Merpay Tech Fest 2021は、事業との関わりから技術への興味を深め、プロダクトやサービスを支えるエンジニアリングを知れるお祭りで、2021年7月26日(月)からの5日間、開催しました。セッションでは、事業を支える組織・技術・課題などへの試行錯誤やアプローチを紹介していきました。
この記事は、「Feature StoreとVertex Pipelinesを活用した不正防止システム」の書き起こしです。
Liu Songjie氏:皆さま、こんにちは。本日お話しするのは、Feature StoreとVertex Pipelinesを活用した不正防止システムについてです。

まず、自己紹介をさせていただきます。私は、fraud preventionチームでMLエンジニアをしています。2019年に新卒でメルペイに入社し、チャージバック検知などの不正防止のためのMLソリューションの開発に取り組んできました。最近では、Vertex AIベースのMLパイプラインの開発に携わっています。

では、本日は4部構成でお話しさせていただきます。最初に、不正検知システムの背景と、なぜ、Feature StoreとVertex Pipelinesを使う必要があるのかについてご説明します。次に、このシステムのFeature Storeについて話します。その次に、トレーニングとデプロイのパイプラインについてご紹介します。最後に、概括と今後の予定について述べたいと思います。
Background
では、まず背景について。

増大する要件に対応するため、当社のシステムには不正検知関連のソリューションが複数あります。「Alert Filtering」は、不正検知システムの品質向上を目的としたシステムです。誤検知率を低減させることで、ルールベースの不正検知の数を減らし、最終的にオペレーション負荷を低減します。チャージバックとは、クレジットカードでの購入に対するカード会社主導の返金です。「チャージバック検知」は、取引の発生時点でそれを検知します。また「不審アカウント検知」や「不審挙動検知」などもあります。詳細については、当社の技術ブログをご覧ください。
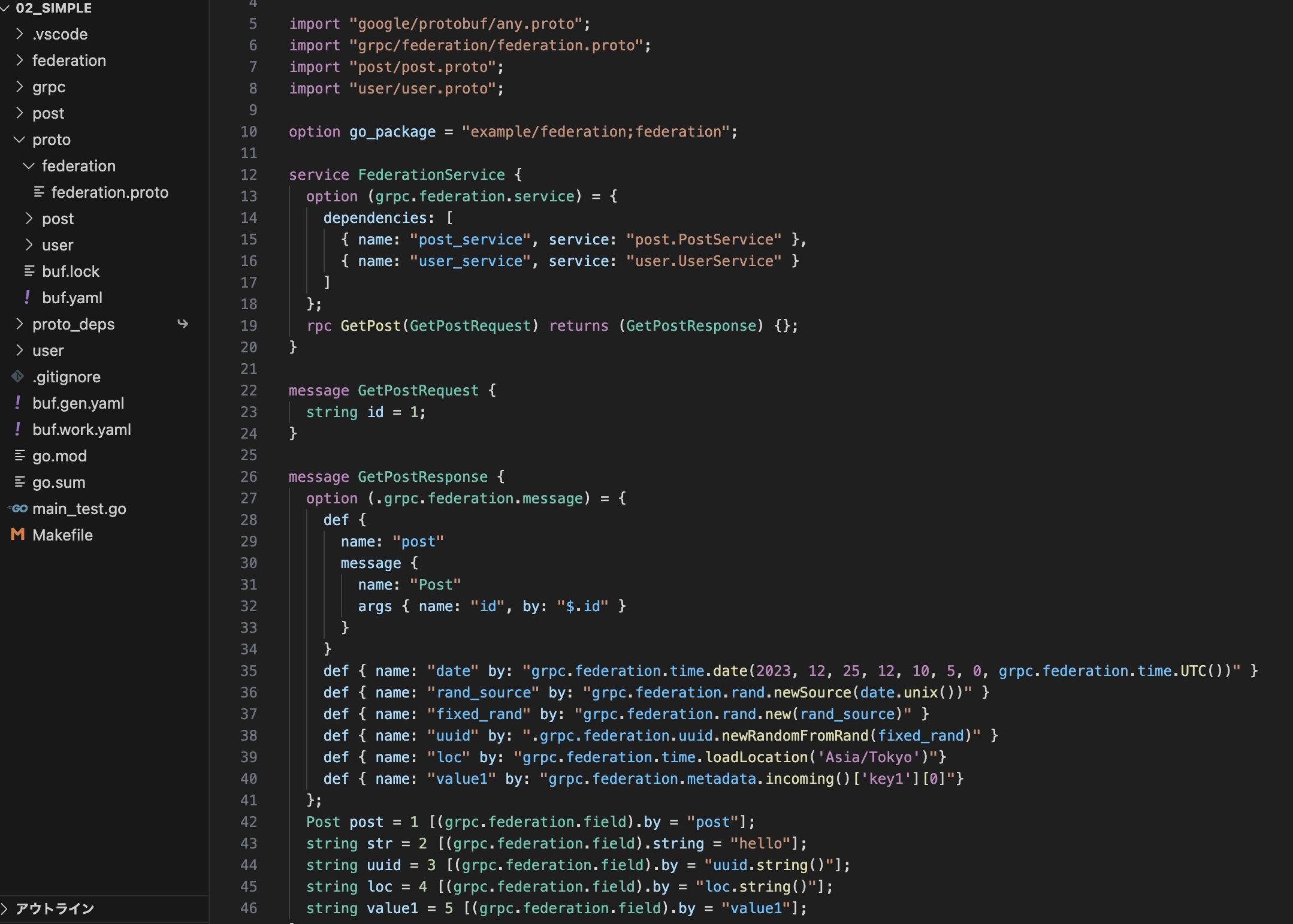
最新のアーキテクチャをご紹介する前に、当社の不正防止に関するレガシーシステムの説明をします。タスクやソリューション毎に独立したパイプラインが存在し、プラットフォーム毎に互いに異なるフレームワークを選択可能なシステムでした。また、さまざまなデータソースからデータを取得していました。例えばGCSや、BigQueryや、スプレッドシートのレポートです。各MLソリューションに、モデルのトレーニングとデプロイの独自のパイプラインがありました。また、サービングの方法も独特でした。例えばAlert Filteringは、GKE上にサービングパイプラインがあり、Spannerからオンライン特徴量を得ていました。チャージバック検知はAirflowに基づく予測パイプラインを持ち、そのうえでBigQueryからデータを得ていました。また、多重アカウント検知のようなほかのMLソリューションも、提供サービスにおいて独自の方法でインプットデータを得ていました。ソリューションはすべて独立して作動していましたが、どれもデータソースから特徴量を作成する必要がありました。MLソリューションなどは、共通の方法論でモデルをトレーニングしてデプロイしていました。

