
Merpay Tech Fest 2022 は、事業との関わりから技術への興味を深め、プロダクトやサービスを支えるエンジニアリングを知ることができるお祭りで、2022年8月23日(火)からの3日間、開催しました。セッションでは、事業を支える組織・技術・課題などへの試行錯誤やアプローチを紹介していきました。
この記事は、「Kubernetesの上に作る、統一されたマイクロサービス運用体験」の書き起こしです。
「Kubernetesの上に作る、統一されたマイクロサービス運用体験」というタイトルで発表します。よろしくお願いいたします。
まずは自己紹介です。メルペイSREチームのtkuchikiと申します。

Cloud Spanner周りの業務に従事しており、Spanner-autoscalerというOSSのメンテナンスをしています。Goでツールを書くのが好きで、趣味でALPというログ解析ツールの実装なども行っています。
それでは、本セッションのAgendaです。

はじめに、メルペイのマイクロサービス運用がどのようなものなのか、マイクロサービス運用の課題、サービスの規模、マイクロサービスの基盤、メルペイSREの役割について説明いたします。
次に、マイクロサービス共通のインフラの運用を行っているメルペイSREチームが、運用にもConfiguration as Dataのような仕組みを提供して、運用体験の向上に取り組んだ事例を2つ紹介します。
そして最後に、運用の仕組みをKubernetes上に統一するメリットをご紹介いたします。
メルペイのマイクロサービスの運用

はじめに、「メルペイのマイクロサービスの運用」についてお話します。

まず、マイクロサービスの運用における課題についてです。マイクロサービスでは、スケーラブルな組織を作るために、各チームでオーナーシップを持って開発から運用まで行います。
しかし、チームごとに運用を任せてバラバラな仕組みを作ってしまうと、ツール開発コストの増大や、共通の運用ルールを適用できない、SREがフォローできないといった問題が発生します。そこで、各マイクロサービスを運用するプラットフォームを構築し、そのうえで運用を行うことで、マイクロサービスごとに仕組みを作る必要をなくしたり、共通の運用ルールを適用したりしています。

メルペイのサービスは、マイクロサービスプラットフォームの上で、60以上のMicroservicesと1,000以上のKubernetes podsスポットで稼働しています。

メルペイのマイクロサービスは、メルカリのMicroservices Platform Teamが構築・運用しているプラットフォーム上で稼働中です。このプラットフォームでは、開発者がオーナーシップを持ってサービスを構築・運用するために、Infrastructure as CodeをTerraformで実践しGCPリソースを管理する仕組みや、Configuration as DataをKubernetes上のリソースをYAMLで管理することで実践する仕組みが整っています。
TerraformとKubernetesのリソースはGitOpsを行っているので、GitHubへのPull Requestをマージすると、applyされるようになっています。また、KubernetesへのデプロイはSpinnakerを使用しています。
先ほどのスライドで、IaCとCaDというワードが出てきました。IaC(Infrastructure as Code)は、聞き覚えのある方が多くいらっしゃるのではないかと思いますが、CaD(Configuration as Data)はまだそれほど普及していない概念のように思いますので、ここで軽く触れておきます。

Configuration as Dataは、「インフラストラクチャーをあるべき状態を宣言したデータとして管理する」という概念です。CaDを実践しているKubernetesを例に考えると、Kubernetesのユーザーは、デプロイメントなどのリソースをYAMLで記述して管理しています。しかし、実際にリソースを作成するのはKubernetesのコントローラーです。このように、データとデータを扱う層を明確に分けるというアプローチです。GCPのリソースをKubernetesのリソースのように管理するためのConfig Connecterというコントローラーもあります。
マイクロサービスプラットフォームの運用は、メルカリのマイクロサービスプラットフォームチームが行っているのであれば、メルペイSREチームの役割は何でしょうか。
参考資料:https://cloud.google.com/blog/ja/products/containers-kubernetes/understanding-configuration-as-data-in-kubernetes

それは、SLO運用の推進やマイクロサービスプラットフォーム上での運用サポート、マイクロサービス共通のインフラの運用などです。メルペイSREチームは、運用サポートの取り組みとして、マイクロサービス開発者の運用体験向上に取り組んできました。その中で、運用にもCaDのような仕組みを取り入れ、提供しています。
本セッションでは、運用体験向上のための取り組みとして、二つの事例を紹介いたします。
Kubernetesカスタムコントローラーを活用したCloud Spannerのオートスケール

