Mercari advent calender の21日目を担当します@sanposhihoです。現在大学の学部4回生で、メルカリでは内定者インターンとして、メルカリのホーム画面などのバックエンドを担当するチームに所属しています。
また、最近は個人的にKubernetesやその周辺のOSSにコントリビュートをしていて、特にKubernetesのコントロールプレーンのコンポーネントのうちの一つであるkube-scheduler周りを触ってることが多いです。
後で詳しく説明しますが、kube-schedulerはPodをどのNodeで実行するかを決定しているコンポーネントです。NodeAffinityや比較的新しいものだとPod Topology Spread Constraintsなど、Podのスケジュールの制約を指定できる機能も基本的にこのkube-schedulerに実装されています。
この記事では簡略化されたkube-schedulerを自作する様子を通して、
- 内部的にどのような仕組みでkube-schedulerが動作しているのか
- kube-schedulerがどのようにユーザーに拡張性を提供しているのか
をざっくりと理解することを目標とします。
この記事を読み終わると、kube-schedulerの内部実装もざっくり読めるようになり、kube-schedulerの拡張(プラグイン(後述)の作成など)なんてちょちょいのちょいでできるようになるはずです。
この記事の想定読者は”KubernetesはPod(一つ以上のコンテナ)をどこかのNode(マシン)で実行する君である” ことを知っている人です。また、Goで実装を行うので、Goが読めると理解が早いと思います。
実装例を中心としてその主要な箇所の解説を行っていきます。実装例を参考にして手を動かしてもらうとよりよい学びになると思います。
かなり長い記事になりますが、年末年始のお供などとしてkube-schedulerと一歩お近づきになってみませんか?
似たような内容でCloudNative Days Tokyo2021で登壇しました。アーカイブが公開されているので、こちらも興味がある方は御覧ください。この記事ではより詳細に中身を調べていきます
この記事の解説はKubernetes v1.22.0時点のkube-schedulerをもとにしています。
また、この記事ではPodのスケジュールを行うものを総称としてスケジューラーと表記し、そのうち、Kubernetesに標準で搭載されているスケジューラーをkube-schedulerと表記します。
kube-schedulerとは
さて、まずは座学から入りましょう。
kube-schedulerとは前述のようにPodをどのNodeに割り当てるかを決定するコンポーネントです。
その時の様々なリソースの状況を見たり、ユーザーが指定したPodのスケジュールの制約を鑑みたりしつつ、Podに最適なNodeを決定しています。
Kubernetes Scheduler | Kubernetes
Podのスケジュールに対する制約を指定する方法はNodeAffinity、Pod Topology Spread Constraints、PriorityClassによるPodの優先度指定など、複数あります。
Scheduling Framework
kube-schedulerは内部的にScheduling Frameworkという仕組みに沿って動いています。
これはv1.19でstableとなった、比較的新しい仕組みです。
Scheduling Framework | Kubernetes
Scheduling Frameworkは以下のような図の通りに動作しています。(上記のKubernetesの公式のドキュメントから引用)
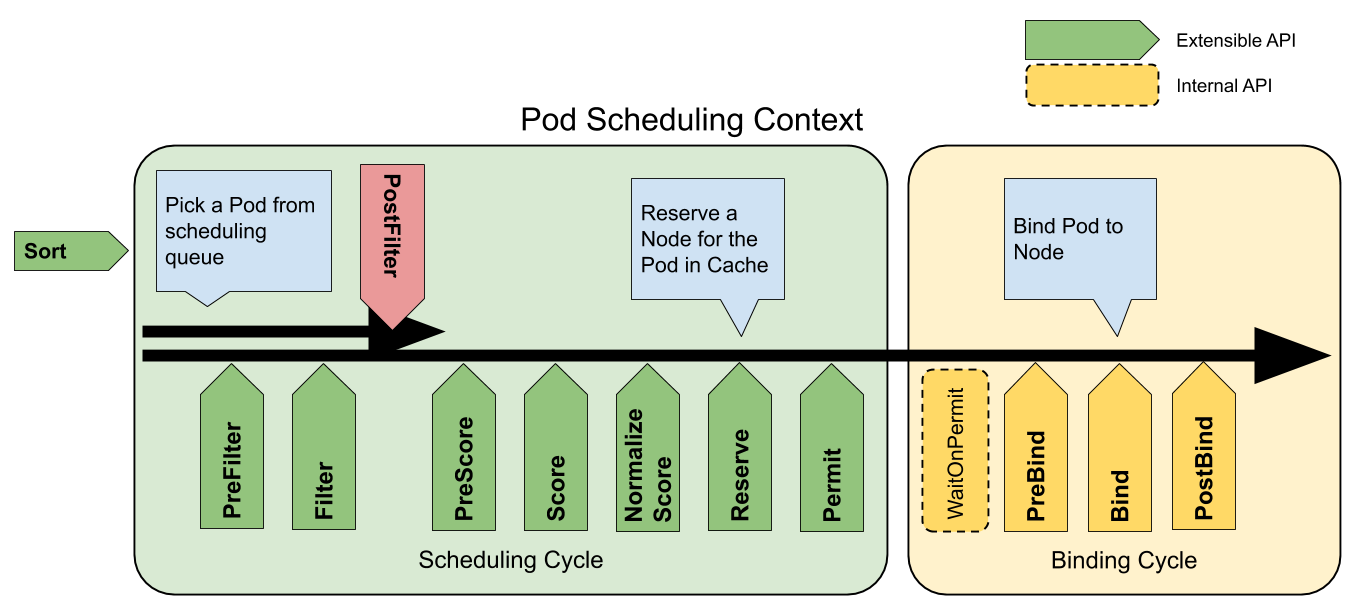
Scheduling FrameworkではSchedulerの各機能がそれぞれプラグインという形で実装されています。
Extensible APIとされて列挙されているのが、プラグインが実行可能な拡張点で、プラグインはそれぞれ一つ以上の拡張点で動作します。
例えばPod Topology Spread Constraintsはv1.22現在、preFilter、filter、preScore、scoreの拡張点で動作することで機能を提供しています。
このようにプラグインとして機能が実装されている理由はいくつか存在します。
- ユーザーが自分でスケジューラーを作る際にScheduling Frameworkに沿って開発することで、kube-schedulerが持つ各機能をプラグインとしてimportでき、再実装しなくて済むこと
- ユーザーがスケジューラーに独自の機能を追加したいときにプラグインとして適切に実装し、kube-schedulerにオプションから追加することで、スケジューラーの複雑な実装に触れることなく、kube-schedulerを拡張できること
などです。
スケジュールを行う必要があるPodはkube-schedulerの内部でQueueのような形で保存されており、kube-schedulerはそのQueueから一つずつPodを取り出してスケジュールを行っていきます。
各拡張ポイントはそれぞれ役割が異なります。ここからはその代表的なものだけを紹介します。(先程も挙げたScheduling Framework | Kubernetesにすべての拡張点の解説が載っています)
Filter
FilterではプラグインがPodを実行できない(したくない)Nodeを候補から除外します。
例えば、
- リソース不足でPodが実行できないNodeを除外する
- nodeSelectorの条件に一致しないNodeを除外する
などのプラグインが存在します。
Score
Filterよりも後で実行されるScoreでは残った候補をスコアリングします。
例えば…
- 全体のNodeのリソースの使用量のバランスがちょうど良くなるNodeに高い点数をつける
- Podを実行するコンテナイメージをすでに持っているNodeに高い点数をつける
などのプラグインが存在します。
図でスケジュールの様子を見る
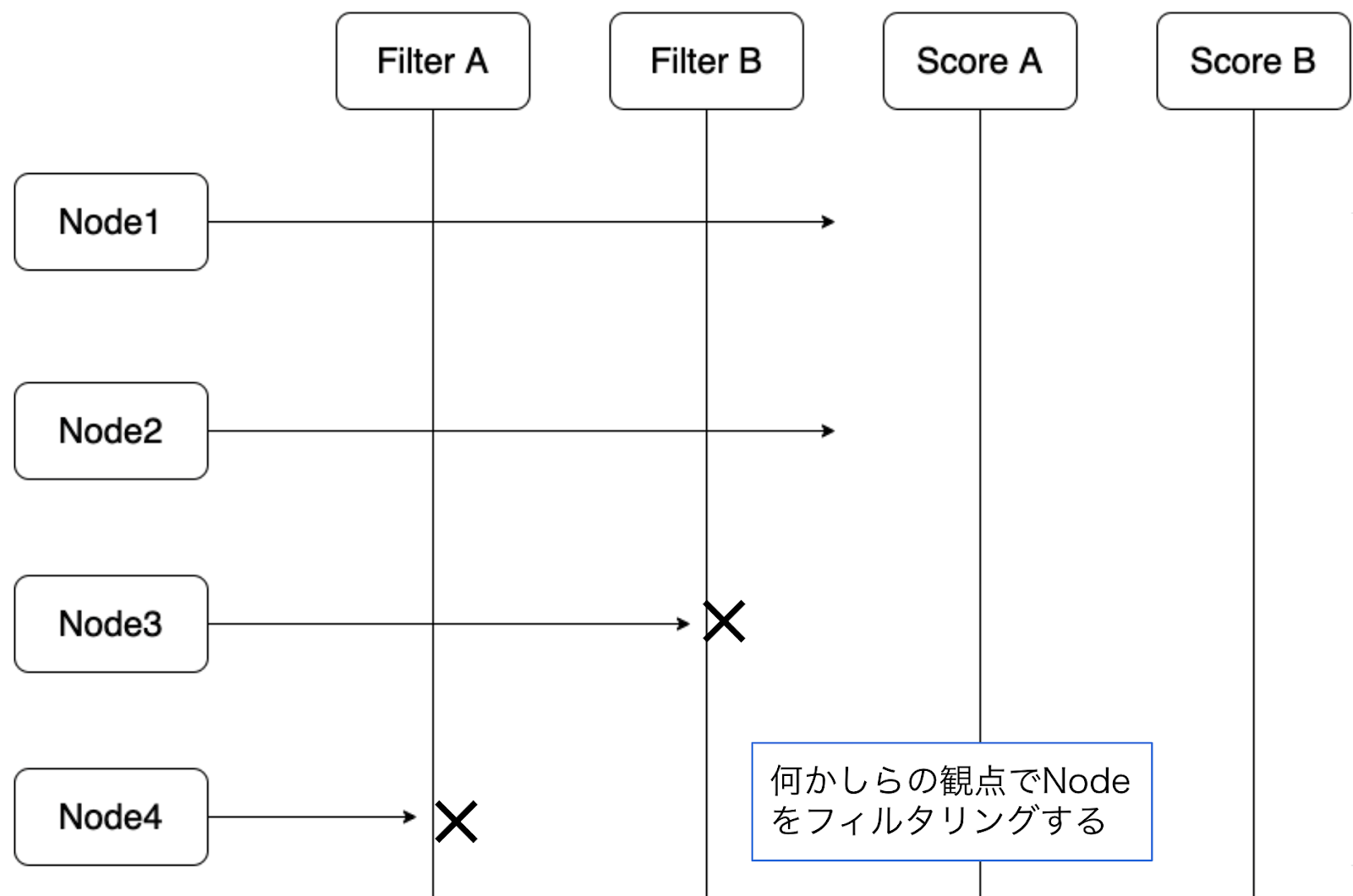
では例として図を通してFilterとScoreを中心にどのようにスケジュールが行われるかを見てみましょう。
とあるPodのスケジュールが開始され、クラスター上にNode1 ~ Node4が存在していたとします。
また、Filter拡張点で実行されるプラグインとして、Filter A, Bプラグイン、
Score拡張点で実行されるプラグインとして、Score A, Bプラグインが存在しているとします。
ここでは単純にするために、このような例にしていますが、前述のようにFilterとScoreの両方の拡張点で実行されるといったような複数の拡張点で動作するプラグインが実際には存在することに注意してください。
まずは、全ての候補のNodeに対して、Filter A, Bプラグインがそれぞれ何かしらの観点でOKかどうかを確認します。Filter Aプラグインの観点だとNode4が、Filter Bプラグインの観点だとNode3が現在対象としているPodにそぐわないと判断したようです。
その後、残った候補であるNode1とNode2に対してScoreA, Bプラグインがそれぞれなにかの観点でスコアを付けます。
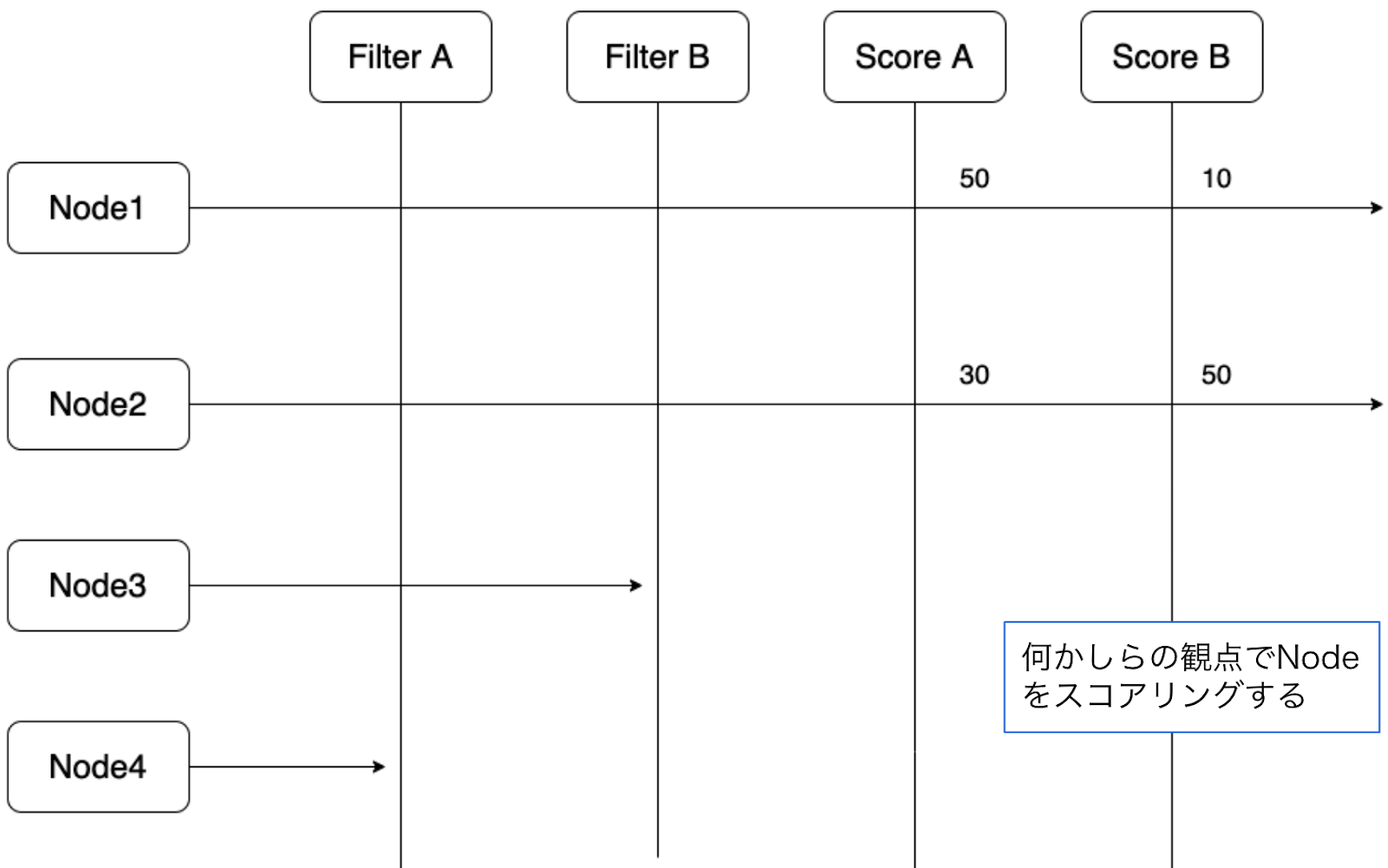
この得点を集計し、Node2が総合得点が大きいため、Podが実行されるNodeとして選ばれることになります。
この記事では簡単のために詳しく紹介しませんが、実際にはScore拡張点の得点がプラグインごとの重み付けやNormalized Score拡張点の結果などによって変化します。
Scheduling Cycle と Binding Cycleについて
先程のこの図にもう一度目を向けましょう。先程は触れませんでしたが、緑色のScheduling Cycleと黄色のBinding Cycleに分かれていることが見て取れます。
Scheduling CycleはPodをどのNodeで実行するかの決定までの責務を負っています。
そして、Binding CycleはScheduling Cycle での決定を実際にクラスターに適応する責務を負っています。
先程、
スケジュールを行う必要があるPodはkube-schedulerの内部でQueueのような形で保存されており、kube-schedulerはそのQueueから一つずつPodを取り出してスケジュールを行っていきます。
と言いましたが、詳しく正確に言うとScheduling CycleはPodに対して一つ一つを順番に実行しているが、Binding Cycleは並行に実行されています。Podがスケジュールされる場所が決まればそこから先は並行に実行しても他のPodのスケジュール結果には影響しないため、パフォーマンス等のメリットを鑑みてこのような実装になっています。
ということで先程紹介したFilterとScoreの拡張点の実行が終わり、行き先が決まったPodはBinding Cycleにて実際にその決定が適応され、スケジュールが終了します。
Podの行き先の決定の適応はBindと呼ばれます。
ここまでが、Scheduling Frameworkの紹介でした。
自作するスケジューラーについて
ということでここからが旅の始まりです。僕たちのオリジナルのスケジューラーを作っていきましょう。
以下が実装例が存在するリポジトリです。スケジューラーの段階ごとにブランチが切ってあり、一部のブランチには日本語で解説がついています。
https://github.com/sanposhiho/mini-kube-scheduler
kubernetes-sigs/kube-scheduler-simulator の仕組みを流用しており、コマンドライン上からスケジューラーの振る舞いを確認することができます。
振る舞いを確認するにはシナリオをclient-goを通して記述する必要があります。各ブランチにはそのブランチで実装した機能に適したシナリオがすでに記載されています。そのシナリオをそのまま使用するもよし、変更するもよしです。
シナリオはsched.goのscenario関数に記載します。例えばこのように記載してください。
https://github.com/sanposhiho/mini-kube-scheduler/blob/b5ca1625d39d4c98e67fab3b052366ce01047234/sched.go#L70
etcdを手元にインストールして頂き、make startを実行することでそのスケジューラーを使用し、シナリオが実行されます。以下のREADMEも参考にしてください。
https://github.com/sanposhiho/mini-kube-scheduler/blob/master/README.ja.md#%E3%82%B7%E3%83%8A%E3%83%AA%E3%82%AA%E3%82%B9%E3%82%B1%E3%82%B8%E3%83%A5%E3%83%BC%E3%83%A9%E3%83%BC%E3%81%AE%E5%AE%9F%E8%A1%8C%E3%81%AB%E9%96%A2%E3%81%97%E3%81%A6
また、肝心のスケジューラーの実装は/minisched以下に置いてあります。
ランダムなNodeにスケジュールするスケジューラーを作ろう