では、特徴量についてお話しします。ソリューションの数が増えてモデルが初期バージョンよりも複雑になったことで、特徴量の総次元数は1年で4倍に増えました。

これらの特徴量は、さまざまなデータソースから得ていました。BigQuery Spanner GCSスプレッドシートなどです。トレーニングと予測では、データソースが異なる場合がありました。リアルタイムで予測する必要があるモデルは、低レイテンシのためにSpannerを使用していましたが、トレーニングにはBigQueryやGCSを使っていました。Spannerのほうが、コストが高いためです。チャージバック検知やAlert Filteringのようなモデルは、ターゲット(目的変数)は異なりますが、使用する特徴量にはいくらか共通点がありました。ソリューション毎に特徴量の作成が独立しているため、一部の特徴量は異なるモデルで複数回作成される場合がありました。

この図は例ですが、これを使って特徴量間の関連付けを行ってみましょう。特徴量Xは、トレーニング時にモデルAとモデルBで使用します。レガシーシステムでは、異なるパイプラインを同時に実行すると特徴量Xが別々に複数回作成されました。モデルBで使用される特徴量XとZはBigQueryから作成されて、本番環境で予測する際には、データソースはSpannerに変更されました。Spannerは、リアルタイムのデータを低遅延で照会できるからです。