一つ目は、「Kubernetesカスタムコントローラーを活用したCloud Spannerのオートスケール」機能を提供し、運用を自動化している事例です。
事例の紹介に入る前に、Cloud Spannerについて触れておきます。

Cloud Spannerは、GCPのフルマネージドリレーショナル・データベースです。
https://cloud.google.com/spanner

ダウンタイムなしでNodoを増減可能となっており、簡単にスケーリングできます。メルペイではマイクロサービスの標準的なデータベースとして利用しています。

Cloud Spannerを運用していると、Nodeを増減させたいケースが度々発生します。

メルペイではTerraformでCloud Spannerを管理しているので、Nodo数を変更したい場合は開発者がPull Requestを作成し、CI経由でterraform applyを実行するというフローになります。
このとき、リソースが余っていてNodoを減らしたいケースでは問題になりません。しかし、トラフィック増などで負荷が増大し、Nodoを増やしたいケースでは対応完了までの速度が問題となります。Pull Requestを作成し、CIが完了するのを待ち、それをレビューし、Pull Requestをマージして、terraform applyを実行するCIが完了するのを待つ。そんなフローになるため最短でも10分程度はかかります。そのため、CPU使用率が特定の閾値に達した場合に、自動でスケールアップする必要があると感じました。

オートスケールを実現するために、まず、GCPプロダクトを組み合わせて実装する方法を検討しました。CPU使用率のメトリクスを取得して特定の閾値に達した場合にNodoを増やす処理を定期的に実行するには、Cloud Scheduler、Cloud Functions、Cloud Monitoringを活用することで実現できます。

GCPプロダクトを組み合わせてオートスケールを実現する場合、二つの運用方法が考えられます。一つ目は、各マイクロサービスで運用することです。メルペイでは、マイクロサービスごとにGCPプロジェクトを作成し、そのGCPプロジェクトでCloud Spannerを稼動しています。マイクロサービスのオーナーシップを考慮すると、自分たちのGCPプロジェクトでオートスケール処理を実行させることは、自然なことのように思えます。
二つ目は、オートスケールする処理を一つのGCPプロジェクトで実行し、複数のGCPプロジェクトのCloud Spannerを管理することです。この場合、各マイクロサービスの開発者が運用するのではなく、中央集権的にSREが運用することになります。
このように、GCPプロダクトを組み合わせることで、オートスケール処理を実行できそうです。しかし、二つの実現方法には、それぞれ懸念がありました。

まず、各マイクロサービスで運用する場合、開発者が運用するものが増えてしまいます。オートスケール機能は、マイクロサービスを運用する上で必要なものですが、開発者はプロダクトの開発に集中できることが望ましいです。
そこで、開発者がプロダクトの開発に集中するために、中央集権的な運用を選択した場合、SREの負担が増加します。また、オートスケールの設定を追加・変更する度に、SREのレビューが必要な状況では、開発者のオーナーシップを損なってしまいます。

GCPプロダクトの組み合わせは最適ではなさそうだったので、別の方法を検討しました。そこでKubernetesに着目したのです。DeploymentやConfigMapのようなKubernetesリソースとして管理できれば、リソースのレビューやデプロイをマイクロサービスのチーム内で行うという既存の運用フローに乗せることができます。
Kubernetesリソースとして、オートスケールの設定を管理するためには、Kubernetesカスタムコントローラーを実装する必要があります。
Kubernetesカスタムコントローラーは、ユーザーが独自に定義したリソース=カスタムリソースに対する処理を行うコントローラーです。Reconcilation loopという仕組みで、宣言した状態と実際の状態等を比較し、あるべき状態に同期し続けます。

