
Merpay Tech Fest 2021は、事業との関わりから技術への興味を深め、プロダクトやサービスを支えるエンジニアリングを知れるお祭りで、2021年7月26日(月)からの5日間、開催しました。セッションでは、事業を支える組織・技術・課題などへの試行錯誤やアプローチを紹介していきました。
この記事は、「メルペイにおけるSLOの活用事例-信頼性を定義しよう」の書き起こしです。
足立紘亮氏:それでは「メルペイにおけるSLOの活用事例-信頼性を定義しよう」ということで 、SREチームの足立が発表させていただきます。よろしくお願いします。

まず、簡単に自己紹介させてください。SREチームの足立と申します。メルペイには2019年入社で、SREチームとしてサービスの品質を担保するための仕組みづくりであったりとか、SLOを設定するための基盤の開発等を行ってきました。きょうの発表はSLOに関することになります。また、趣味はキーボードをつくることです。

きょう話すことの概要です。まず初めに、メルペイSREチームについて簡単に紹介させてください。そのあとにSLOの話になるんですけども、SLOに関する用語の説明を簡単にします。そのあとにメルペイにおけるSLOの運用ということで、実際にどのように設定していて、どう運用しているかという話をします。最後に、活用事例としてSLOアラートについて発表させていただきます。
メルペイSREチーム

まず、SREチームについてです。SREという言葉自体、ご存知の方は多いかと思いますけども「Site Reliability Engineering」の略です。メルペイを安定して動かすために、インフラとか、マイクロサービスのリリースや、運用などをエンジニアリングするチームになっています。

ミッションの1つとしては「当たり前のようにメルペイを使えるようにする」ということです。メルペイを利用するお客さまにとって重要なことは、信頼性が高いということになります。メルペイは金融サービスなので、もちろん高い信頼性ということが求められるわけです。

具体的にどういう信頼性が求められるかというと、いつでも使える高い可用性です。何かを支払いするときに動かないとなると困るので高い可用性が必要です。あとは、支払うときのレスポンスです。早い方がいいので、素早いレスポンス性能が求められます。あと、当然ですけども、お金の計算間違っていると困ってしまうのでお金の計算の正確性など、こういう信頼性の高さが求められます。