この章の実装はinitial-random-schedulerブランチに存在します。
まず、この章で、Podをランダムに選んだNodeにスケジュールするスケジューラーを作り、そこにどんどん機能を足していくという形を取って勧めていきたいと思います。
ランダムなNodeにスケジュールするスケジューラーでやる必要があること
ランダムなNodeにスケジュールするといってもいくつかやることがあります。
- ScheduleされていないPodを見つける
- そのPodのScheduleを始める
- 全てのNodeを取得する
- ランダムにNodeを一つ選ぶ
- 選んだNodeに対してPodをBindする
- 1に戻る
順番に実装していきましょう。
1. ScheduleされていないPodを見つける
この内最も難しいのが1です。1をもっと細分化するとこのような仕組みになっています。
- EventHandlerを用いて新しいPodの作成を検知する
- 新たなPodをQueueに入れる
EventHandlerとはKubernetesが提供する “リソースの変更をトリガーにあらかじめ登録した関数を実行してくれる仕組み” です。
すべてのPodは基本的に、新たに作成した瞬間にはどこのNodeで実行されるかわからない(= Scheduleされていない)宙ぶらりんな状態です。EventHandlerを用いることで誰かが新しいPodを作成したことを検知できます。その新しいPodをQueueに入れることで”ScheduleされていないPodを見つける”ことができたことになります。
(前述しましたが、スケジュールを行う必要があるPodはkube-schedulerの内部でQueueで管理されています。)
さて、ではQueueを作ってみます。
実装はここです。
https://github.com/sanposhiho/mini-kube-scheduler/blob/initial-random-scheduler/minisched/queue/queue.go
type SchedulingQueue struct {
activeQ []*v1.Pod
lock *sync.Cond
}排他制御のためのロックとPodを入れておくSliceを持つ構造体をQueueとすることにします。とりあえずはこのように凄くシンプルなものでいいでしょう。
また、QueueにPodを入れるメソッドと取り出すメソッドがあると便利ですね。このような感じで定義しましょうか。
func (s *SchedulingQueue) Add(pod *v1.Pod) {
s.lock.L.Lock()
defer s.lock.L.Unlock()
s.activeQ = append(s.activeQ, pod)
s.lock.Signal()
return
}
func (s *SchedulingQueue) NextPod() *v1.Pod {
// wait
s.lock.L.Lock()
for len(s.activeQ) == 0 {
s.lock.Wait()
}
p := s.activeQ[0]
s.activeQ = s.activeQ[1:]
s.lock.L.Unlock()
return p
}それぞれ特に難しいことはしておらず、排他制御を取りつつ、内部のSliceを操作しているだけです。
一旦Queueはこれでいいでしょう。次にEventHandlerの設定をしていきます。
実装はここです。
https://github.com/sanposhiho/mini-kube-scheduler/blob/initial-random-scheduler/minisched/eventhandler.go
func addAllEventHandlers(
sched *Scheduler,
informerFactory informers.SharedInformerFactory,
) {
// unscheduled pod
informerFactory.Core().V1().Pods().Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return !assignedPod(t) // まだどこにもアサインされていないPodにtrueを返す
default:
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
// FilterFuncでtrueが返ってきた新しいPodにこれを実行する
AddFunc: sched.addPodToSchedulingQueue,
},
},
)
}このaddAllEventHandlersという関数はスケジューラーの初期化時に呼ばれるようになっています。ここで(k8s.io/client-go/informers).SharedInformerFactoryを引数としてとり、それをもとにEventHandlerの設定をしています。
この辺はEventHandlerの扱い方なので詳しくは解説しませんが、FilterFuncでどこにもアサインされていないPodのみをフィルタリングし、そういったPodが新たに作成されたときにAddFuncつまりsched.addPodToSchedulingQueueを実行します。
addPodToSchedulingQueueは以下のようになっており、先程作成したQueueのAddメソッドを使用して、QueueにPodを追加しています。
func (sched *Scheduler) addPodToSchedulingQueue(obj interface{}) {
pod, ok := obj.(*v1.Pod)
if !ok {
return
}
sched.SchedulingQueue.Add(pod)
}ここまでで
- EventHandlerを用いて新しいPodの作成を検知する
- 新たなPodをQueueに入れる
を実現することができました。
2. PodのScheduleを始める
1は長い道のりでしたね。ここから先は比較的簡単です。
ランダムなNodeにPodをスケジュールするために、スケジューラーで実行する必要があることをおさらいしましょう。
- ScheduleされていないPodを見つける
- EventHandlerを用いて新しいPodの作成を検知する
- 新たなPodをQueueに入れる
- そのPodのScheduleを始める
- 全てのNodeを取得する
- ランダムにNodeを一つ選ぶ
- 選んだNodeに対してPodをBindする
- 1に戻る
はい。ということで1.bでQueueに入れたPodのスケジュールを始めていきます。
実装はここです。
https://github.com/sanposhiho/mini-kube-scheduler/blob/initial-random-scheduler/minisched/minisched.go
スケジューラーはscheduleOneというメソッドを無限に実行し続けるような形で実行されており、その名の通り、scheduleOneの一回の実行でPod一つのスケジュールが行われます。
なのでscheduleOneに全てのロジックが詰まっており、このメソッドを追えばスケジュールの様子がすべてわかる!ということですね。
pod := sched.SchedulingQueue.NextPod()繰り返しになりますが、Podのスケジュールを始めるにはQueueからPodを一つ取り出す必要があります。
先程定義したNextPodというメソッドを通して、
- PodがQueueにあれば、先頭のPodを一つ取り出す
- なければQueueにPodが追加されるまで待つ
の動作を実現することができます。
3. 全てのNodeを取得する
次に候補となる全てのNodeの取得に移ります。
nodes, err := sched.client.CoreV1().Nodes().List(ctx, metav1.ListOptions{})
if err != nil {
klog.Error(err)
return
}
klog.Info("minischeduler: Got Nodes successfully")client-goを通してNodeを全て取得します。
4. ランダムにNodeを一つ選ぶ
rand.Seed(time.Now().UnixNano())
selectedNode := nodes.Items[rand.Intn(len(nodes.Items))]3で取得したNodeの中からランダムに一つ選ぶことにしましょう。
5. 選んだNodeに対してPodをBindする
if err := sched.Bind(ctx, pod, selectedNode.Name); err != nil {
klog.Error(err)
return
}4でランダムに選んだNodeにPodをBindしています。BindはBindというメソッドで行っていますが、それほど重要ではないので割愛します。
これで全ての実装が終了しました!
動作を試す
さて、動作を試してみましょう。前述したようにリポジトリにはシナリオを定義して、スケジューラーの動作をお試しできる機能がついています。
今回は「node0 ~ node9を作成し、pod1を作成する」というシナリオを実行し、実際にNodeにBindされるかを確認してみます。
(シナリオの実行に関しては自作するスケジューラーについての章を参考にしてください。)
シナリオの定義はこちら
https://github.com/sanposhiho/mini-kube-scheduler/blob/initial-random-scheduler/sched.go
実行するとすごく多くのログがでて見にくいと思うのですが、以下のようにpod1がnode5にBindされたことが見て取れます。実行するたびに異なるNodeにBindされることも確認できると思います。

プラグインの実装方法を学ぶ
次の実装パートに移る前にすこし座学を挟みます。
プラグインはそれぞれ一つ以上の拡張点で動作します。
このように説明したプラグインですが、どのようにして実装されているのでしょうか。
正解は「それぞれの拡張点用のinterfaceが用意されている。」です。そのinterfaceを満たす構造体を作成することでその拡張点で実行されるプラグインを実装することができます。
例えばFilter拡張点で実行されるプラグインは全て以下のようなinterfaceに準じています。
type FilterPlugin interface {
Plugin
Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status
}このinterfaceを満たす構造体を作成することでFilter拡張点で実行されるプラグインを実装したことになります。
当然ながら一つの構造体は複数のinterfaceを満たすことができるので、複数の拡張点用のinterfaceを同時に満たす構造体を用意することで複数の拡張点で実行されるプラグインを実装できたことになります。
Filter/Score 拡張点をサポートしよう
先程の章でスケジューラーのベースとなる部分は完成しました。このスケジューラーでScheduling Framework のFilter/Score 拡張点をサポートしていきましょう。
ブランチはscore-pluginを参照してください。(filter-pluginというブランチも存在しますが、score-pluginブランチがこのブランチの変更も含んでいます)
