Merpay Tech Fest 2021は、事業との関わりから技術への興味を深め、プロダクトやサービスを支えるエンジニアリングを知れるお祭りで、2021年7月26日(月)からの5日間、開催しました。セッションでは、事業を支える組織・技術・課題などへの試行錯誤やアプローチを紹介していきました。
この記事は、「Dataflow Templateを利用した宣言的なデータパイプライン」の書き起こしです。
永井洋一氏:それでは「Merpay Tech Fest 2021」ということで「Dataflow Templateを利用した宣言的なデータパイプライン」という題で、永井から発表させていただきます。

まず、簡単に自己紹介をさせていただきますと、私はメルペイのSolutionsチームに所属しております。Solutionsチームは何をしているかというと、このチームは社内の特定のプロダクトを持つチームではなく、プロダクトを持っているチームに対して技術的なお手伝いをしたり、共通の困りごとを探して、それに対して役立つSolutionsを提供しています。またその成果をOSSとして出すこともありますし、社内ツールとして提供することもあります。
現在、私はデータエンジニアという肩書で、社内で共通で役に立つデータのパイプラインを社内向けに公開しております。

今回のアジェンダです。私が課題として取り上げたものは、まず、マイクロサービスという仕組みに対してデータ処理を行おうとしたときに発生する課題について説明させていただきます。
次に、その課題に対するSolutionとして、私が開発したMercari Dataflow Templateでどういうことができるのかを紹介をさせていただきます。
最後に、Mercari Dataflow Templateがどういう仕組みで動いているのか、その中身についての技術的な解説をさせていただくという流れで進めさせていただきます。
マイクロサービスにおけるデータ処理の課題について
では、最初の課題として、マイクロサービスにおけるデータ処理の課題について紹介させていただきます。