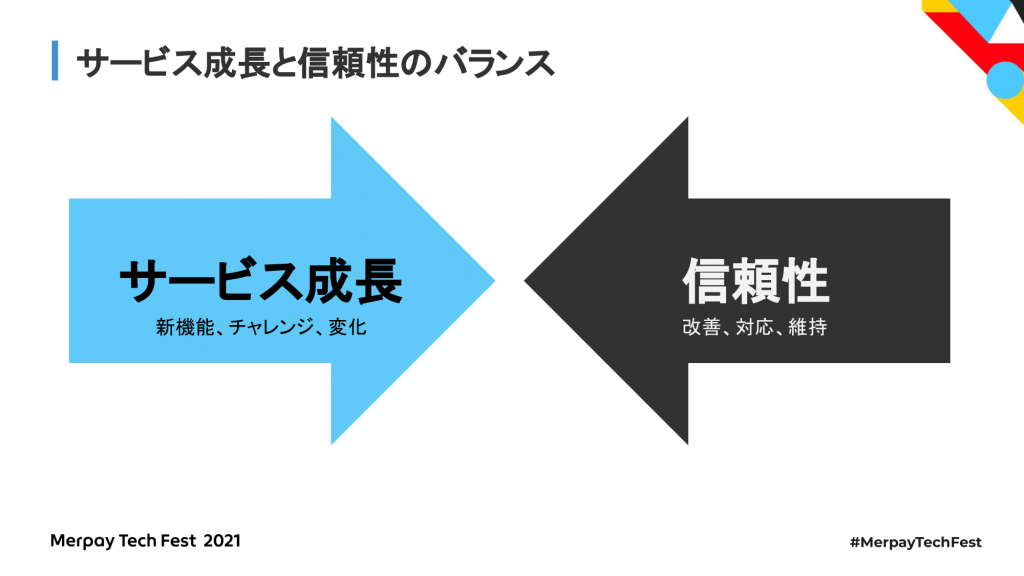
サービスを成長させるためには、新機能のリリースとか、チャレンジとか、それに伴う変化が必要なわけですけども、これは、信頼性を高めることに相反することであると一般的には思われています。例えばサービスのリリースはインシデントが発生しやすいのでリスクが高まります。信頼性を損ねる可能性も高くなるんですけども、サービスを成長させるためには新機能リリースというのは必須なので、サービスの成長と信頼性のバランスを取ることが大事になってきます。
一般的には信頼性が低いサービスというのは、著しくお客さまの体験が悪くなっている状態で、信頼性を上げると体験が良くなると言われています。当然のことながら、ある一定以上の信頼性の高さを求めると、それ相応の運用のコストと時間がかかってきます。なので、お客さまの期待値を見極めて信頼性の目標を決めて、期待値とコストのバランスを取ることが重要になってきます。実際問題、例えば可用性100%のものをつくろうとすると、いくらコストを払っても現実的な数字にはならない、限界値があると思っています。
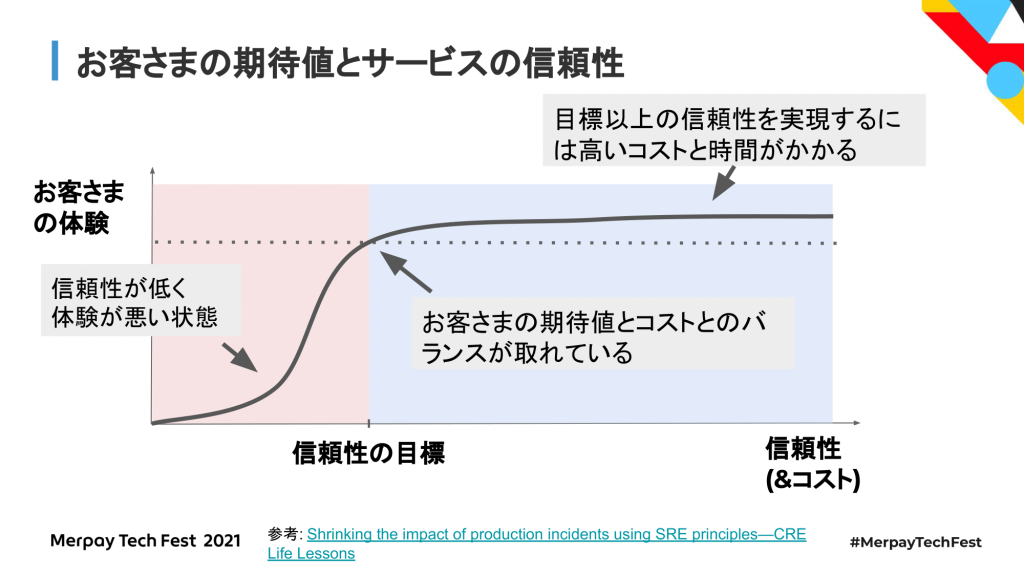
信頼性の目標を決めるうえで使える概念として、SLO(Service Level Objective)というものがあります。理想的なSLOというのは、お客さまの期待値とコストのバランスが取れている目標になります。SLOを決めることで、目指すべき信頼性を決めるだけじゃなく、次のサービスの成長への機会をつくる、チャンスをつくることができると思っています。本セッションでは、メルペイにおいて、どのようにSLOを使っているのか、どのように導入しているのかということも紹介していきます。