これにより、Filter、Score拡張点で動作するkube-scheduler内のプラグインをインポートして使用することができます。
ただし、機能上preFilter、preScore拡張点など他の拡張点での動作を必要とするプラグインを実行するにはそれらの拡張点もサポートする必要があります。preFilterやpreScore拡張点に関しては後で説明します。
さて、現時点でのスケジューラーの動作を振り返りましょう。
- ScheduleされていないPodを見つける
- そのPodのScheduleを始める
- 全てのNodeを取得する
- ランダムにNodeを一つ選ぶ
- 選んだNodeに対してPodをBindする
- 1に戻る
ここにFilter、Score拡張点のサポートを入れると以下のようになります。
- ScheduleされていないPodを見つける
- そのPodのScheduleを始める
- 全てのNodeを取得する
- Filter 拡張点で Node の候補を絞る
- Score 拡張点で 残った候補をスコアリングする
- 残った候補の中からスコアが高いNodeを選ぶ
- 選んだNodeに対してPodをBindする
- 1に戻る
4と5と6が追加されています。
では実装に移りましょう。
Filter 拡張点で Node の候補を絞る
前回説明したようにscheduleOneにスケジューラーのメインのロジックが詰まっています。引き続きこのメソッドを見ていきましょう。
https://github.com/sanposhiho/mini-kube-scheduler/blob/score-plugin/minisched/minisched.go
feasibleNodes, err := sched.RunFilterPlugins(ctx, nil, pod, nodes.Items)
if err != nil {
klog.Error(err)
return
}Filter拡張点でのプラグインの実行はRunFilterPluginsというメソッドの中で実行することにしています。
func (sched *Scheduler) RunFilterPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodes []v1.Node) ([]*v1.Node, error) {
feasibleNodes := make([]*v1.Node, 0, len(nodes))
diagnosis := framework.Diagnosis{
NodeToStatusMap: make(framework.NodeToStatusMap),
UnschedulablePlugins: sets.NewString(),
}
// TODO: consider about nominated pod
for _, n := range nodes {
n := n
nodeInfo := framework.NewNodeInfo()
nodeInfo.SetNode(&n)
status := framework.NewStatus(framework.Success)
for _, pl := range sched.filterPlugins {
status = pl.Filter(ctx, state, pod, nodeInfo)
if !status.IsSuccess() {
status.SetFailedPlugin(pl.Name())
diagnosis.UnschedulablePlugins.Insert(status.FailedPlugin())
break
}
}
if status.IsSuccess() {
feasibleNodes = append(feasibleNodes, nodeInfo.Node())
}
}
if len(feasibleNodes) == 0 {
return nil, &framework.FitError{
Pod: pod,
Diagnosis: diagnosis,
}
}
return feasibleNodes, nil
}長いですが、中身はこのように実装してあります。上から順に説明していきます。
func (sched *Scheduler) RunFilterPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodes []v1.Node) ([]*v1.Node, error) {
feasibleNodes := make([]*v1.Node, 0, len(nodes))
diagnosis := framework.Diagnosis{
NodeToStatusMap: make(framework.NodeToStatusMap),
UnschedulablePlugins: sets.NewString(),
}まず、RunFilterPluginsの引数を見てみましょう。CycleStateに関しては後で登場するので今は無視しておいてください。
それ以外は現在スケジュールしているPodと候補となっているNodeですね。
feasibleNodesという変数を初期化しています。これは最終的にすべてのFilterプラグインの実行をくぐり抜けたNodeが集められるSliceです。
diagnosisという構造体には何かしらのFilterプラグインに除外されたNodeがどのプラグインに拒否されたのかを記録しています。
これはすべての候補のNodeがFilterされてしまい、最終的に候補のNodeが一つも残らなかったときにエラーとして返却されます。
続きを見ていきましょう。
for _, n := range nodes {
n := n
nodeInfo := framework.NewNodeInfo()
nodeInfo.SetNode(&n)
status := framework.NewStatus(framework.Success)
for _, pl := range sched.filterPlugins { // ループで回して全てのプラグインを実行する
status = pl.Filter(ctx, state, pod, nodeInfo) // Filterプラグインの実行
if !status.IsSuccess() { // プラグインがNodeをPodに不適格とした場合
status.SetFailedPlugin(pl.Name())
diagnosis.UnschedulablePlugins.Insert(status.FailedPlugin()) // 前述のdiagnosisにUnschedulablePluginsとして登録する
break
}
}
if status.IsSuccess() {
feasibleNodes = append(feasibleNodes, nodeInfo.Node())
}
}ここでは、引数で渡ってきたnodesをループで回していることが見て取れます。そして、その内側でスケジューラーに登録されているfilterPluginsをループで回しています。
(スケジューラーの初期化時にプラグインがスケジューラーに登録されます。)
Filter拡張点で実行されるプラグインは全て以下のようなinterfaceに準じていると前述しました。
type FilterPlugin interface {
Plugin
Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status
}このFilterメソッドがこのループで呼び出されると、プラグインは引数として渡されたPodとNodeの情報をもとに、そのNodeでそのPodを実行しても大丈夫かどうかのFilterを行います。
ここでプラグインが「このNodeでPodを実行してもいいよ」と判断した場合、次のプラグインの実行に移ります。すべてのプラグインがOKを出した場合、そのNodeがfeasibleNodesに追加されます。
また、プラグインが「このNodeでPodを実行してはいけない」と判断した場合、返り値でSuccess以外のものが返ってくるので、その場合そのNodeに対しては他のプラグインは実行されず、もちろんfeasibleNodesにそのNodeは追加されません。
if len(feasibleNodes) == 0 {
return nil, &framework.FitError{
Pod: pod,
Diagnosis: diagnosis,
}
}
return feasibleNodes, nilこれが最後の部分ですね。feasibleNodesが0、すなわち候補として一つもNodeが残らなかった場合はframework.FitErrorという特別なエラーを返します。(後の章でこのエラーに関しては解説があります。)
それ以外の場合はfeasibleNodesを返却しています。
これにてFilter拡張点をサポートすることができました。これにより、Filter拡張点で実行されるプラグインは全てこのスケジューラーで実行することができます。
Score 拡張点で 残った候補をスコアリングする
次はScore拡張点のサポートに移ります。こちらもFilter拡張点と似たような形で実装することになります。
score, status := sched.RunScorePlugins(ctx, nil, pod, fasibleNodes)
if !status.IsSuccess() {
klog.Error(status.AsError())
return
}scheduleOneを見るとRunScorePluginsを実行していることが分かると思います。RunScorePluginsを見ていきましょう。
func (sched *Scheduler) RunScorePlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodes []*v1.Node) (framework.NodeScoreList, *framework.Status) {
scoresMap := sched.createPluginToNodeScores(nodes)
for index, n := range nodes {
for _, pl := range sched.scorePlugins { // ループで回して全てのプラグインを実行
score, status := pl.Score(ctx, state, pod, n.Name)
if !status.IsSuccess() { // Filterとは違い、変なエラーが起こらない限りプラグインからはSuccessが返ってくる
return nil, status
}
scoresMap[pl.Name()][index] = framework.NodeScore{ // 後の集計のためのMapに点数を記録
Name: n.Name,
Score: score,
}
}
}
// TODO: plugin weight & normalizeScore
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes { // 集計
result = append(result, framework.NodeScore{Name: nodes[i].Name, Score: 0})
for j := range scoresMap {
