)を見ていただくと気がつくかもしれませんが、年月ごとに3つの要素(Budget,Forecast,Actual)があり、データベースに格納するには、これらを縦(Typeカラム)に展開しなければいけません。
さらにクラウド費用は米ドルベースでの請求が多く、最近は為替レートが急速に動くため、日本円での比較、日本円の税抜費用から各月為替レートで割り戻した米ドルでの比較なども必要になります。

unpivotはBigQueryでも最近ようやくunpivotの機能が付きましたが、基本的にはSQLでCase文を書いて処理することになるとおもいます。
BIツールの周辺環境、例えばExcelであればPower Query、Tableau Prepなどではunpivotをメニューから行えます。メルカリではカラム名を工夫し、Domoの便利なデータ加工機能であるMagic ETLにあるunpivotの処理と文字列操作をすることで実現しています。DomoではノーコードとSQLの両方でETL処理を作成できます。(Link: https://www.domo.com/jp/data-integration/features/etl-tools) もちろん、少ないステップ数でunpivotしやすい元のピボット表を設計するところがエンジニアとしての腕の見せ所です。
予算管理者が入力しやすいピボット表を、DBで処理できるリスト形式にした状態で、BIツールに送り込めば、予算と予測と実績が表示されます。
実績が予算とずれたら、何が原因で予算とずれたのか乖離分析を行います。
経営企画チームより提供された直近の業績予測値を元に、トランザクション予測に連動する将来のプラットフォーム費用を予測しForecastに反映します。
このように、経営企画チームと連携して会計期末の費用着地点をタイムリーに提供できる仕組みを作っています。更に絞り込み検索で、どの項目が予想外だったか、その原因は何かと毎月分析します。

<グラフ> 予算と実績の乖離分析。ここで差があれば原因を追いかけていく
正確にお金を扱うことは当然のことなのですが、Webエンジニアをしてきてあまり要求されてこなかった会計知識を当然のように求められて、費用の正当性について経営側に説明をしなければいけなくなった非常にしんどい経験をした1年間でした。
しかし努力の結果として、ツールを使っていないのに登録されているアカウントを見つけて費用を下げることに成功したり、安全率にとったリソースの割り当てが大きすぎたところなどを適正化するなど、大きなコスト最適化につながりました。
現在はもっとTech寄りなテーマとしてコンテナ環境のコンピュートリソース利用率向上や、Commited Use Discountの有効活用、データのリテンションポリシー設定などSREの領域で熱い活動成果が出ています。これらは今後別の記事でご紹介していこうと思います。
最後に、このFinOpsの活動を行う中で読んだ本をご紹介します。私も自動翻訳を活用しながら読みました。おすすめします。
Cloud FinOps
https://www.oreilly.com/library/view/cloud-finops/9781492054610/
Effective Data Storytelling
https://www.effectivedatastorytelling.com/
お金を扱う上で当たり前のことを当たり前に行うのが、筆者のようなエンジニアにとってはこんなに大変なのかと毎日かみしめながら仕事に取り組んでいます。メルカリグループではFinOpsに取り組みたい技術とお金を深く理解したエンジニアを募集していますので、ぜひ採用情報ページからエントリーをしてください。
明日の記事担当はWeb Architectチームのwillsとfaisalです。引き続きお楽しみください。