その前に、各用語について紹介させてください。
SLI / SLO / Error Budget

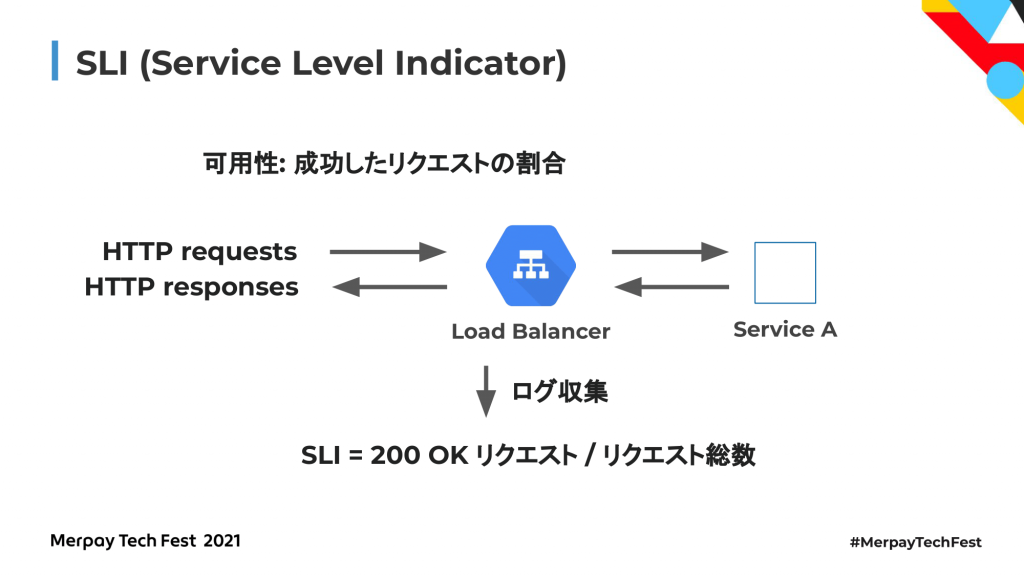
まず、SLI(Service Level Indicator)です。サービスの信頼性を測るための指標になります。お客さまの満足度を数値として計測可能なものを選ぶのが良いとされています。例えば可用性であれば、成功したリクエストの割合であったりとか、レイテンシーであれば100ミリ秒以内で完了するリクエストの割合などが挙げられます。

具体的にSLIをどうやって取るかというと、具体例として成功したリクエストの割合を取りたいというとき、Service Aという簡単なウェブアプリケーションがあったとして、前段にロードバランサーがいる状態を考えます。この前段のロードバランサーというのは、例えばHTTPのリクエストを受け取ってレスポンスを返します。なので、このロードバランサーのログを収集して正常なリクエストとリクエストの総数を取って、正常なリクエストの割合を取れ、これがSLIになります。
次に、SLO(Service Level objective)です。サービスの信頼性の目標値となるものです。SLIに対応して期間と目標値を設けたものがSLOになります。例えば成功したリクエストの割合が30日間で99.9%、レイテンシーであれば100ミリ秒以内で完了したクエストの割合が7日間で99%というものが例として挙げられます。

SLOの種類は2つあって、おもにRequest-based SLOと呼ばれるもの、またはWindow-based SLOと呼ばれるものがあります。言葉の定義自体は、GCPとかDatadag上でそれぞれ定義があるんですけども、大まかには同じような定義でこのように分かれます。Request-based SLOのほうは言葉のとおり、リクエストの割合にフォーカスしたSLOになっています。Window-based SLOのほうはリクエストじゃなくて、時間の割合にフォーカスしたSLOになります。メルペイとしては、SLOとしてRequest-based SLOではなく、Window-based SLOのほうを使っているんですけども、徐々にRequest-based SLOのほうにシフトしていく予定になっています。

具体的にSLOという言葉自体を紹介したんですけども、実態としてどういうものかということを説明させてください。成功したリクエストの割合が30日で99.9%というのがどういう意味かというと、SLIは正常なリクエストの割合でした。これを30日間計測するとします。例えば100rps(request per sec)、1秒間に100リクエスト来るようなエンドポイントの場合を考えます。このエンドポイントに対して上記のSLOを設定した例を考えます。このときのリクエストの総数というのは2億5,900万になります。それに対するSLOなので99.9%をかけた値がSLOになります。同時に、許容できる異常リクエスト数が計算できて、計算式は「リクエスト総数*1-SLO」になって、25万9,200となります。