特徴量に関するコストには、2つあります。1つ目は、メンテナンスのコストです。膨大な量の特徴量を維持することは困難で、多くのエンジニアリングリソースを費やす必要があります。2つ目は、データソースから特徴量を作成するために費やすコンピューティングリソースです。この2つのコストを削減する方法を提案したいと思います。
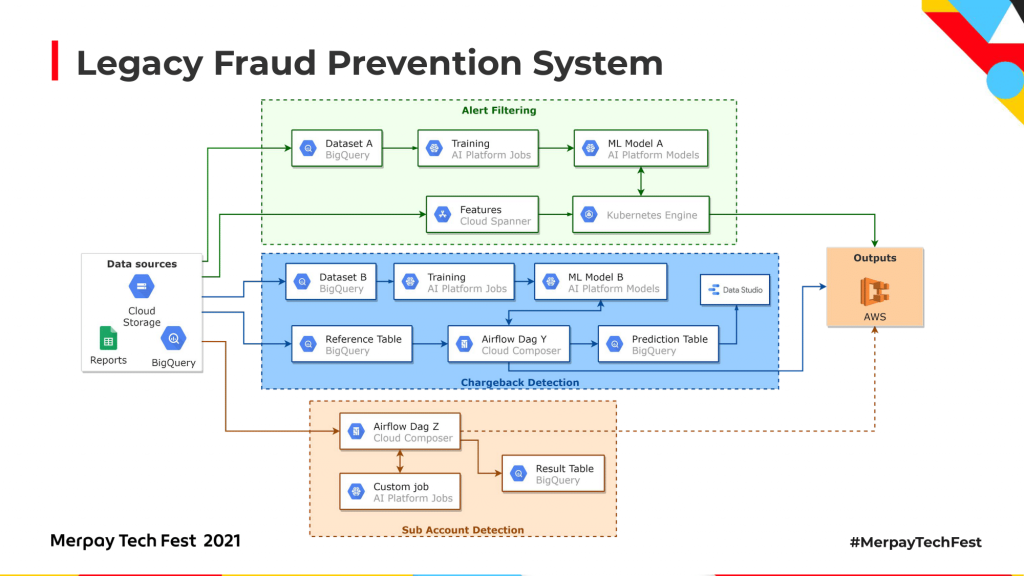
その方法とは、異なるモデル間の特徴量を減らすことです。従来の方法では、似通った特徴量や同じ特徴量を別々につくって維持していました。それでは多くのリソースが無駄になります。しかし、同じ特徴量を図のように統合すれば、コンピューティングもメンテナンスもコストが削減できます。

より良く特徴量を整理して管理する方法が分かったところで、レガシーアーキテクチャの別の問題についてお話しします。各モデルが独自のトレーニング・デプロイパイプラインを持って別々に作動していましたAlert Filteringでは、左の図のようにほかのマイクロサービスからデータを集めてトレーニング用のテーブルをBigQueryに作成していました。トレーニングは、AI Platformのジョブを通じて行われ、モデルはAI Platformのモデルにデプロイされていました。予測の間に特徴量が作成されてSpannerに保存されます。それをGKE上のパイプラインを通してデプロイされたモデルに渡し、予測結果をアウトプットとして別のシステムに送っていました。チャージバック検知では右の図のように、データセットはスプレッドシートやBigQueryなどのほかのマイクロサービスから作成され、トレーニングのためにBigQueryに保存されていました。トレーニングとデプロイは、Alert Filteringと同様にモデル内のAI Platformのジョブによって行われていました。予測の部分はAlert Filteringとは異なり、Airflowによって制御されていました。

この図のように、パイプラインの一般的なフローは次のように構成されていました。データソースからトレーニングセットを作成し、AI Platform Jobsを通してモデルをトレーニング、そしてAI Platform Modelsをデプロイしていました。本番環境ではデータソースから予測のインプットが作成されて予測結果としてデプロイされたモデルに送られました。さらに、予測結果は必要な場所に送られました。レガシーアーキテクチャでは、MLソリューションがすべて独立しているため、この表のようになります。そのためパイプライン間で基本部分を共有できます。トレーニングセットの作成とモデルのトレーニング、そしてモデルのデプロイの部分です。これらは、すべてのMLソリューションに共通です。