result[i].Score += scoresMap[j][i].Score
}
}
return result, nil
}また、少し長くなっていますが、やっていることはFilter拡張点と変わりません。引数として渡ってきたFilterを通り抜けたNode達をループで回し、その中で登録されているscorePluginsをループで回し、Scoreメソッドを実行することでプラグインのスコアの結果を受け取っています。
Score拡張点のinterfaceにScoreメソッドが定義されているため、この拡張点で実行されるプラグインは全てScoreメソッドを持っています。
type ScorePlugin interface {
Plugin
Score(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) (int64, *Status)
ScoreExtensions() ScoreExtensions
}Nodeのループの後半は点数を集計しているだけなのであまり気にしなくて良いです。framework.NodeScoreListという構造体にScore拡張点でのスコアリングの結果を全て格納して返却しています。
さてこれでScore拡張点もサポートすることができました。これにより、Score拡張点で実行されるプラグインは全てこのスケジューラーで実行することができます。
実際にプラグインを作ってみよう
さて前の章でFilter拡張点とScore拡張点をサポートしましたが、実行するプラグインが無いと動作を確認できませんね。もちろん本物のkube-schedulerから持ってくることもできるのですが、ここで一つ実際に簡単なプラグインを作ってみましょう。
Score拡張点でのみ動作するプラグインを作ってみることにします。ブランチは引き続きscore-pluginを参照してください。
前述のScore拡張点のinterfaceを満たす構造体を作ればOKです。
NodeNumber プラグイン
今回例として実装するのはNodeNumberプラグインというものです。Podの名前の末尾とNodeの名前の末尾に数字がついていて、その数字が一致していた場合10点を、それ以外の場合は0点を付けるというスコアリングをさせることにします。 (スコアリングに関しては、Score拡張点とスコアの正規化を行うNormalizedScore拡張点の実行後の点数が0-100点の範囲に収まる必要があります。(ref))
例えば、Pod1という名前のPodが作成されていて、Node1~Node9という名前のNodeがあった場合、Node1のみが高得点となります。
このプラグインの実装は以下です。
https://github.com/sanposhiho/mini-kube-scheduler/blob/score-plugin/minisched/plugins/score/nodenumber/nodenumber.go
Scoreメソッドを実装していきます。引数としてはスケジュール対象のPodと候補のNodeの名前が渡ってきます。
func (pl *NodeNumber) Score(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
podNameLastChar := pod.Name[len(pod.Name)-1:]
podnum, err := strconv.Atoi(podNameLastChar)
if err != nil {
// Podの名前の末尾が数字じゃない場合は0点を返す
return 0, nil
}
nodeNameLastChar := nodeName[len(nodeName)-1:]
nodenum, err := strconv.Atoi(nodeNameLastChar)
if err != nil {
// Nodeの名前の末尾が数字じゃない場合は0点を返す
return 0, nil
}
if podnum == nodenum {
// 一致する場合10点を返す
return 10, nil
}
return 0, nil // 一致しない場合は0点を返す
}単純ですね。コメントを読んで頂ければ理解できると思います。
プラグインをスケジューラーに登録して動作確認
このプラグインをスケジューラーの初期化時に登録します。
実装はここですが、あまり重要ではないので割愛します。
https://github.com/sanposhiho/mini-kube-scheduler/blob/score-plugin/minisched/initialize.go#L68
ではスケジューラーの動作を試してみましょう。
今回はnode0 ~ node9を作成した後に、pod1とpod3を作成して、どこにbindされるか見るというシナリオになっています。
https://github.com/sanposhiho/mini-kube-scheduler/blob/score-plugin/sched.go#L70
実行してみると以下のようにpod1はnode1へpod3はnode3へbindされたことがわかります。


実はスコアリングの様子がわかりやすいようにログを仕込んでおきました。
細かいですが、pod3のスケジュール時にはちゃんとnode3が一番スコアが高くなっているのが見て取れます。

CycleStateについて知ろう
CycleStateというものがちょこちょここれまでの実装には登場していましたがここまでスルーし続けてきました。
CycleStateとは一つのPodのスケジュールにおける一時的なデータを置いておく場所です。Podのスケジュール開始時に毎回新しく作成され、プラグインなどはCycleStateに情報を置くことで拡張点間で情報を共有することができます。
このCycleStateがよく使用されている例をご紹介します。それが、PreFilter、PreScore拡張点です。
これらはそれぞれFilter、Score拡張点の実行の準備を行う拡張点です。PreFilterやPreScoreにおいて、事前の計算などをまとめて行い、その結果をCycleStateに置いておきます。
Filter、Score拡張点でその情報を取得し、効率的な処理を行うことができます。
PreScore 拡張点で動作するプラグインを開発してみよう
CycleStateの文字での説明だけでは想像しづらかったかもしれません。先程作成したNodeNameプラグインをPreScore拡張点でも動作するようにして、計算の効率化を図ってみたいと思います。
ブランチはprescore-pluginを参照してください。
おさらいですが、NodeNumberプラグインのScoreでは以下のような流れでスコアリングがなされていました。
- Nodeの名前の末尾の数字を取得する
- Podの名前の末尾の数字を取得する
- 1と2を比較して一致していたら高い点数を返す
一つのスケジュールでは当然ですが一つのPodのみが対象になるため、2は変化しません。
しかし、Score拡張点はNodeの数分だけ呼び出されるので、毎回Podの名前の末尾の数字を切り出して、取得して‥ということをやるのはほんんんんの少しだけ無駄です。
(「いや、そこ削ってもそんなにパフォーマンス向上せんやろ」って思いましたね。僕も思ってますよ。例のためなのでそこはご容赦ください。)
なのでPreScoreで事前にPodの名前の末尾の数字を取得してScoreではCycleStateから取得するように変更しましょう。
PreScore 拡張点をスケジューラーでサポートする
まずはFilterやScore拡張点と同様にスケジューラー側でPreScore拡張点をサポートしましょう。実行のタイミングはFilterのあと、Scoreのまえです。
status := sched.RunPreScorePlugins(ctx, state, pod, fasibleNodes)
if !status.IsSuccess() {
klog.Error(status.AsError())
return
}これまでと同様にRunPreScorePluginsというメソッドで実行することにしましょう。
実装はこんな感じです。短いですね。
func (sched *Scheduler) RunPreScorePlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodes []*v1.Node) *framework.Status {
for _, pl := range sched.preScorePlugins { // 登録されているPreScoreプラグインをループで実行
status := pl.PreScore(ctx, state, pod, nodes)
if !status.IsSuccess() {
return status
}
}
return nil
}FilterやScoreと異なり、Nodeごとに実行するのではなく、Nodeのリストを渡し、PreScoreを一度だけ実行しています。
NodeNumberプラグインをPreScoreで実行するように変更
NodeNumberプラグインの実装はここです。
PreScoreの実装を見てみましょう。
func (pl *NodeNumber) PreScore(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodes []*v1.Node) *framework.Status {
podNameLastChar := pod.Name[len(pod.Name)-1:]
podnum, err := strconv.Atoi(podNameLastChar) // Podの末尾の数字を取得
if err != nil {
// Podの末尾が数字じゃなくてもエラーを返さない。
return nil
}
s := &preScoreState{
podSuffixNumber: podnum,
}
state.Write(preScoreStateKey, s) // CycleStateに書き込み
return nil
}また、CycleStateに書き込むものはこのinterfaceに準じる必要があります。
type StateData interface {
Clone() StateData
}そのため、preScoreStateという構造体を定義し、その構造体に対してCloneメソッドを定義しています。Podの末尾の数字の計算結果もpreScoreStateの中に格納しています。
// preScoreState computed at PreScore and used at Score.
type preScoreState struct {
podSuffixNumber int
}
// Clone implements the mandatory Clone interface. We don't really copy the data since
// there is no need for that.
func (s *preScoreState) Clone() framework.StateData {
return s
}また、Scoreの前半の部分が引数として渡ってきたPodの末尾の数字を取得するのではなく、CycleStateから先程のpreScoreSteteを取得するように変更しています。
// Score invoked at the score extension point.