もう1つ重要な概念として、Error Budgetというものがあります。Error Budgetというのは、SLOに対して許容できる異常系の量になります。先ほどの例で許容できる異常リクエストを紹介したんですけども、これがError Budgetになります。なので、Error Budgetは25万9,200であるといえます。25万9,200エラーまでであれば30日間許容できると。これ以上エラーが発生してしまうと、SLOが達成できなくなるというような意味合いになります。

具体的に、Error Budgetが25万9,200というのはどういう値かというと、例えばデプロイミスでエラー率が100%になると、エラー率が100%というのは1秒間に100エラーが発生するという意味です。そうなると43.2秒でBudgetが枯渇します。

別の例として、バグを仕込んでエラー率が1%になると3日間でBudgetが枯渇すると。枯渇することによってSLOが達成できなくてお客さまの満足度が下がるというような解釈になります。
メルペイにおけるSLO の運用

続いて、メルペイにおけるSLOの運用について詳しく説明をしていきます。

メルペイにおけるSLOの運用の特徴ですけども、冒頭で申し上げたとおりメルペイでは高い信頼性が求められているので、これに答える必要があります。メルペイはマイクロサービスアーキテクチャーを採用していて、1つのプロダクトで50を超えるマイクロサービスで構成されています。それらのマイクロサービスの開発運用には、10を超えるプロダクト開発チームがあります。さらに、これを支えるためのSLO基盤として、SREでいかに効率よくSLOを設定するか、モニターをつくるかといった基盤や、現状のError Budgeの確認を分かりやすくするためのダッシュボードみたいなものをつくっています。これらについて詳しく説明をしていきます。

まず初めに、マイクロサービスアーキテクチャーとSLOということで簡単にメルペイのアーキテクチャーを紹介します。メルペイは、GCP上のKubernetesで動いていて各マイクロサービスがpodという形で配置されています。クライアントからリクエストが来ると前段にいるロードバランサーが受けて、さらにその次のAPI Gatewayという、これもマイクロサービスですけども、こいつが受けますと。このマイクロサービスが認証するためのAuthorityサービスに問い合わせて認証をして、以後、サービスを提供するAPIサービスであったりとか、各サービスにリクエストが渡ってレスポンスが返るような、そういう仕組みになっています。マイクロサービス間の通信というのは、基本的に内部で行われています。

各マイクロサービスはそれぞれ開発チームが分かれていて、開発と運用を行っています。SREは、基本的には横串式の組織になっていて全体の運用を見ています。場合によっては、特定のチームに入って細かいところの運用も行っています。

SLOの設定自体は、各開発チームが担当のマイクロサービスに対して責任を持って設定や調整を行っています。SLOに関しては、そのマイクロサービスの性質によって設定している観点が違うんですけども、共通して可用性とレイテンシーに関しては重要なエンドポイントごとに設定しているというのがメルペイでは一般的になっています。設定自体は、SREチームが直接SLOを設定するということはまずなくて、そのマイクロサービスの特徴とか、ほかからどのように呼ばれているかとか、どういう使われ方をしているかというのが最も詳しいであろうDevチームとか、その担当のプロダクトマネージャーが責任を持って設定・運用するようにしています。SREチームは、それらの設定のサポートとか、数値の調整の仕方とか、考え方とか、または、SLOを設定しやすくするような基盤づくりとか、文化づくり等を行っています。

次に、マイクロサービスとSLIということで、どのようにしてSLIを取っているかという話です。われわれのマイクロサービスは、基本的にはGoでつくられています。マイクロサービスをつくるための共通ライブラリも多数存在している状態です。マイクロサービス間は、基本的にはgRPCで通信を行っていて、間にLBが入るということはなく直接やり取りしています。SLIのメトリクスを収集する方法として、先ほどLBのログから収集する方法を紹介したんですけども、このようなわれわれの構成上、LBからではなくてアプリケーションログから直接取るようにしています。取り方としては、gRPCのサーバーのインターセプターで共通ライブラリを使っているんですけども、ここでDatadogのカスタムメトリクスを取るような実装が入っていて、Datadogに送るというような仕組みになっています。