スライドの図は「Managing Kubernetes」という書籍からの引用です。現在のリソースの状態を取得して、ユーザーが宣言した状態に合わせて、現在の状態を変更するという一連の流れを示しています。
Reconcilation loopの処理をCloud Spannerのオートスケール処理に当てはめてみましょう。現在のNodo数を取得して、ユーザーが宣言したあるべきNodo数に変更し続けると考えると、オートスケールの処理そのものです。そして、これはKubernetesを運用している人には馴染み深いHorizontal Pod Autoscaler(HPA)と似ていることに気がつきました。
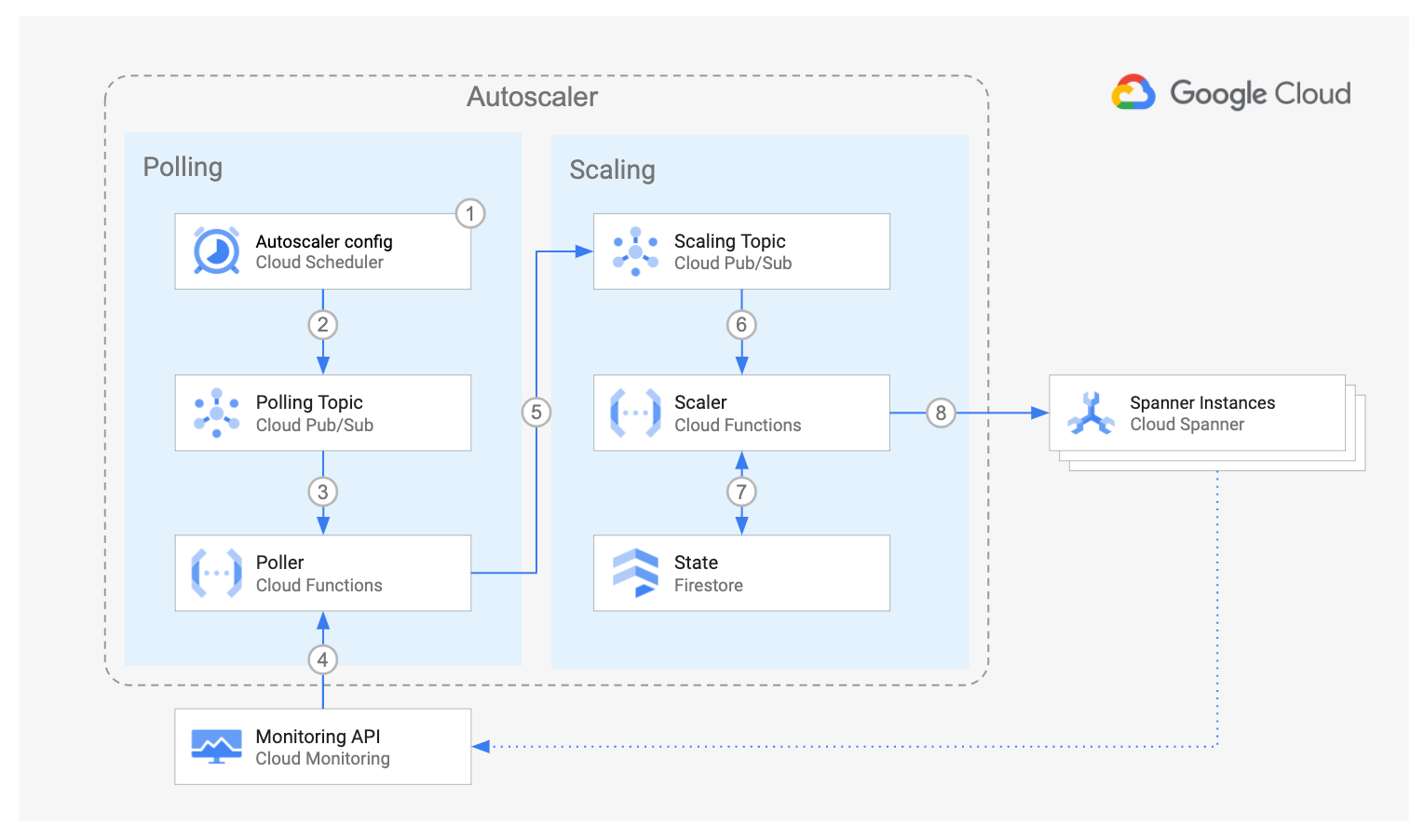
方向性が正しいことに確信を持ったのでHPAのように機能しつつ、Cloud Spannerをモニタしてスケールしてくれる、Kubernetesカスタムコントローラーを実装しました。そして、spanner-autoscalerという名前でOSSとして2020年6月に公開しました。
https://github.com/mercari/spanner-autoscaler