func (pl *NodeNumber) Score(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
data, err := state.Read(preScoreStateKey)
if err != nil {
return 0, framework.AsStatus(err)
}
s, ok := data.(*preScoreState)
if !ok {
return 0, framework.AsStatus(errors.New("failed to convert pre score state"))
}これにて、PreScore拡張点を通してNodeNumberプラグインを効率化することができました。
Scheduling Cache について知ろう
さて、少し座学に入りましょう。これまで僕たちのスケジューラーはclient-goを通してAPIからNodeをすべて取得していました。
この部分、実際のkube-schedulerは実際にはAPIからNodeを取得しているわけではありません。そこで出てくるのがScheduling Cache と snapshotの仕組みです。
kube-schedulerは内部のScheduling Cacheという部分にNodeの状態を置いています。kube-schedulerがNodeの状態を取得するときは基本的にはこのCacheから取得します。
Scheduling Cacheでは基本的には最新のNodeの状態が置かれています。(「基本的には」と言っている理由は後でわかります)
Cacheを最新に保つためにはEventHandlerが使用されています。覚えていますか?最初のスケジュールされていないPodを見つけてQueueに入れるために使用したあいつです。
さて、ではScheduling Cacheのメリットは以下になります。
- 毎回APIに問い合わせない分効率が良い
- snapshotと組み合わせることでPodのスケジュール中に同じNodeの状態を参照し、スケジュールを行える
- スケジューラーに都合がいい形でNodeのデータを加工することができる。
他にも存在するかもしれませんが、僕はこの3つが大きな要因だと思っています。
1つ目は自明なので割愛します。
2つ目以降を説明します。
snapshotと組み合わせることでPodのスケジュール中に同じNodeの状態を参照し、スケジュールを行える
snapshotとはScheduling Cacheとともに使用されているもので、その名の通り、Scheduling Cacheのある時点でのsnapshotを取ったものです。
Scheduling Cacheの状態はスケジュールの動作とは非同期にEventHandlerによって更新されています。
kube-schedulerはスケジュールの開始時に毎回その時のScheduling Cacheの状態をsnapshotに保存します。プラグインによっては、その動作の中でNodeの状態を取得するものが存在するのですが、プラグインの実行タイミングによって、取得されるNodeの状態が変わってしまうと、結果が安定しません。
kube-schedulerがNodeの状態を取得するときは基本的にはこのCacheから取得します。
とつい先程言いましたが、正確にはこれは嘘です。kube-schedulerでは、Scheduling Cacheから都度最新のNodeを直接取得するのでなく、スケジュール開始時に作成したsnapshotからNodeを取得することで、一つのPodのスケジュール中に参照するNodeの状態が同じになるように設計してあります。賢い。
スケジューラーに都合がいい形でNodeのデータを加工することができる
最後、3つ目のメリットを見てみましょう。kube-schedulerはScheduling Cache(正確に言うとsnapshot)からNodeを取得していると言いました。そして、当然ですが、Scheduling CacheのNodeのとある状態をプラグインがAからBに変更するとスケジューラーはそのNodeの状態をBであると勘違いしてスケジュールを行うことになります。
このkube-schedulerがScheduling Cacheにバッチを当てることで、自身に対して「騙し」を行うことができる点がメリットなのです。
一番初めにScheduling Frameworkの説明を行ったときに以下のようにScheduling CycleとBinding Cycleについて説明を行いました。
Scheduling CycleはPodをどのNodeで実行するかの決定までの責務を負っています。
そして、Binding CycleはScheduling Cycle での決定を実際にクラスターに適応する責務を負っています。Binding Cycleは並行に実行されています。Podがスケジュールされる場所が決まればそこから先は並行に実行しても他のPodのスケジュール結果には影響しないため、パフォーマンスを鑑みてこのような実装になっています。
そうです。Binding Cycleは並行に実行されているんでしたね。
これによる一つ大きな問題点に気づくことができますか?
それは、Binding CycleでのBindが終わる前に次のPodのスケジュールが始まってしまうため、次のPodのスケジュールではBindが終わっていないPodの存在が無視されてしまうことです。
少し想像し難いですね、例を挙げてみます。NodeAという1つのNodeのみが存在し、ちょうど一つのPodを実行できるリソースしか持っていないとします。そこにPodAとPodBというPodが作成されました。
PodAが先にスケジュールされ、Scheduling CycleでNodeAに割り当てられることが決定し、Binding Cycleに進みました。そしてPodBのスケジュールがPodAのBindが終わる前にスタートしたとします。
このとき、PodBの理想的なスケジューリング結果は「どこにもスケジュールできず、Unschedulableの状態になる」です。これはPodAがNodeAに行くことが決まっているからですね。
しかし、Schedulinc Cacheとsnapshotの仕組みにより、スケジュール開始時のNodeの状態、すなわちPodAの実行されていない状態をもとにしてPodBのスケジュールが行われます。そのため、PodBはScheduling CycleでPodAと同様に「NodeAに行ってヨシ」と判断されてしまいます。実際にこうなった場合はコンテナの起動を担っているkubeletが拒否するため、大きな問題にはなりませんが、あまりお行儀がよろしくありません。
また、もう少し複雑な例を見てみましょう。NodeAとNodeBという2つのNodeが存在し、それぞれ全く同じ性能であり、素晴らしいことに無限大に近いリソースを持っているとします。そしてNodeBにはすでにとっても小さなPodCが実行されているとしましょう。そこにPodCよりもとっても大きなリソースを要求するPodAとPodBというPodが作成されました。
この場合まずは、PodAはNodeAにスケジュールされることがScheduling Cycleで決定するはずです。これはNodeBがPodCを実行しており、NodeAよりも現在リソースを多く使用しているためです。
そしてその後にスケジュールされる、PodBの理想的なスケジューリング結果は「NodeBにスケジュールされる」です。これはPodAがNodeAに行くことが決まっており、そのため、NodeAとNodeBのリソースの使用量を比べたときにNodeAがとっても大きなPodAを実行しており、NodeBはとってもちいさなPodCを実行しているため、NodeBのほうがリソース的に余裕があるためです。
しかし1つ目の例と同様にScheduling Cacheとsnapshotの仕組みにより、スケジュール開始時のNodeの状態、すなわちPodAの実行されていない状態をもとにしてPodBのスケジュールが行われます。そのため、PodBのScheduling Cycleでは、「NodeAではPodが一つも実行されていないが、NodeBではPodCが実行されている」という状況を参照してスケジュールするため、PodBはNodeAにBindされてしまいます。
今回はこの場合はkubeletはPodBを拒否しません。それはNodeAには無限大に近いリソースがあるため、PodAとPodBは同時に実行できてしまうためです。
このように1つ目の例ではkubeletが最終的に拒否してくれ、「行儀が悪い」くらいで収まっていましたが、2つ目の例では完全にリソースに偏りが出る状態でクラスターが動作することになってしまいました。
さて、話を戻しましょう。2つの例によって、Binding Cycleを単に並行化してしまうと、問題が発生してしまうことがわかりました。
ここでScheduling Cacheにバッチを使用します。kube-schedulerはScheduling Cycleが終了した際に、Scheduling Cacheに対してNodeの状態の変更を行います。
先程の例だと、Scheduling CycleでPodAの行き先がNodeAに決まったときに、Scheduling CacheへPodAがNodeAで実行されている状況への変更が行われます。
これにより、PodBのスケジュールの際にNodeの状態をScheduling Cacheから取得すると、PodAがNodeAで実行している状況が取得されることになり、理想的なスケジュールを行うことができます。
また、何かしらによって、Binding Cycleの実行中にエラーが生じて、Bindが失敗した場合は、Scheduling Cache内で、PodAがNodeAで実行されているとしていた変更が戻されます。
さて、長い座学となりましたが、Scheduling Cacheとそのメリットについて学びました。
[Note]このスケジューラーにおけるScheduling Cache
今回の記事ではScheduling Cacheやsnapshotの機能を実装しません。(実装例にも載っていません)
この後の章でBinding Cycleの並行化を行いますが、Scheduling Cacheの仕組みを実装していないので、僕たちのスケジューラーにおいてはここで紹介した問題は起こってしまう可能性があることになります。
Permit 拡張点をサポートする
ここまでで僕たちのスケジューラーはFilterやPreScore、Scoreを実装してきました。同様にして、似たように登録しているプラグインを良さげにループして実行するという処理を書くことで他の多くのプラグインのサポートも入れられるはずです。
しかし、一つだけそう簡単にサポートすることができない拡張点が存在します。それがPermit拡張点です。
この章ではPermit拡張点について学び、そのサポートを実装してみましょう。
実装例はpermit-pluginbranchです。
Permit 拡張点とは
Scheduling Cycleの一番最後に実行される拡張点です。Binding Cycleの一番はじめのWaitOnPermitもこれに関係するので実質、この2つのCycleにまたがる拡張点とも言えます。
Permit拡張点はBind Cycleの実行を中止、遅延を行うことができます。
Permit プラグインは3つのステータスを返します
- approve: 「このPodはもうBindしてOK 👍」
- deny: 「このPodはBindしたらだめ 🙅♂️」
- wait: 「保留で! O秒以内に結果(approve/deny)をお伝えします🙇♂️」
全てのPermit プラグインがapproveした場合にBinding Cycleの実行が始まります。
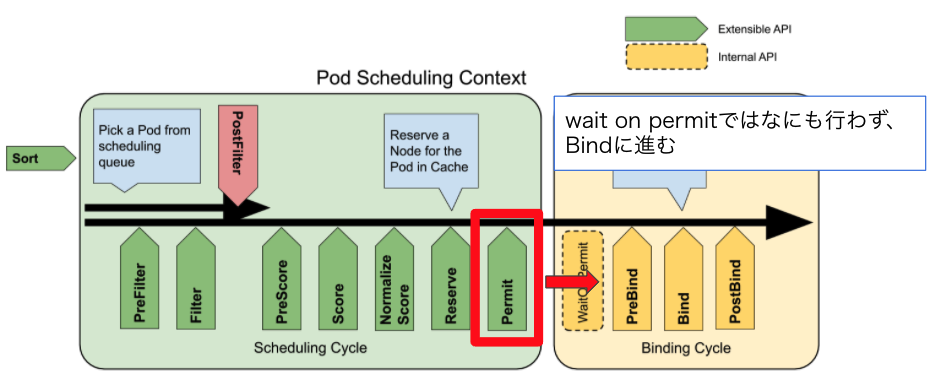
逆に言うと一つでもPermitプラグインがdenyした場合はBinding Cycleは実行されません。
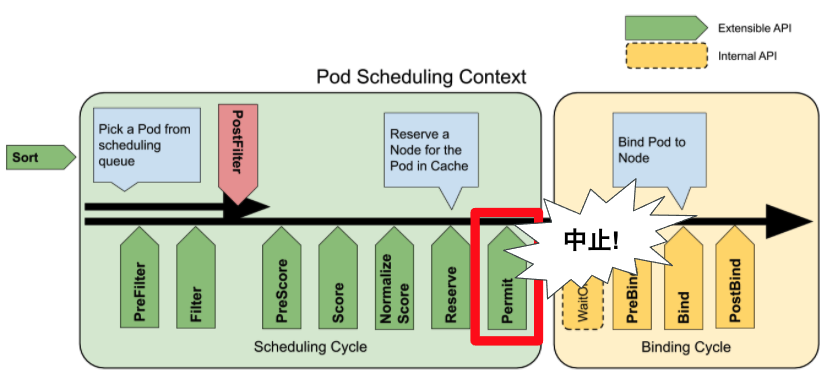
また、waitだけが特別でBinding Cycleの実行可否の判断を指定した秒数だけ遅らせることが可能です。一つでもPermitプラグインがwaitを返した場合はBinding Cycleの一番はじめのWaitOnPermitでそのプラグインからの結果が出るまでBinding Cycleの他の処理の実行を遅らせます。denyが最終的に送られてきた場合はそこでBinding Cycleは中止され、指定した時間内に結果が帰ってこなかった場合もtimeoutとしてdenyとして扱われます。
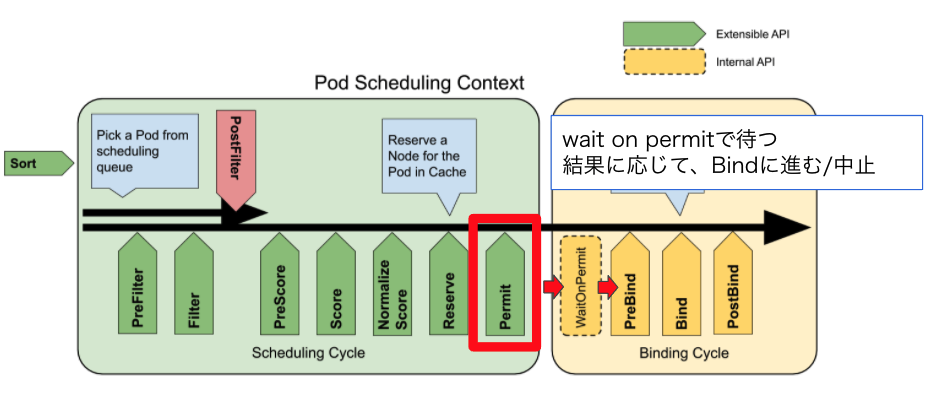
Permit 拡張点をサポートする
https://github.com/sanposhiho/mini-kube-scheduler/blob/permit-plugin/minisched/minisched.go