つまり、MLソリューションは、トレーニングとデプロイのプロセスが共通しています。トレーニングセットはBigQueryに保存され、モデルはAI Platform JobsでトレーニングされてAI Platform Modelsにデプロイされていました。各ソリューション間のおもな違いは予測プロセスです。通常、インプットとアウトプットが異なっていました。例えばBigQueryや、Spannerスプレッドシートからのインプットは、予測のアウトプットをする際、大抵、異なるマイクロサービスやシステムに接続していました。

ここまでの内容をまとめると、特徴量とアーキテクチャに関して、2つの問題が浮かび上がります。特徴量については、重複する特徴量の作成や維持に無駄なリソースを費やしていました。また、データの信頼性を向上させる必要がありました。つまり、予測に使うデータをトレーニングと同じ方法で作成したいのです。アーキテクチャにおいては、パイプラインを共有すれば、MLエンジニアが現在のモデルを改良しやすくなり、新しいモデルを効率的にデプロイできます。

では、新しいシステムアーキテクチャをご紹介します。おもに、2つの部分について説明します。Feature Storeとトレーニング・デプロイプロセスの共通のパイプラインです。

新しいアーキテクチャを図に表しました。新しいアーキテクチャでは、予測パイプラインとアウトプットのモニタリングは各ソリューションで異なりますが、トレーニング・デプロイパイプラインのFeature Storeの役割は共通です。次は、その2つについて説明します。
Feature Store

まず、Feature Storeについてです。

こちらが特徴量を作成する際の従来の方法です。各ソリューションに、データソースから特徴量を作成する独自のプロセスがあります。トレーニング時と予測時に特徴量を作成するモデルもあります。例えばモデルBです。結果的に維持する必要のある似通ったパイプラインがたくさん作成されます。