2022年4月に、スケジュールを設定して一時的にNodoを増やすことができるScheduled Scaling機能をリリースしています。

spanner-autoscalerを活用した、マイクロサービスの運用を図に示しました。SREはspanner-autoscalerだけを管理している状態なので、マイクロサービスが増えても負担は増加しません。開発者はspanner-autoscalerカスタムリソースを作成するだけでよく、その作業はチーム内で完結するため、オーナーシップも損なわれていません。
それでは、一つ目の事例のまとめです。

Cloud Spannerをしばらく運用していると、Nodoを増減させる運用フローに課題があることがわかりました。この課題の解決には、オートスケール機能が必要であったため、検討した実現方法を示し、我々が実際にどのような方法を選択したのかお話しました。現在、spanner-autoscalerを導入したことで、開発者がオーナーシップを持ってオートスケールの設定を管理できるようになっています。
Cloud Spannerに詳しい方であれば、Google公式のautoscalerがあるのになぜそれを使用していないのか、疑問に思ったのではないかと思います。そのため、公式のautoscalerについても軽く触れておきます。

GCPプロダクトを組み合わせてCloud Spannerをautoscaleするもので、2020年9月頃にリリースされました。spanner-autoscalerはCPUタスク優先度高のみをスケーリングのメトリクスとして使用していますが、公式のautoscalerはそれだけでなく、CPU使用率の24時間稼働平均と、ストレージの利用率でもスケーリングが可能です。
https://github.com/cloudspannerecosystem/autoscaler

スライドはアーキテクチャ図です。それぞれのコンポーネントが何を示しているかの詳細の説明は割愛しますが、GCPプロダクトを組み合わせて、Cloud Spanner autoscaleしたい場合はこれを使うのが良いと思います。
しかし、メルペイでは公式のautoscalerは採用しませんでした。

理由としては、我々がGCPプロダクトを組み合わせてautoscalerを実装することを検討したときに挙げた問題が同様に発生しそうだったこと。現状のKubernetesリソースとして、オートスケールの設定を管理できる状態の方が、運用体験が良いと判断したためです。
SREマネージドなコンテナイメージを利用したCloud Spannerバックアップ

それでは、二つ目の事例紹介に移ります。「SREマネージドなコンテナイメージを利用したCloud Spannerバックアップ」の運用改善についてです。
事例の本題に入る前に、Cloud Spannerのバックアップについて触れておきます。

Cloud Spannerには二つのバックアップ方法があり、それぞれバックアップ、エクスポートと呼ばれています。

バックアップは、インスタンスのサーバーリソースを利用しない専用ジョブを使用してバックアップが実行されるため、パフォーマンスに影響はありません。しかし、バックアップデータがインスタンスに紐づいているため、移動不可能。また、最長で1年間しか保存できません。
対して、エクスポートは優先度が中のタスクとしてクエリを実行するため、多少パフォーマンスに影響がある可能性があります。しかし、任意のストレージ上でデータを保管可能で、削除するまで保存できます。
メルペイではディザスタリカバリーとデータの保持期間の要件のため、エクスポートを選択しています。Cloud Spannerには、これら二つのバックアップを自動で定期的に実行する機能はありません。そのため、Webコンソール上から操作するか、APIを実行する必要があります。定期的なAPIリクエストの送信は、Cloud Schedulerを使用することで実現可能なため、Cloud Schedulerと組み合わせることでバックアップの自動取得は可能です。
このように、Cloud Scheduler単体でもバックアップの取得は可能ですが、エクスポートジョブ失敗時にSlack通知したり、エクスポートジョブの実行時間を計測したいという要件があったため、ツールの実装を検討しました。

ツールを実装するときの選択肢としては、App EngineのCronサービスや、Cloud SchedulerとCloud Functionsの組み合わせ、Cloud SchedulerとCloud Runの組み合わせなどが考えられます。App Engineの経験が多いメンバーが複数人いたため、App EngineのCronサービスを採用しました。
しかし、App EngineでのCloud Spannerの自動バックアップを運用してしばらくすると、問題が発生しました。