マイクロサービスにおけるデータ処理の課題を説明します。弊社メルペイではいろいろな機能をつくっていますが、各チームが独立して技術選定などを行い、APIを通じてやり取りをして1つの機能を提供して、複数の定義を連携して提供する仕組みを採用しています。これは、マイクロサービスのチームごとに、柔軟に技術選定だったり、つくり方だったり、開発を進められるというメリットもあるのですが、データ処理をしようとした場合の課題として、似たようなデータ処理を行うためのツールを別々に開発してしまいがちということがあります。
これは、データ処理に限った話ではなくて、データをあるところからあるところに動かしたいとか、チームごとで少し違いはあるけれども似たような処理をやりたいとき、この似たような機能を各チームで独立してつくってしまうことがあって、非常に工数がもったいないということがあります。この課題に対して、簡単な設定で動かせる再利用可能なデータパイプラインを提供できればいいのではないかと考えました。
次の問題として、マイクロサービスをまたいだデータ処理が面倒ということが挙げられます。マイクロサービスは、独立して機能開発をしていくのですが、サービスごとに連携するときはAPIを提供して、そのAPIを経由していろいろなデータのやり取りを行うことが一般的ですが、大規模なデータを処理したいときは、APIを開発しないといけなかったり、あるいはキャンペーンなどで一時的にアドホックにデータ連携をしたいといったときは、そのためだけにゼロからAPIをつくるのは非常に工数がかかってしまって大変という問題があります。
このマイクロサービスをまたいだデータを統合的に処理するような仕組み、簡単にデータを連携して処理できる仕組みがあれば便利なのではないかと考えました。
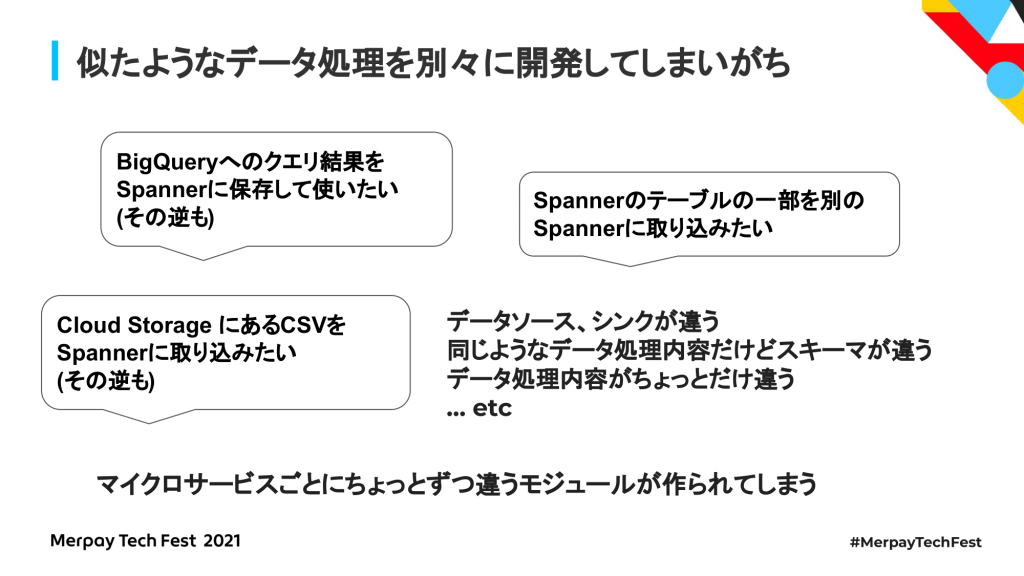
まず、似たようなデータ処理を別々に開発してしまいがちということに関して、例えば社内でよくある例としては、BigQueryに対してクエリー結果を出してSpannerに保存して使いたい、あるいはその逆のケースがあります。
弊社ではマイクロサービスのデータを、データ分析用としてBigQueryに集めてデータ分析がしやすいようにしているのですが、キャンペーンなどをしたいときに、例えば特定のアクションを取ったユーザに対してクーポンを送るということをやろうとしたとき、マイクロサービスをまたいだデータをいったんBigQueryに集め、そこからキャンペーン対象のユーザを絞り込むクエリーを書いて、その結果をクーポン発行のアプリケーションデータベースとしてSpannerに保存したいということがあります。
あるいは、マスタデータとして外部の事業者から受け取ったCSVデータをアプリケーションで使えるようにSpannerに取り込みたいということもありました。もしくは、外部の事業者向けにCSVとして吐き出したいということもあります。また、Spannerのテーブルの一部データを別の用途に使うため、別のテーブルに取り込みたいということもあります。
それ以外にも、データのソースやシンクごとで、データのやり取りの組み合わせがあって、同じようなデータ処理だけどスキーマが少し違うとか、データの処理する内容が少し違うということで、それぞれのケースでデータ処理を個別に開発してしまうという課題がありました。

次に、マイクロサービスをまたいだ処理が面倒ということの例について、マイクロサービスにはいろいろなサービスがあり、それぞれ別のデータベースを採用しています。その別々のマイクロサービスからデータを集めて結合したいとなると、いろいろなデータソースからまとめてデータを持ってくるというものをつくる必要があります。
使われている例としては、ユーザごとに直近のアクティビティを集計しようとすると、それぞれのマイクロサービスが持っているデータベースから大量のデータを読み出し、ユーザごとに集計する処理をつくる必要があり、それをAPI経由でやろうとするとすごく時間がかかってしまいます。
また、BigQueryに持っていったあと、BigQueryで集計スケールを書こうとすると、どうしても同期するタイミングでいったん挟んでしまって処理が遅れてしまうということもあります。Batchであればまだやりやすいのですが、それをストリーミング処理でやろうとすると、さらに難易度が上がってしまいます。このようなときに共通で使えるツールがあれば非常に便利ではないかと考えました。
Mercari Dataflow Templateの紹介
そのSolutionとして、Mercari Dataflow Templateの紹介をさせていただきます。