新しいFeature Storeの導入により、モデルパイプラインがデータソースを個別に処理する必要がなくなりました。
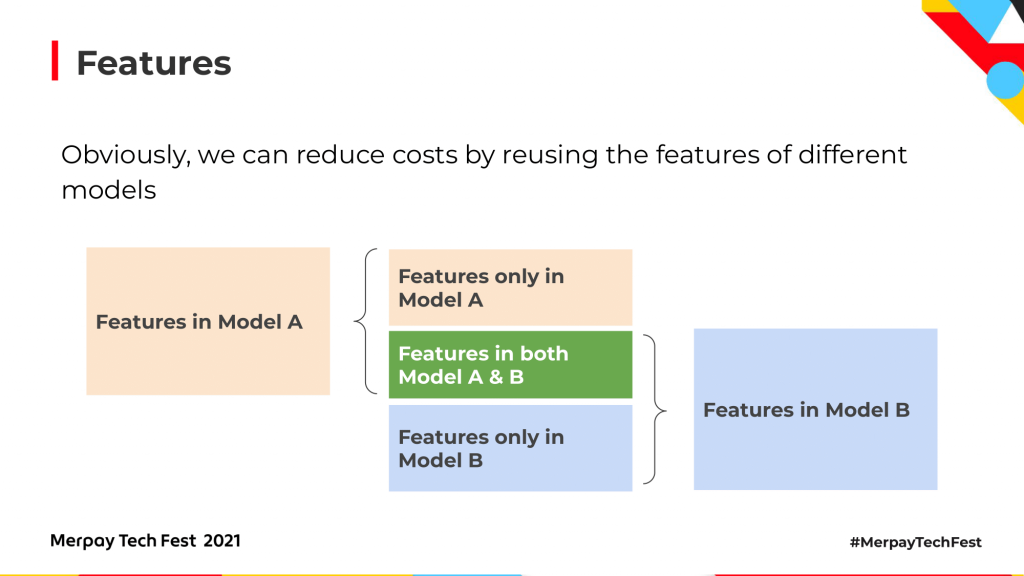
すべての特徴量はFeature Storeで一緒に作成され管理されます。トレーニング中や予測中でなくなったモデルは、Feature Storeから必要な特徴量を直接取得できるので、自らデータソースにアクセスして特徴量を作成せずに済みます。Feature Storeについて、もう少し説明します。Feature Storeは、ML専用のデータシステムで、データソースからの生データを特徴量に変換するデータパイプラインを実行します。そして、その特徴量を独自に保存して管理します。Feature Storeがトレーニング目的で特徴量にサーブするとき、データサイエンティストが特徴量を定義したあとで、Feature Storeは取り込んだデータをベクトルに変換し、モデルのトレーニングと提供と新しい情報データの分析を行います。
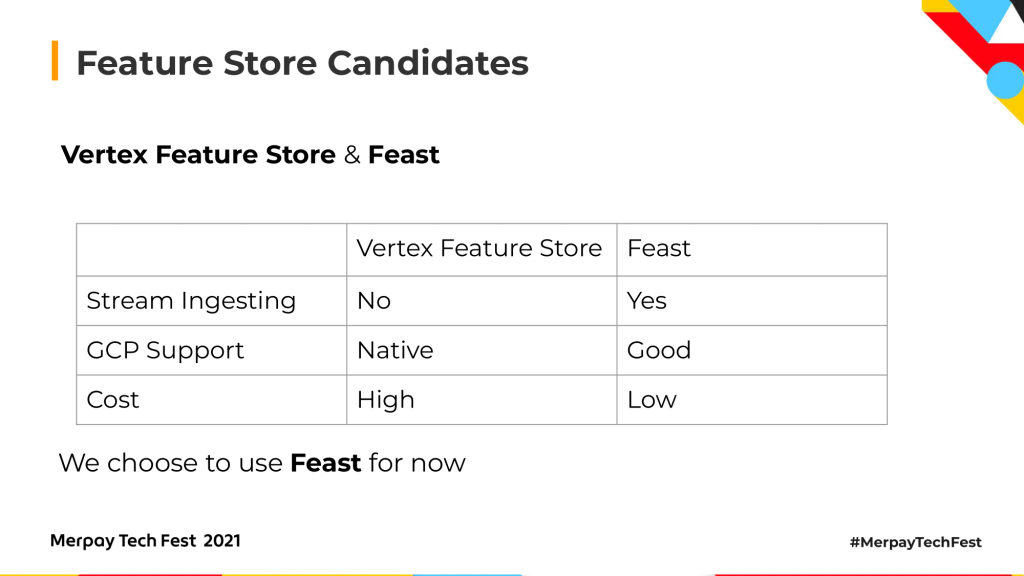
以前は、Feature Storeの候補が2つありました。1つはVertex Feature Storeで、もう1つはFeastです。この2つを、3つの点で比較してみましょう。まず、ストリーム・インジェスティング(ストリームデータの取り込み)に対応しているかどうかです。一部のソリューションは、リアルタイムの予測が必要です。予測インプットをリアルタイムで作成するには、ストリーム・インジェスティングに対応している必要があります。Vertex Feature Storeはバッチ・インジェスティングのみですが、Feastはストリーム・インジェスティングに対応しています。2つ目は、GCP対応です。当社が開発するものは基本的にGCPですので、Feature StoreもGCP対応であることが望ましいのです。Vertex AIはGoogleの最新のAIプラットフォーム製品なので、Vertex Feature StoreはGCPネイティブなアプリケーションです。FeastはGCPネイティブではありませんが、バージョン0.10以降はGCPをサポートしています。3つ目はコスト、つまり使用料です。Vertex Feature StoreのほうがFeastよりもコストがかかります。以上の点から、現在のところはFeastを使っています。

では、Feastの使い方です。始める前に、Feature Storeの初期化の準備をします。まず、Feature Viewを定義します。Feature Viewは、Feature Storeのスキーマです。Feature Viewには3つの部分があります。エンティティがFeature Viewの主キーを定義します。例えば顧客の視点では、エンティティは通常、顧客IDです。特徴量はMLモデルに使いたいものです。ルールに基づいたモデルや分析にも使えるといいですね。インプットは特徴量を保存する場所を定義します。ここでは、BigQueryをストレージとして使用しています。

Feature ViewをFeature Store用に定義したあとは、feast applyを実行できます。このコマンドによりFeastは、先ほど定義したFeature ViewによってBigQueryのテーブルを用意します。そして、Feastは定義を登録してレジストリファイルをGCSに保存します。