各マイクロサービスに関するデータは、サービスごとにSpecファイルというのを用意して管理しています。Specファイルの中身については、サービスの名前とか概要とか、開発しているチームの情報とか、docsの情報とか、いろんな情報が入っているんですけども、SLOの定義もここで行っています。ここで挙げた例の前半の部分は、とあるgRPCのエンドポイントに関する可用性のSLOの定義。後半部分は、HTTPのエンドポイントに関するレイテンシーの定義の例を挙げています。

各サービスの開発者はこのファイルにSLOを定義すると、この情報をもとにTerraformを経由してDatadog上にSLOの設定が反映するような仕組みになっています。先ほど説明したとおり、Goアプリケーションでカスタムメトリクスを取ってDatadogのほうに送られているので、ここでこのカスタムメトリクスが使用されます。また、エラー数の増加とかError Budgetの減少によって、各種サービスのslackとかPagerDutyにアラート通知が行くような仕組みになっていて、そのためのDatadog上のモニター設定もTerraform上からSLOの定義に沿って自動的につくられるようになっています。さらに、SLOダッシュボードと呼んでいるダッシュボードをつくっていて、サービス全体のSLOの様子とか、エンドポイントごとのSLOの様子を確認できるようにしています。

SLOダッシュボードについてもう少し深掘りすると、信頼性が低下している=Error Budgetが低下していることが明確に分かるようにしています。開発チームに限らず、組織のメンバーがこのダッシュボードを見てサービス全体の信頼性の低下に気づきやすくしています。気づいて、次のアクションを取れるような体制になっています。ここの例で挙げているのは、サービス全体を確認するようなダッシュボードになっています。

あと、深掘りできるようにサービス単体を確認するダッシュボードもつくっていて、エンドポイントごとのSLOの様子が見えるようになっています。

次に、SLOのメンテナンスについてなんですけども、一般的には適切なSLOを設定することは難しいと言われていて、われわれも結構この設定自体は苦労している状態になっています。定期的に見直して目標を調整することが重要になってきます。メルペイでは、信頼性の定期チェック項目というもの用意していて、SLOに限らず信頼性に関するチェックというのを定期的に行っています。これによって開発チームが定期的にSLOを見直す機会をつくっていて、適切なSLOを設定していくというような体制をつくっています。
活用事例:SLO アラート

次に、メルペイにおけるSLOの活用事例ということで、SLOアラートについて説明していきます。

まず初めに、適切なアラートとは何かということを考えてみます。お客さまの影響のあるトラブルが発生したときにすぐ気づけるとか、システム復旧や原因特定などのアクションがすぐ取れるというようなものが適切なアラートとは言えるかなと思っています。逆に、トラブルが発生してからアラートまでの時間が長いとか、特にアクションをする必要がないのにアラートが鳴っているとか、こういうものは不要なアラートではないかなと思います。

次に、アラートが鳴りすぎてないかを確認します。あらゆるメトリクスに対してモニタリングしているというケースがあるかなと思っていて、例えばCPU使用率とか、メモリの使用率とか、ネットワークのI/Oとか、いろんな指標でメトリクスを取ってモニタリングをしているというケースがあるかなと思っているんですけども、これらの数値を監視してアラートを鳴らす必要が本当にあるかどうかというのを考えます。特にわれわれもKubernetes上でサービスを運用しているので、例えばpodのCPU使用率が80%を超えたら鳴らすみたいな設定をしたとして、果たして80%超えたからといってお客さまに影響が出るかっていうと、そんなことはまず設計上ないわけで、podが1つ落ちたところで、サービス全体として影響が出ないようなアーキテクチャーをしているので特に問題がないですと。これらのメトリクスというのはシステムの状態を知るのに有力なメトリクスなので、グラフをつくってダッシュボードで見るのはいいんですけども、必ずしも何か悪いようになってもお客さまに影響が出るわけではないので、アラートを流す必要があるかどうかというのはよく考える必要があるかなと思います。