Mercari Dataflow Templateは、プログラムのコードを書かずに、あらかじめ定義されたモジュールを組み合わせて、データ処理を簡単に定義できるツールです。いったん定義した設定ファイルをコマンドラインでSubmitすると、Cloud DataflowのJobとして手軽に実行できます。
この例ですと、Spannerが2つとBigQuery、それぞれマイクロサービスをまたいでそれぞれのクエリー結果を1カ所に集め、それをSQLで何らかの処理をし、その結果を別々のSpanner、それぞれのマイクロサービスのテーブルに保存するという処理を設定ファイルとして記述しています。
その設定ファイルをMercari Dataflow Templateを使ってJob実行すると、GCPのデータ処理サービスであるCloud DataflowのJobが立ち上がって設定ファイルで指定した処理が実行されるという仕組みになっています。

具体的な使い方についてですが、設定ファイルに何が定義できるのかというと、データの処理内容は右側にあるような感じで、JSON形式で定義します。処理内容は大きく3つの種類に分けられて、入力元のデータを取ってくる方法を定義するためのsourcesと、データに対して何らかの処理を行い、その処理結果を加えて後段に流すtransformsというモジュールと、データを指定した場所に保存するためのsinksがあります。この3つの種類のモジュールを組み合わせてデータ処理の内容を定義します。基本的には、sourcesからデータを読み込んで、transformsで処理をして、結果をsinksに保存するというような流れで処理を定義します。
書き方としては、sourcesの中にnameというユニークになるような名前と、具体的な処理内容が定義されたモジュール名を指定し、そのモジュールごとに定義されたパラメータを指定して、入力としたいデータを出力するモジュールのnameをinputの値としてそれぞれが参照し、数珠つなぎで処理を定義する形になっています。ちなみに、1つのモジュールの出力を複数のモジュールが利用したり、Transformを省いたり、連結したり、かなり柔軟に定義することも可能となっています。

使い方についてですが、実際に処理のラインをJSONで定義したあと、Cloud Storageにアップロードし、Dataflowを起動するためのツールであるgcloudコマンドでCloud Storageのパスと、あらかじめMercari Dataflow TemplateをデプロイしたCloud Storageのパスをそれぞれ指定して実行すると、DataflowのJobが起動されます。
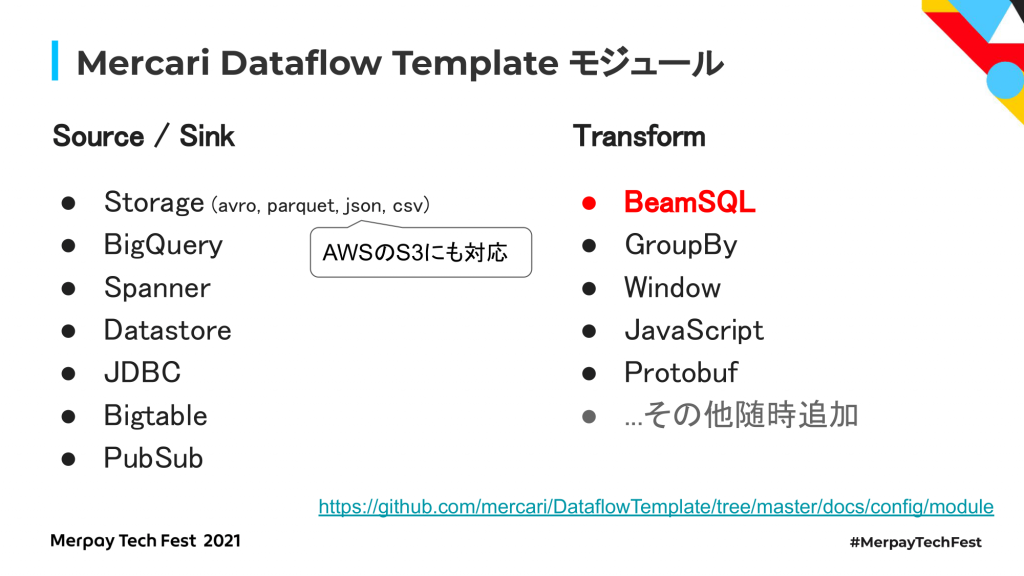
事前に定義されたモジュールについてですが、sources、sinks、trankformsの3種類の、もともと定義されているモジュールを組み合わせて使う形になっており、今のところここで紹介しているものが組み込みで提供されています。
Cloud Storage、BigQuery、Cloud Spanner、Cloud Datastore、JDBC経由でつなぐためのJDBC、Bigtable向けのモジュールや、ストリーミングデータのメッセージを処理するための入出力としてPubSubをサポートしています。
Transformsとしては、SQLで指定したデータを処理するためのBeamSQLモジュールや1つのデータを何らかのキーで集計したり、JavaScriptで何らか処理したりするようなモジュールを提供しています。今回は、複数のモジュールから入ってきたデータをSQLでまとめて処理するために便利なBeamSQLについて紹介したいと思います。