いつもどおり、実行はRunPermitPluginsで行われています。ここでdenyが返されたときはBinding Cycleに進みません。
status = sched.RunPermitPlugins(ctx, state, pod, nodename)
if status.Code() != framework.Wait && !status.IsSuccess() {
klog.Error(status.AsError())
return
}ではRunPermitPluginsを見ていきましょう。
func (sched *Scheduler) RunPermitPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (status *framework.Status) {
pluginsWaitTime := make(map[string]time.Duration)
statusCode := framework.Success
for _, pl := range sched.permitPlugins {
status, timeout := pl.Permit(ctx, state, pod, nodeName)
if !status.IsSuccess() {
// deny
if status.IsUnschedulable() {
klog.InfoS("Pod rejected by permit plugin", "pod", klog.KObj(pod), "plugin", pl.Name(), "status", status.Message())
status.SetFailedPlugin(pl.Name())
return status
}
// wait
if status.Code() == framework.Wait {
pluginsWaitTime[pl.Name()] = timeout
statusCode = framework.Wait
continue
}
// other errors
err := status.AsError()
klog.ErrorS(err, "Failed running Permit plugin", "plugin", pl.Name(), "pod", klog.KObj(pod))
return framework.AsStatus(fmt.Errorf("running Permit plugin %q: %w", pl.Name(), err)).WithFailedPlugin(pl.Name())
}
}
if statusCode == framework.Wait {
waitingPod := waitingpod.NewWaitingPod(pod, pluginsWaitTime)
sched.waitingPods[pod.UID] = waitingPod
msg := fmt.Sprintf("one or more plugins asked to wait and no plugin rejected pod %q", pod.Name)
klog.InfoS("One or more plugins asked to wait and no plugin rejected pod", "pod", klog.KObj(pod))
return framework.NewStatus(framework.Wait, msg)
}
return nil
}さては「ながぁ。」って思いましたね。僕も思いました。しかしそれほどややこしいことはしていません。
上から順に見ていくことにしましょう。
func (sched *Scheduler) RunPermitPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (status *framework.Status) {
pluginsWaitTime := make(map[string]time.Duration)
statusCode := framework.Success
for _, pl := range sched.permitPlugins {
status, timeout := pl.Permit(ctx, state, pod, nodeName)必要なものを初期化した後に、他の拡張点と同様に登録されているプラグインをループで回して実行しています。
ここでPermitメソッドは、statusとtimeoutを返却します。
if !status.IsSuccess() {
// deny
if status.IsUnschedulable() {
klog.InfoS("Pod rejected by permit plugin", "pod", klog.KObj(pod), "plugin", pl.Name(), "status", status.Message())
status.SetFailedPlugin(pl.Name())
return status
}
// wait
if status.Code() == framework.Wait {
pluginsWaitTime[pl.Name()] = timeout
statusCode = framework.Wait
continue
}
// other errors
err := status.AsError()
klog.ErrorS(err, "Failed running Permit plugin", "plugin", pl.Name(), "pod", klog.KObj(pod))
return framework.AsStatus(fmt.Errorf("running Permit plugin %q: %w", pl.Name(), err)).WithFailedPlugin(pl.Name())
}statusがSuccessだと、それはapproveを意味しています。approveの場合は何も起こらずにループで次のプラグインの実行に移ります。
そしてapproveじゃない場合はwaitの場合とdenyの場合があります。
denyの場合はそのままreturnします。
waitの場合は、timeoutを始めに初期化したpluginsWaitTimeに格納してcontinueします。
if statusCode == framework.Wait {
waitingPod := waitingpod.NewWaitingPod(pod, pluginsWaitTime) // waitingPodの作成
sched.waitingPods[pod.UID] = waitingPod // waitingPodをスケジューラーに保存 (waitOnPermitで使用する)
msg := fmt.Sprintf("one or more plugins asked to wait and no plugin rejected pod %q", pod.Name)
klog.InfoS("One or more plugins asked to wait and no plugin rejected pod", "pod", klog.KObj(pod))
return framework.NewStatus(framework.Wait, msg)
}
return nilそして、そのプラグインのループを抜けた先で先程のpluginsWaitTimeを処理します。
一つ以上のプラグインがwaitを返した場合、waitingPodという構造体が作成されてスケジューラーに登録されます。
そして、後のwaitOnPermitでこのwaitingPodを通してBinding Cycleは結果を待つことになります。
waitingPodはwait状態のPodに対して、「どのPluginが何秒までに結果を出すのか」を保持している構造体で、timeoutの管理などもこの構造体が行ってくれています。内部的に結果の送受信を行うchannelを保持しており、waitを返したPermit プラグインはwaitingPodのchannelを通してwaitOnPermitしているBinding Cycleへ結果を送信します。
waitingPodの実装も実装例には含まれていますが、少し複雑なのでここでは紹介しません。
次にwaitOnPermitの実装を見ていきましょう。
go func() {
ctx := ctx
status := sched.WaitOnPermit(ctx, pod)
if !status.IsSuccess() {
klog.Error(status.AsError())
return
}
if err := sched.Bind(ctx, pod, nodename); err != nil {
klog.Error(err)
return
}
klog.Info("minischeduler: Bind Pod successfully")
}()WaitOnPermitの実装を見てみましょう。
func (sched *Scheduler) WaitOnPermit(ctx context.Context, pod *v1.Pod) *framework.Status {
waitingPod := sched.waitingPods[pod.UID] // waitingPodが存在するかどうかを確認する
if waitingPod == nil {
return nil
}
defer delete(sched.waitingPods, pod.UID)
klog.InfoS("Pod waiting on permit", "pod", klog.KObj(pod))
s := waitingPod.GetSignal() // ここでchannelから結果が送られてくるのを待つ
if !s.IsSuccess() {
if s.IsUnschedulable() { // deny
klog.InfoS("Pod rejected while waiting on permit", "pod", klog.KObj(pod), "status", s.Message())
s.SetFailedPlugin(s.FailedPlugin())
return s
}
err := s.AsError()
klog.ErrorS(err, "Failed waiting on permit for pod", "pod", klog.KObj(pod))
return framework.AsStatus(fmt.Errorf("waiting on permit for pod: %w", err)).WithFailedPlugin(s.FailedPlugin()) // deny 以外の予期せぬエラー
}
return nil
}それほどややこしくありません。waitingPod.GetSignal()で結果を待っています。
これでBinding Cycleの並行化とPermit拡張点のサポートが終了しました!
Permit 拡張点で動作するプラグインを開発してみよう
例のごとくNodeNumberプラグインをPermit拡張点で実行されるようにサポートしてみます。
決定したNodeの末尾の数字によってBinding Cycleをその秒数遅らせるという振る舞いをさせてみましょう。例えばNode2というNodeにPodがBindされることが決定した場合、2秒遅らせてBindするといった具合です。
Permit 拡張点のinterfaceはこれです。
type PermitPlugin interface {
Plugin
Permit(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) (*Status, time.Duration)
}前述のようにPermitはstatusとtimeoutの時間を返します。
ではNodeNumberの実装を見てみます。
func (pl *NodeNumber) Permit(ctx context.Context, state *framework.CycleState, p *v1.Pod, nodeName string) (*framework.Status, time.Duration) {
nodeNameLastChar := nodeName[len(nodeName)-1:]
nodenum, err := strconv.Atoi(nodeNameLastChar) // Nodeの末尾の数字を取得
if err != nil {
// return allow(success) even if its suffix is non-number.