不必要なアラートが多いとどうなるかというと、不必要なアラートが多いということは、本来受けるべき必要なアラートが埋もれてしまいます。なので、オオカミ少年効果のように有力なアラートを逃してしまう可能性もあります。あとは割れ窓理論的な話で、不必要なアラートがいっぱいに鳴っているけれども、対処しないでそのまま放置してしまうということもあり得ます。そうすると、アラート対応による疲弊が起こってきます。不要なアラートもバンバン鳴るので、それをいちいち見なきゃいけない、それを見ていると疲弊してしまいますということです。さらに、アラートがいっぱい鳴っているということは、運用コストが増加するということです。運用コストが増加すると開発している時間も下がるので、開発力の低下が引き起こってきてしまうかなと思います。重要なことは、お客さま影響がある場合のみアラートを鳴らして、不要なアラートを減らすということです。これが大事になってきます。

ここで、SLOを基準としたアラートについて考えてみます。SLOは、サービスの信頼性の目標値でした。これが満たされないとお客さまの体験が下がって満足度が下がります。逆に、SLOが達成できている状態を維持できるとお客さまの満足度が満たされると言えます。お客さまの期待値と信頼性が、ちょうど良いバランスが取れているというのがSLOの設定値の部分であって、これよりも信頼性を下げないようにする必要があります。この状態になってからアラートを鳴らすのでは遅くて、もう少し前の段階でアラートを鳴らすのが必要になってきます。Error Budgetで考えるとこのような感じになるかなと思います。信頼性が高い状態というのはError Budgetが残っている状態で、お客さまの体験が良い状態です。信頼性がちょうど目標値になった状態というのはError Budgetがゼロの状態で、これより下がるとError Budgeが枯渇してお客さまの体験が悪くなるということが言えるかなと思います。

SLOのアラートの手法としては、いろいろあるんですけども、Burn Rateに基づいたアラートを紹介します。

具体例として、SLOは先ほどから利用している、成功したリクエストの割合が30日間で99.9%であるというものを利用します。このときに、Error Budgetの消費速度を考えるんですけども、この消費速度がBurn Rateになります。この場合は、1時間でError Budget2%を消費したらアラートを鳴らすというのがBurn Rateに基づいたアラートになります。例としては、100rpsのエンドポイントの場合は、Error Budgetに対する2%なので5,184エラー、これを超えるとアラートが鳴るというモニター設定になります。

具体的に、この5,184エラーというのがどういうことかというと、例えばエラー率100%の場合は、51.84秒でアラートが鳴るという意味になります。ただ、エラー率1%の場合は、1時間で3,600エラーとなるので5,184エラーに達しないのでアラートが鳴らないという状態になります。なので、エラー率1%を継続してしまうと、アラートが鳴らないにも関わらずError Budgetが枯渇してしまうことがあるという問題があります。この例で挙げたBurn Rateのアラートの設定1つだけだと満たせないケースが存在して、必要なアラートがつくれていないという状態になってしまいます。

そこでもう1つ、Multi-window、 Multi-Burn-Rateアラートの例を挙げます。これは、複数の計測期間とか、複数のBurn Rateを組み合わせた手法になっていて、複数の計測期間というのは、さっき1時間というwindowがあったんですけども、1時間のwindowだけじゃなくて、5分とか10分とか短い期間を設けたりとか、長い期間として数時間とか、数日という期間を設けると。あとは、複数のBurn Rateを組み合わせるということで、さっきの例だと1時間で2%のBurn Rateだったんですけども、もっとゆるいBurn Rateのものを組み合わせるとか、もっと急なBurn Rateのものを組み合わせるという、複数のアラートを組み合わせて先ほどのアラートの欠点を補うというのがこの手法になります。ここについてちょっと詳しく説明したいんですけども時間の関係上できないので、サイトリライアビリティワークブックに詳しく載っているので参照してください。