BeamSQLは、SQL形式で定義された処理を実行するためのモジュールです。BigQueryやSpannerなど、別々の種類のデータソースから読み込んだデータをSQLで定義した処理内容でJOINしたり、加工したりして使うこともできます。
また、Batchだけではなくリアルタイムで流れてくるデータに対してもSQLで指定した処理を実行することができます。SQLで処理内容を定義できるので、非エンジニアの人でもやりたい処理をSQLで定義すれば、簡単にBatchやStreaming処理を実行できます。

利用例について取り上げてみたいと思います。ここでは、それぞれ異なるマイクロサービスの2つのSpannerテーブルに対して別々に実行したクエリ結果と、BigQueryに対して実行したクエリ結果をJOIN、加工して別々のSpannerテーブルに保存する例を紹介します。
この例は、実際に社内で使われているのですが、数千万レベルのオーダーデータを30分程度で処理を完了しています。具体的にはBigQueryから読み込んだデータとSpannerから読み込んだデータ、ユーザIDでJOINして、片方のテーブルになかったフィールドの値を別のテーブルのフィールドの値に差し込むというようなことをやっています。このように別々のデータソースにあるデータをSQLを使って簡単に結合する使い方ができます。

次は、Streaming処理の例になります。PubSubでページビューのログが流れて来るような場合に、URLごとに1分間ごとのアクセスが多いページをリアルタイムに集計したい場合、BeamSQLを使ってストリーミング処理を実行する例です。
このような感じでPubSubから入ってきたデータに対してSQLを処理を指定すると、ページごとのアクセス数が集計されるので、その結果をCloud SpannerやCloud Datastoreに保存して、訪問ユーザに高いものから優先的に提示するという仕組みを作ることができます。