開発者はApp Engineを操作する権限を持たないので、SREが設定していました。また、設定を更新した場合もSREへの依頼が発生し、マイクロサービスが多くなるにつれてSREの負荷が増えていったのです。

そこで、バックアップ取得の運用の改善に取り組み始めました。

バックアップの管理を開発者だけで行えるようにするという観点では、CI経由でのデプロイパイプラインを構築することで問題を解決できそうではあります。
しかし、App Engineは、バックアップ取得のためにしか使っていないため、デプロイパイプラインもこれ専用のものとなってしまいます。仕方がないこととはいえ、やりたいことに対してのコストが高く感じてしまいます。
また、アプリケーションの設定はKubernetesのYAML。バックアップの設定はそれ以外の場所で管理するとなると、管理するものが増えて、運用の手間が増える懸念があります。
そこで、既存の仕組みに着目しました。

KubernetesへのデプロイはSpinnakerで行っており、SpinnakerのデプロイパイプラインをYAMLで作成する仕組みがプラットフォーム上にあります。そのため、エクスポートジョブの実行も含めてKubernetes上で行うことで、デプロイパイプラインの構築からバックアップの設定まで、一貫してYAMLで定義することが可能になります。また、KubernetesのDeploymentなどもYAMLで管理しているため、アプリケーションと同じように管理でき、マイクロサービスと同様の運用体験を提供できます。

方針が固まったので、改善に取りかかりました。今までApp Engineで稼働していたものをKubernetes CronJobで実行するためには、コンテナイメージが必要になります。まず、いくつかのマイクロサービスに導入した際、マイクロサービスごとにイメージを作成する方法を試しました。
マイクロサービスの原則から考えると、この方法は自然なものだったと思います。しかし、バックアップ専用のDockerfileを作成してイメージをビルドするのは手間がかかります。また、イメージの中身は同じなのに、各マイクロサービスでそれをホスティングするというのは無駄が多いように感じます。そのため、SREが作成したイメージを各マイクロサービスで使用するという運用にしました。

SREマネージドなコンテナイメージを使用したバックアップの運用を、図に示しました。
SREはコンテナイメージだけを管理している状態なので、マイクロサービスが増えても負担は増加しません。開発者はYAMLを作成するだけでよく、その作業はチーム内で完結するため、オーナーシップも損なわれていません。
二つ目の事例のまとめです。

メルペイのCloud Spannerのバックアップ取得の運用は開発者がオーナーシップを持って運用できておらず、SREの負荷が高い状態でした。そこで、開発者自身でバックアップの設定ができるように環境を整備し、開発者のオーナーシップを損なわずSREの負荷を軽減した事例を紹介しました。
運用の仕組みをKubernetes上に統一するメリット

最後に、二つの事例を通して「運用の仕組みをKubernetes上に統一するメリット」をお話します。

まず、運用するものをKubernetes上にまとめることで、それらを全てYAMLで表現できるようになります。そのため、開発者はYAMLを管理するだけでよくなり、作業が手軽になります。また、管理するものが増えてもベースとなるのはYAMLでの設定になるので、ツールごとにキャッチアップすべきことが少なく運用の負担も減ります。

そして何より、設定がチーム内で完結するため、オーナーシップを損なわないという利点があります。
メルペイSREチームでは運用の仕組みを設計するうえで、このことを重視しています。多くのマイクロサービスを運用するうえで各チームがオーナーシップを持って運用できる環境が整っていることは、スケーラブルな組織を作るために必要不可欠であるためです。また、SREにとっては、トイルを減らして、別のエンジニアリングにフォーカスできるというメリットがあります。
まとめ

それでは、本セッションのまとめです。
運用体験向上のために、運用にCaDの仕組みを取り入れた事例を二つ紹介しました。そして事例の紹介を通して、運用の仕組みをKubernetes上に統一することでYAMLを書いて、デプロイするだけの手軽さと、開発者のオーナーシップを損なわない運用体験を提供していることを紹介しました。

本発表が皆様の運用の参考になれば幸いです。ご清聴ありがとうございました。






{kind=link}