SLOアラートの手法の選択ということで、先ほど、各マイクロサービスにスペックファイルというものが存在していて、そこで定義しているSLOに基づいてモニターが自動生成されるという話をしました。ここの仕組み自体、Terraformの部分がモジュールになっていて、専用のSLOモジュールと呼ばれるものをつくっています。ここの設定の中でモニターの手法についても選択できるようになっていて、例えばmulti-window-multi-burnrateのものを選択すると、そしてそのアラートの手法が有効になって各モニターに反映されるみたいな仕組みをつくっています。現状でメルペイのほうでは、まだmulti-window-multi-burnrateというのは検証段階でまだ使ってないんですけども、徐々に効果が良ければ使っていく、置き換えていく予定になっています。

低トラフィックに対するエラー率とアラートということで、アラートの設定において、低トラフィックに対する対策というものが必要になってきます。低トラフィックというのは、リクエストが少ないということです。リクエストが少ないエンドポイントは、1つのエラーでアラートが鳴ってしまうというケースがあり得ます。例えば、SLOが成功したリクエストの割合が30日間で99.9%、SLOアラートが5分間でError Budgetの2%を消費したらアラートを鳴らすという設定をしているとしたら、対象のエンドポイントが低トラフィックなので今回は1分あたりのリクエストが1 (1 rpm)という例を考えます。Error Budgeの計算式を省きますけどもError Budgetは43.2になって、5分間の許容できるエラー数がこの2%なので0.864ですと。なので、5分間の間に0.864回エラーが発生するとアラートが鳴るという仕組みになっていて、1つでもエラーが発生してしまうとアラートが鳴るというようなことが起き得ます。

これについても、ワークブックのほうでいくつか解決方法が載っているんですけども、実際にメルペイのほうで効果があった方法を1つ紹介します。この手法というのはすべてのサービスで共通して使えるわけではなくて、使えるかどうかというのは十分に吟味して使う必要があるんですけども、今回のケースだと使えたというような紹介になります。低トラフィックのエンドポイントでも、一定数のエラーがメルペイでは発生していました。ただ、エラーが発生しているんですけども、リトライ処理とか自動復旧のための仕組みがいくつか入っているので、実際にはお客さまへの影響はないものだったというのが挙げられます。なので、エラー率に関わらず1件~2件のエラーが起きたとしても、アラートを鳴らさないように制御するということをしてみました。低トラフィックというのは、具体的にいうと、深夜帯とかリクエストが下がるときに起きやすいんですけども、こういうときにアラートが鳴ってしまうと睡眠を妨害することになり得るんですけども、この対応を入れることによって不要なアラートがなくなって、みんな安眠できるようになったということがありました。

最後に、SLOアラートとPlaybookということで、アラートが鳴ったあとの話です。アラートが鳴ったあとに、いかに素早く対処するかという方法について軽く紹介します。われわれは今、Playbookと呼ばれるものを整備している途中で、これは何かというと、対象のエンドポイントに関する情報とか、一時対応の方法などが示されたドキュメントになります。これによって、エラー影響範囲や対処方法が明確になって復旧までの時間が短くなるというもので、先ほどスペック上にSLOを定義して、それが自動的にモニター設定になるという話をしたんですけども、ここにPlaybookを混ぜ込んで、モニターにPlaybookを埋め込むというものをつくろうとしています。そうすると、いざオンコールの人が何かアラートが鳴ったとして、slack上でアラートの詳細を見るとPlaybookの情報が載っていて、そこを見るとまず初めに何をしなきゃいけないかとか、誰に連絡しなきゃいけないかとかというのが明確になっているので、オンコールの方はそれを見て素早く反応できるという仕組みをつくろうとしています。

本日話したことのまとめになります。メルペイにおけるSLOの活用事例ということで、メルペイにおけるSLOの運用について紹介しました。また、その例としてSLOアラートについて詳しく説明しました。また、信頼性を定義しようということで、信頼性を可視化して改善のアクションがすぐ取れるようにしようということ。あとは、お客さまに影響があるインシデントが発生したらアラートを鳴らすようにしようということで、不要なアラートをなくしていこうという話をしました。
以上になります。ご清聴ありがとうございました。