Streaming処理では、データソースは1つだけではなくて複数のデータソースから処理をつなげることもできます。
この例では、一定期間内のユーザの様々なアクションをユーザごとに集計するようになっていて、ユーザのアクションが別々のデータソースから発生する場合はそれぞれのデータソースからデータを集め、ユーザIDごとの特定の時間ごとに集計をして、一定期間内に一定のアクションを一定回数以上送った相手に対して、ニアリアルタイムで何らかのアクション、例えばクーポンを発行したいという場合などに、この例のようにSQLを使ってデータを結合することができます。
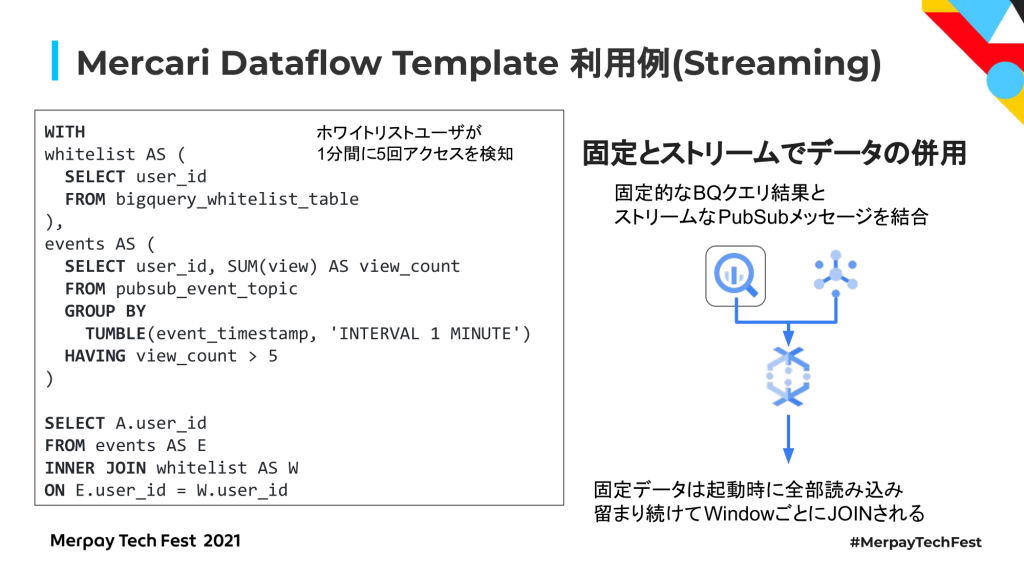
Streamingデータ同士だけではなく、マスターデータなどの固定的なデータとStreamingデータを結合することもできます。全ユーザではなく、あらかじめ定義しておいたホワイトリストに入ったユーザに対してだけ、一定期間内に何らかのアクションを起こした場合にクーポンを送るなどのアクションを起こすような場合も、簡単に定義することができます。
このように、BigQueryとニアリアルタイムで流れてくるPubSubのデータもSQLを使って結合することもできます。この場合BigQueryから読み込んだデータは、起動時に全部読み込んでパイプライン内に留まり続け、流れてくるデータに対してデータを差し込むことができるようになっています。

それ以外にも、StreamingとBatchの中間としてMicro Batchもできるようになっています。BigQueryやCloud Spannerに対して定期的にクエリーを実行し、先ほどのようなSQLを使ってニアリアルタイムでストリーム処理をすることもできます。
Dataflow Template の仕組み
ここまでは、Mercari Dataflow Templateでどういうことができるのかという使い方についての紹介でしたが、これからはDataflow Templateの仕組みについて紹介していきたいと思います。

Mercari Dataflow Templateの構成は、先ほど少し簡単に説明しましたが、Cloud DataflowというGoogle Cloud のデータ処理のためのマネージドサービスを使っていて、Flex Templateという再利用可能な仕組みとして動くように実装をしています。Cloud Dataflowは、Apache Beamとして提供されているプログラミングモデルを使っていて、これはバッチ処理とストリーミング処理で同じコードを使い回すためのフレームワークです。
Apache Beamを使って書いたコードは、分散処理フレームワークとして有名なApache SparkやApache Flinkのようなフレームワークで動かすこともできます。GCPであれば、Cloud Dataflowというフルマネージドのサービスで動かすことができます。SparkやFlinkだと、分散処理フレームワークを動かすためのインフラを自前で用意する必要があるのですが、Cloud Dataflowで動かすとインフラもJobをSubmitすると自動的に必要な分が立ち上がり、Jobが終われば消えてくれます。
Mercari Dataflow Templateもここで紹介したCloud Dataflowを使って処理するために、Apache Beamというプログラミングのフレームワークを使って記述されています。