return nil, 0
}
// {nodenum} 秒後に関数が実行されるように登録する。ただし、このPermitメソッド自体はここでブロックされない。
time.AfterFunc(time.Duration(nodenum)*time.Second, func() {
wp := pl.h.GetWaitingPod(p.GetUID()) // スケジューラーに登録されているwaitingPodを取得
wp.Allow(pl.Name()) // AllowはwaitingPodのchannelを通してapproveを送る
})
timeout := time.Duration(10) * time.Second
return framework.NewStatus(framework.Wait, ""), timeout
}Nodeの末尾の数字を取得し、(末尾の数字)秒数後にapproveが送られるように登録しています。登録だけ終えると、関数自体はtime.AfterFuncの箇所でブロックされず、次に処理が進み、waitとtimeoutが返却されます。Nodeの末尾の数字は一桁しか確認しないため、10秒をtimeoutとして返しています。
Permit拡張点とNodeNumberプラグインの動作確認
いつもの要領でシナリオを定義し、動作を確認します。
https://github.com/sanposhiho/mini-kube-scheduler/blob/permit-plugin/sched.go#L70
今回は「node0 ~ node9を作った後にpod1とpod9を作成」して、実際にBindが遅延されるのかを確認します。NodeNumberのScore拡張点での動作により、pod1はnode1へpod9はnode9へBindされるはずです。
そのためpod1のBindが1秒、pod9のBindが9秒遅延されているというのが理想の動作となります。
結果を見てみましょう。まず、pod1とpod9を作ってから4秒後にpod1とpod9の様子をログに出すようにシナリオを書いています。下の写真がそのログです。

pod1はnode1にすでにbindされていますが、pod9はまだされていないようです。通常はスケジュールは人間の感覚からすると一瞬で終了するので遅延が成功していることが確認できます。
そしてそこから更に数秒待った後にpod9を確認するとnode9へbindされていました。無事遅延されていたようです。

[TIPS] Permit拡張点はin-treeなプラグインでは使用されていない
Permit拡張点はin-tree(デフォルトでkube-schedulerに実装されているもの)のプラグインからは使用されていません。
kubernetes-sigs/scheduler-pluginsにおける、coschedulingというプラグインからは使用されています。
https://github.com/kubernetes-sigs/scheduler-plugins/tree/master/pkg/coscheduling
また、coschedulingプラグインに関してはin-treeに移動する可能性がこのissueで議論されています。
Move coscheduling plugin from scheduler-plugins to kubernetes/kubernetes #105802
Scheduling Queueをちゃんと実装する
さて、僕たちのスケジューラーもかなり形になってきました。サポートしていない拡張点はいくつかありますが、それを追加することは難しくありませんし、すでにサポートした拡張点に関しては実際のkube-schedulerからプラグインを持ってきても動作するはずです。
しかし、一つ大きな機能が抜けています。
それはスケジュールに失敗したPodの扱いです。Filterで一つも候補となるNodeが残らなかった場合やなにかしらのプラグインが変なエラーを出した場合など、現状の僕たちのスケジューラーはスケジュールを中止するだけでした。そのPodは完全にそこから放置されてしまいます。
本来であればそういった一度スケジュールに失敗したPodはQueueに戻されてしばらくした後に再度スケジュールを試すということが期待されます。
この動作を行うには僕たちが一番最初にすごく適当に作成したQueueを改善する必要があります。僕たちのQueueを本来のkube-schedulerが持つQueueに近づけていきましょう。
実装例のブランチはscheduling-queueです。
おさらいですが、現状の僕たちのQueueは追加と取り出しのメソッドしか定義されておらず、内部にSliceと排他制御のロックしか持っていません。
type SchedulingQueue struct {
activeQ []*v1.Pod
lock sync.RWMutex
}では実際のkube-schedulerはというと以下の3つのQueueを内部的に持っています。
- activeQ: Schedule待ちのPodのQueue
- unschedulableQ: 一度スケジュールしようとして失敗したPodのQueue。Unschedulableとなった原因のPluginなども保存
- podBackoffQ: backoff中のPodのQueue。
見ての通り、それぞれ役割が異なっています。activeQはスケジュール待ちのPodのQueueになっていて、スケジューラーはこのQueueからPodを取り出してスケジュールしていくことになります。
そしてunschedulableQは一度スケジュールしようとして失敗したPodが入るQueueです。Queueと言っていますが、内部的にはmapで実装されています。
そしてpodBackoffQです。スケジュールに失敗したPodはExponential backoffに従ってスケジュールがリトライされます。
kube-schedulerのScheduling Queueがもつ3つのQueueについて理解する
kube-schedulerはこれら3つのQueueがまとめてScheduling Queueとよばれ、一つのQueueのような形で協調して動作します。
僕たちのQueueにもこれらの3つのQueueを追加してみることにしましょう。
type SchedulingQueue struct {
lock sync.RWMutex
activeQ []*framework.QueuedPodInfo
podBackoffQ []*framework.QueuedPodInfo
unschedulableQ map[string]*framework.QueuedPodInfo
clusterEventMap map[framework.ClusterEvent]sets.String
}https://github.com/sanposhiho/mini-kube-scheduler/blob/scheduling-queue/minisched/queue/queue.go
ここからはこの3つのQueueの中でPodがどのように管理されているのかをもう少し詳しく見ていきましょう。(メソッド名などがkube-scheduler内のScheduling Queueとは少し異なるものがあります。)
まず、外部からのPodの追加と取り出しについてです。
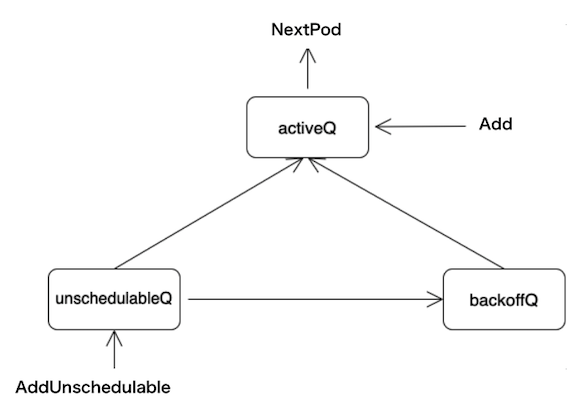
矢印に書かれているのはScheduling Queueに実装されているメソッドで、そのメソッドにより矢印の方向へPodが移動(追加 or 取り出し)するということを示しています。
Scheduling QueueにPodが新しく追加されるときに使用されるのがAddで、Scheduling Queueから先頭のPodが取り出されるときに使用されるのがNextPodです。これらは僕たちの一番初めに作ったシンプルなQueueにすでに実装されています。
そして、それとは別にunschedulableとなったPodをScheduling Queueに戻す際に使用されるAddUnschedulableというものが存在しています。これはScheduling Queueの内部的にはunschedulableQに追加されることになります。この際にUnschedulableの原因となったプラグインの情報などもunschedulableQに保存される場合があります。
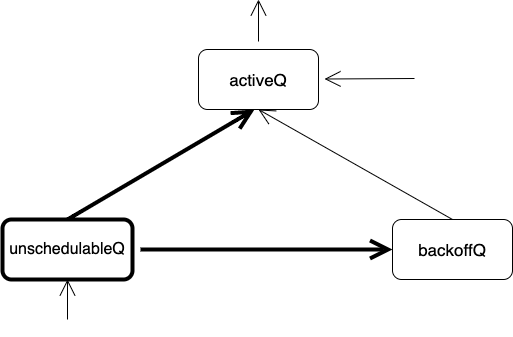
次にunschedulableQからactiveQやbackoffQへのPodの移動について見ていきます。
基本的に以下の2パターンが存在します。
- 60秒以上unschedulableQに存在するPodはbackoffQ/activeQに移動
- 特定のイベントの発行時にbackoffQ/activeQに移動
後者の「特定のイベント」に関しては次の章で解説+実装します。
backoffQとactiveQのどちらに移動するかは”Exponential backoffに準じ計算されるリトライの間隔”と”そのPodがunschedulableQに入ってからどのくらい時間”が経ったのかを比較することで判断されます。
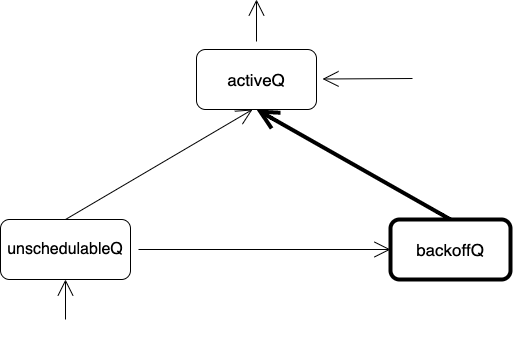
最後にbackoffQからactiveQへの移動についてですが、Exponential backoffの待ちが終了したPodをactiveQに移動されます。
さて、これにて3つのQueueの関係やPodの移動の流れの紹介は終了です。移動のパターンこそ多いですが、一つ一つはそれほど難しくなかったと思います。
Queueの実装に関してもそれほど特質して難しいポイントがなく、上記で紹介した流れを実装しているだけなので、説明を割愛します。
実装例での実装はこちらになります。
https://github.com/sanposhiho/mini-kube-scheduler/blob/scheduling-queue/minisched/queue/queue.go
スケジュールに失敗したPodをQueueに戻すようにしよう
さて、では僕たちのスケジューラーで実際にスケジュールに失敗したPodをQueueに戻すようにしてみましょう。
スケジュールに失敗したPodをQueueに戻すときは前述のようにAddUnschedulableを使用します。
// score
score, status := sched.RunScorePlugins(ctx, state, pod, fasibleNodes)
if !status.IsSuccess() {
klog.Error(status.AsError())
sched.ErrorFunc(pod, err)
return
}https://github.com/sanposhiho/mini-kube-scheduler/blob/scheduling-queue/minisched/minisched.go
例えば、Score拡張点の実行に失敗したときの場合を見てみましょう。このように失敗したときの動作はErrorFuncというメソッドにまとめてあります。
func (sched *Scheduler) ErrorFunc(pod *v1.Pod, err error) {
podInfo := &framework.QueuedPodInfo{
PodInfo: framework.NewPodInfo(pod),
}
if fitError, ok := err.(*framework.FitError); ok {
// Inject UnschedulablePlugins to PodInfo, which will be used later for moving Pods between queues efficiently.
podInfo.UnschedulablePlugins = fitError.Diagnosis.UnschedulablePlugins
klog.V(2).InfoS("Unable to schedule pod; no fit; waiting", "pod", klog.KObj(pod), "err", err)
} else {
klog.ErrorS(err, "Error scheduling pod; retrying", "pod", klog.KObj(pod))
}
if err := sched.SchedulingQueue.AddUnschedulable(podInfo); err != nil {
klog.ErrorS(err, "Error occurred")
}
}内容としては、framework.QueuedPodInfo という構造体に入れてAddUnschedulableに渡しているだけです。
そして、失敗した原因として渡されてきた引数errが*framework.FitErrorだった場合のみ、framework.QueuedPodInfoに情報が追加されています。
この*framework.FitErrorは一瞬だけ登場したのですが、覚えていますか?
それはFilter拡張点の実行を実装したときです。
feasibleNodesが0、すなわち候補として一つもNodeが残らなかった場合はframework.FitErrorという特別なエラーを返します。
ということで、このframework.FitErrorがErrorFuncに渡されたときというのは、「Filter拡張点で候補のNodeが一つも残らず、スケジュールに失敗した。」ということを意味しています。
この場合、framework.QueuedPodInfo にはUnschedulablePluginsフィールドにframework.FitError内のdiagnosisからUnschedulablePluginsが登録されます。
このUnschedulablePluginsにはスケジュール時にFilter拡張点にて一つ以上のNodeを却下した全てのプラグインが含まれています。
この情報はunschedulableQからのPodの移動の際に移動のパターンのうちの一つであった
特定のイベントの発行時にbackoffQ/activeQに移動
をする際に使用されます。
さて、これでスケジュールに失敗したPodもQueueに戻されるようになりました。僕たちのスケジューラーも完成間近です。
最後にunschedulableQにおける「特定のイベントの発行時にbackoffQ/activeQに移動」をサポートしましょう。
EventHandler による Queue の最適化
EventHandlerを皆さん覚えていますか?