またCloud DataflowのJobは、Flex Templateという仕組みを使って動かすように実装しています。Flex Templateは、処理を実行するときにプログラムを書いてSubmitするかわりに、あらかじめデータパイプラインをデプロイしておき、データ処理をしたい人が実行したい内容を指定すると、プログラムを書くことなくデータ処理を簡単に動かすことができる仕組みです。
そのため、データ処理をしたい人は設定ファイルを書いて、あらかじめデプロイされているMercari Dataflow Templateに対してこの設定ファイルを指定してJob実行を指示すると、それに基づいてCloud DataflowのJobが起動するという使い方ができるようになっています。
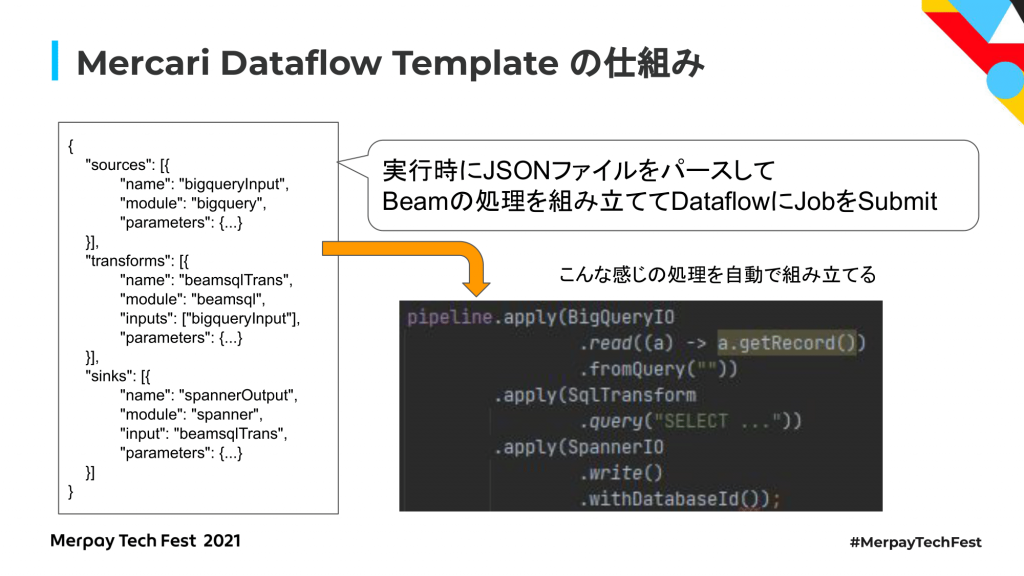
Mercari Dataflow Templateの処理内容を説明すると、先ほど説明したような設定ファイルとして、やりたいデータ処理の内容をJSON形式でまず定義するのですが、この設定ファイルを実行してくれというリクエストがあったときに設定ファイルをパースして、Beamによるデータ処理パイプラインを実行時に組み立てます。
右下にあるように、プログラマがBeam SDKを使ってプログラムを書くとこんな感じになります。パイプラインでBigQueryからクエリでデータを読んできて、それに対してSQLでこういう加工をしてくれ、その結果をSpannerに保存してくれという記述していますが、Mercari Dataflow Templateを使うと、実行時にJSONファイルからBeam SDKによるデータ処理定義をを組み立てて利用者がプログラムを書くことなくJobをSubmitすることができるようになっています。

こういった仕組みをつくるうえで解決しなければいけなかった課題として、Beam SQLなど一部の処理では入出力するデータのスキーマがどうしても必要になるため、処理に沿ってスキーマを伝搬させる仕組みをつくっています。Beamの処理を組み立てる際には必ず、データソースからスキーマを取得して、その時々のスキーマがきちんと正しく伝搬されるように処理を行っています。
スキーマを伝搬させることによって、スキーマが必要な処理も実現できますし、BigQueryのテーブルにデータを書き出したいというときも、テーブルがなければスキーマに基づいて自動でつくることもできます。また、AvroやParquetなどのスキーマが必要になる形式のファイルも書き込み先として対応できるようになります。

いろいろなデータソースからスキーマを取得するときの方法として、例えばBigQueryですと、任意のクエリ結果からスキーマを取得する必要があります。そのためにdryRunモードでクエリ結果のスキーマを取得しています。Spannerへのクエリ結果取得でも、analyzeQueryを使ってスキーマを取得しています。このようにデータソースからあらかじめスキーマが確定させてからCloud DataflowのJobをSubmitするような仕組みになっています。
どうしても機械的にスキーマが分からないようなスキーマレスなデータベースや、PubSubからシリアライズされたデータが渡ってくるような場合は、ユーザが明示的にスキーマを指定して動かすことができる仕組みになっています。

いろいろなスキーマを扱う際、データソースとシンクは、BigQuery、Cloud Spanner、Cloud Datastoreなどのサービスごとに様々なデータ形式やシリアライズ方式が使われていますが、これらのモジュール間でデータを加工処理する上でどうしてもデータのフォーマットを変換する必要が出てきます。愚直にやると、組み合わせごとにデータを変換するための処理を用意する必要がありますが、賢くやろうとすると、何らか1つの共通フォーマットを定義して、必ずそのフォーマットを経由してデータを流すような仕組みが理想的だと考えました。
当初は、その仕組みを実装しようとしていたのですが、やはりどうしてもフォーマットを変換するときに一段余計なシリアライズがはさまってしまうので、規模の小さいデータであれば問題はないのですが、大きいデータを扱おうとすると、どうしてもシリアライズ、デシリアライズのオーバーヘッドが大きく、1億件のデータで1,000行あるデータで検証すると、データフォーマットを経由しないで直接使う場合に比べて10倍以上時間がかかってしまうこともありました。弊社は大きいデータを扱う場合が多いので、泣く泣く愚直に、本当に必要となるまでデータのフォーマットを変換せずに、必要となったときに全部の組み合わせに対応できる変換処理を実装しました。
おわりに

おわりにということで、ここまでは今ある機能を紹介してきましたが、これからの開発予定、提供したいと思ってる仕組みとを紹介します。sourcesやsinksに関するテストを行う際、特に性能テストをやりたいとき、ダミーデータで性能試験をやりたいから、もともとあるテーブルにそのスキーマに沿ったデータを100万件、1,000万件自動生成して入れておきたいというときがあります。こうしたときに指定されたスキーマからダミーデータを自動生成して保存するためのダミーモジュールを提供したいと考えています。あと、今はCloud Datastoreしか対応してないのですが、Cloud Firestoreからデータを入出力できるようにしたいと考えています。
それ以外にもTransformモジュールとして、データベースからデータを読み込んで、特定のフィールドにひもづくURLに対してリクエストを送り、JSONなどの形式で返ってきた結果をパースしてファイルをダウンロードし、指定したフィールドに入れて後段に送るようなモジュールも提供したいと思っています。
また、機械学習用途に対しても応用を広げていきたいと思っています。機械学習でONNXという学習した予測モデルをいろいろなところで使うための仕組みがあって、あらかじめ学習した予測モデルをONNXファイルにしておき、データのパイプラインを動かすときにそのONNXファイルを読み込んで流れて来るデータに対して予測結果を付与して後段に送るというようなことを、プログラムを書かずに設定で簡単に動かせるようにしたいと思っています。
あと、AutoMLで予測用のエンドポイントを立ち上げて、そこに対してリクエストを送って予測結果を取得して後段に付与して送るというようなものもつくっていきたいと思っています。また、この手の処理をするときにデバッグが非常に大変になっていて、Dataflow Jobを立ち上げても、どうしても1~2分ぐらいのオーバーヘッドがあって動作確認が大変だという問題も明らかになっていますので、ローカル環境の手元のDockerで設定ファイルを立ち上げ、実際にちゃんと動くかを簡単に試せる仕組みを整理していきたいと思っています。
今回紹介したMercari Dataflow TemplateはOSSとして公開していますので、興味のある方はぜひ触っていただけるとうれしいです。プルリクエストやフィードバック、要望などを気軽にいただけると助かります。よろしくお願いします。
私からの発表は以上になります。ご清聴ありがとうございました。