EventHandlerとはKubernetesが提供する “リソースの変更をトリガーにあらかじめ登録した関数を実行してくれる仕組み” です。
これまでEventHandlerは二度の用途で登場しました。
- スケジュールされていないPodを見つけて、Queueに追加する
- Scheduling Cacheを最新の状態に保つ
(後者は僕たちのスケジューラーには未実装です。)
そしてkube-schedulerはScheduling Queueの最適化にもEventHandlerを使用しています。
それがunschedulableQにおける「特定のイベントの発行時にbackoffQ/activeQに移動」です。
プラグインにはEnqueueExtensionsというinterfaceが用意されています。
type EnqueueExtensions interface {
EventsToRegister() []ClusterEvent
}このEventsToRegisterというメソッドは「そのプラグインのFilterの結果が変わる可能性があるイベント」を[]ClusterEventの型で返却します。
プラグインはこのEventsToRegisterメソッドを実装することで、スケジューラーに自身のFilterの結果が変わる可能性があるイベントを伝え、スケジューラーはそのイベントをEventHandlerを通して監視し、イベント発生時に、Queueの操作を行います。
Queueの操作の詳細について踏み込みます。スケジューラーはイベントが発生したときにScheduling Queue内でそのイベントをEventsToRegisterに登録しているプラグインをUnschedulablePluginsとして持つPodをunschedulableQからbackoffQ/activeQへ移動させます。(前の章のおさらいですが、UnschedulablePluginsは”Filter拡張点にて一つ以上のNodeを却下した全てのプラグイン”がPodと一緒にunschedulableQに記録されたものです。)
これは、イベントの発生によって”以前のそのPodのスケジュールにおいてFilter拡張点で一つ以上のNodeを拒否したプラグイン”の結果が変化する可能性があり、再度スケジュールを試してみるとそのプラグインの結果の変化によりスケジュールに成功するかもしれないためです。
スケジューラーでEnqueueExtensionsをサポートする
文字で説明されてもすこし想像がつきにくかったかもしれません。では、僕達のスケジューラーにこのEnqueueExtensions.EventsToRegisterのサポートの実装を行ってみましょう。
実装例のブランチはevent-handlerです。
僕たちが丹精込めて作成してきたNodeNumberプラグインはFilter拡張点に対応していないので、kube-schedulerから適当なFilterプラグインを持ってくることにします。
そうですね、なんでもいいのですが、単純なプラグインなのでNodeUnschedulableプラグインを初期化時に有効にすることにしましょう。
このNodeUnschedulableプラグインは”Nodeの.Spec.Unschedulableを見て、trueのNodeをFilter拡張点で除外する”というものです。
このプラグインのFilterの結果が変化するのはどのような場合でしょうか。
- Nodeの
.Spec.Unschedulableの変更 - 新たなNodeの追加
の2つですね。1つ目は既存のNodeの.Spec.Unschedulableが変更された場合はそのNodeが除外されなくなる可能性があるので、結果が変化し得ます。2つ目は新たに追加されたNodeが.Spec.Unschedulableがfalseだった場合結果が変化します。
func (pl *NodeUnschedulable) EventsToRegister() []framework.ClusterEvent {
return []framework.ClusterEvent{
{Resource: framework.Node, ActionType: framework.Add | framework.UpdateNodeTaint},
}
}ということで、NodeUnschedulableプラグインを見るとEventsToRegisterにはその2つのイベントが登録されています。
さて、EnqueueExtensions.EventsToRegisterのサポートとしてスケジューラーがやるべきことはそれほど多くありません。特定のイベントが発生したらScheduling Queueで特定のPodをunschedulableQから移動させるだけです。
まずは、スケジューラーに登録されているプラグインのEnqueueExtensions.EventsToRegisterを集めて、適切なEventHandlerを設定する必要があります。
スケジューラーの初期化時にaddAllEventHandlersという関数が呼ばれてEventHandlerの登録周りのことをすべて行うようになっています。
func addAllEventHandlers(
sched *Scheduler,
informerFactory informers.SharedInformerFactory,
gvkMap map[framework.GVK]framework.ActionType,
) {
// unscheduled pod
informerFactory.Core().V1().Pods().Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return !assignedPod(t)
default:
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
// Consider only adding.
AddFunc: sched.addPodToSchedulingQueue,
},
},
)
buildEvtResHandler := func(at framework.ActionType, gvk framework.GVK, shortGVK string) cache.ResourceEventHandlerFuncs {
funcs := cache.ResourceEventHandlerFuncs{}
if at&framework.Add != 0 {
evt := framework.ClusterEvent{Resource: gvk, ActionType: framework.Add, Label: fmt.Sprintf("%vAdd", shortGVK)}
funcs.AddFunc = func(_ interface{}) {
sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(evt)
}
}
if at&framework.Update != 0 {
evt := framework.ClusterEvent{Resource: gvk, ActionType: framework.Update, Label: fmt.Sprintf("%vUpdate", shortGVK)}
funcs.UpdateFunc = func(_, _ interface{}) {
sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(evt)
}
}
if at&framework.Delete != 0 {
evt := framework.ClusterEvent{Resource: gvk, ActionType: framework.Delete, Label: fmt.Sprintf("%vDelete", shortGVK)}
funcs.DeleteFunc = func(_ interface{}) {
sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(evt)
}
}
return funcs
}
for gvk, at := range gvkMap {
switch gvk {
case framework.Node:
informerFactory.Core().V1().Nodes().Informer().AddEventHandler(
buildEvtResHandler(at, framework.Node, "Node"),
)
//case framework.CSINode:
//case framework.CSIDriver:
//case framework.CSIStorageCapacity:
//case framework.PersistentVolume:
//case framework.PersistentVolumeClaim:
//case framework.StorageClass:
//case framework.Service:
//default:
}
}
}https://github.com/sanposhiho/mini-kube-scheduler/blob/event-handler/minisched/eventhandler.go
前半はスケジュールされていないPodをQueueに追加するためのEventHandlerの登録で元からあった処理なので説明を省きます。
今回追加したのはそこよりもあとの部分です。引数として渡されたgvkMapをループしています。gvkMapはスケジューラーに登録されているプラグインのEnqueueExtensions.EventsToRegisterを集めたものです。
今回はFilter拡張点でNodeUnschedulableプラグインしか有効にしないため、とりあえずイベントがNodeに関するものであったときのみEventHandlerの登録を行うようにしてあります。
EventHandlerの登録にはbuildEvtResHandlerという関数を使用しています。中身はややこしく見えますが、イベントが発生したときにQueueのMoveAllToActiveOrBackoffQueueを実行しています。
MoveAllToActiveOrBackoffQueueは前の章で実装したメソッドのうちの一つです。前の章ではQueueの実装の詳細を紹介しなかったので少し解説を行います。
https://github.com/sanposhiho/mini-kube-scheduler/blob/event-handler/minisched/queue/queue.go
このメソッドはイベントが発生したときに適切なPodをunschedulableQから移動させるということを行っています。
func (s *SchedulingQueue) MoveAllToActiveOrBackoffQueue(event framework.ClusterEvent) {
s.lock.Lock()
defer s.lock.Unlock()
unschedulablePods := make([]*framework.QueuedPodInfo, 0, len(s.unschedulableQ))
for _, pInfo := range s.unschedulableQ {
unschedulablePods = append(unschedulablePods, pInfo)
}
s.movePodsToActiveOrBackoffQueue(unschedulablePods, event)
s.lock.Signal()
}引数として渡した「発生したイベント」とunschedulableQのPodを全てmovePodsToActiveOrBackoffQueueに渡しています。
func (s *SchedulingQueue) movePodsToActiveOrBackoffQueue(podInfoList []*framework.QueuedPodInfo, event framework.ClusterEvent) {
for _, pInfo := range podInfoList {
// If the event doesn't help making the Pod schedulable, continue.
// Note: we don't run the check if pInfo.UnschedulablePlugins is nil, which denotes
// either there is some abnormal error, or scheduling the pod failed by plugins other than PreFilter, Filter and Permit.
// In that case, it's desired to move it anyways.
if len(pInfo.UnschedulablePlugins) != 0 && !s.podMatchesEvent(pInfo, event) {
continue
}
if isPodBackingoff(pInfo) {
s.podBackoffQ = append(s.podBackoffQ, pInfo)
} else {
s.activeQ = append(s.activeQ, pInfo)
}
delete(s.unschedulableQ, keyFunc(pInfo))
}
}movePodsToActiveOrBackoffQueueにてそのPodをループで回して、移動すべきPodを移動しています。
ややこしく見えますが、それほどではなく、
s.podMatchesEventの部分でunschedulableの原因となったplugin(UnschedulablePluginsフィールドに保持されている)のスケジュールの結果が変わりうるイベントかどうかを判断- Yesだった場合にbackoffQかactiveQにPodを追加する
- 移動させた後にunschedulableQからそのPodを削除する
ということを行っています。
さて、ついにこれでスケジューラーでEnqueueExtensionsをサポートできました!
動作を確認してみる
さて、では動作しているかどうかを確認してみましょう。
今回は以下のシナリオを使うことにします。
- node0 ~ node9を作成する。ただし、全て
.Spec.UnschedulableがtrueなのでどのPodもこれらのNodeで実行できない (NodeUnschedulableプラグインがFilter拡張点ですべてのNodeを拒否する) - pod1を作成する
- pod1がどこにもスケジュールできなかったことを確認する
- node10を新たに作成する。node10は
.Spec.Unschedulableが未指定なのでPodを実行できる - pod1が再度スケジュールされ、どこにbindされたかを確認する
4で「node10が作成されたイベント」によってQueueが操作され、pod1がunschedulableQから移動されて、再度スケジュールされ、5でnode10にbindされることを期待するシナリオになっています。
実際に実行すると期待通りに動作することがわかります。

旅の終わり
さて、これにてこの記事におけるスケジューラーの実装はすべて終了しました!
今回の自作してきたスケジューラーはkube-schedulerと近い設計で実装するように心がけて実装していました。(Queueの一部やwaitingPodなどそのままkube-schedulerの実装を使用している箇所もあります)
そのため、この記事を読んでこの部分までたどり着いたそこのあなたはkube-schedulerの実装もあらかた読むことができるはずです。
https://github.com/kubernetes/kubernetes/tree/master/pkg/scheduler
この記事を読み終わると、kube-schedulerの内部実装もざっくり読めるようになり、kube-schedulerの拡張(プラグイン(後述)の作成など)なんてちょちょいのちょいでできるようになるはずです。
記事の冒頭で僕はこのように話していましたがいかがだったでしょうか。プラグインの実装なんてinterfaceを満たすだけでよいということがわかったと思います。
ではHappy kube-schedulerライフをお過ごしください。
質問や「これ違くね?」があればTwitter(@sanpo_shiho)で教えて下さい。
Next step…
実はこの記事で触れなかった機能もいくつか存在します。
- Preemption
- Reserve/UnReserve Plugin
- QueueSort Plugin
- Extender
- PodsToActivate によるCycleStateを通したQueue内の操作
Preemptionは特に面白い仕組みなので、興味がある方は実装を読んでみると楽しいかもしれません。
kube-schedulerにおける実装を見たい場合はこのPostFilterメソッドを追っていくと良いです。
https://github.com/kubernetes/kubernetes/blob/b5a610064c0ce0faccd4fd721ebc66cf4356fb7f/pkg/scheduler/framework/plugins/defaultpreemption/default_preemption.go#L85
明日のアドベントカレンダーの記事は@tkatoさんです。引き続きお楽しみください。