その後、提供されたSDKを使ってFeature Storeにアクセスします。Feastを適用する際に作成されたレジストリファイルを介してです。その簡単なコードを表示しています。

BigQueryに保存された特徴量を見てみましょう。スキーマは、このようなテーブルになっています。エンティティIDのカラムや、タイムスタンプのカラムなどFeatureViewで定義された特徴量のカラムが多数あります。タイムスタンプは、過去の特徴量を取得するのに役立ちます。

データストリームは、このようになります。.get_historical_features()を使い、オフラインストアにアクセスしてトレーニングセットを取得します。その後、モデルのトレーニングとデプロイを行います。デプロイ後は、オンラインストアにアクセスして予測用のオンライン特徴量を取得します。

ここでのもう1つのポイントは、Feastにおいては、オンラインストアとオフラインストアが同期されるので、トレーニングと予測に使うデータが同じ方法で作成されていることが確認できます。
Training-Deploying Pipeline
次は、トレーニング・デプロイのパイプラインを簡単にご紹介します。

現在のところは、Vertex Pipelinesをトレーニング・デプロイパイプラインに使用しています。これはVertex AIの一部です。Vertex AIはGoogleの最新のAIプラットフォームでMLモデルやGCPを簡単に構築してデプロイすることができます。

Vertex Pipelinesへのアクセスは、Kubeflow Pipelines SDKか、TensorFlow Extendedから可能です。弊社では、Kubeflow Pipelines SDKを使用しています。Kubeflow Pipelinesを直接使用すると、Kubernetesクラスタを自分たちで作成して維持せねばなりません。そうなると多くの権限の問題に対処する必要があり、開始と維持が困難になります。Vertex Pipelinesならば、より簡単に開始できます。

Vertex Pipelinesは、すべてのリソースをプロビジョニングして必要なアーティファクトをすべて保存し、それらを各ステップに通します。クラスタを維持し、権限の問題に対処する必要はありません。これは重要なポイントです。なぜならば、インフラよりモデルの作成や改善に時間をかけられるからです。

Vertex Pipelinesには、3つのステップがあります。まず、Feature Storeからデータを取得してVertex AIのデータセットとして保存します。次に、作成したデータセットでモデルをトレーニングし、トレーニングしたモデルをGCSに保存します。そして、トレーニングしたモデルをVertex AIにデプロイします。この3つのステップをそれぞれスライドで説明します。

データ取得を行うには、Feast SDKをインストールしたカスタムDockerコンテナでPythonスクリプトを実行します。このスクリプトはFeastのオフラインストアにアクセスし、.get_historical_features()を使用してデータフレームとして
特徴量を取得します。その後、.to_csv()を使い、データフレームをローカルに保存し、保護されたIDアセットとしてGCSにアップロードします。

Vertex AIのカスタムコンテナのトレーニングジョブによって、モデルのトレーニングはDockerコンテナ内で行われます。Dockerイメージを使うことで、必要な依存関係をすべてインストールして簡単に提供できます。また、Pythonスクリプトを使ってプロセスをカスタマイズできます。これは、カスタムコンテナのトレーニングジョブのサンプルコードです。

次に、モデルをエンドポイントにデプロイしてサービングを開始します。モデルのデプロイ後は、エンドポイントにアクセスして予測結果を取得できます。そのためのcurlを使った簡単なコードを表示しています。

これは、Vertex Pipelines上で作動するモデルのトレーニング・デプロイパイプライン全体の概要で、当社の最新の実践例です。データ取得とカスタムコンテナのトレーニングジョブと、エンドポイント作成後にモデルをデプロイする方法を実現しました。現在は、モデル評価のパイプラインを加えることに取り組んでいます。
Summary
最後の概括に入ります。

Feature Storeと共通のトレーニング予測パイプラインは、多くのメリットをもたらします。モデルの開発や改良により集中できるようになります。その一方で、特徴量やデータをより簡単に分析することができます。したがって、モデルの改良に大いに役立ちます。また、多くの重複作業が減ることで開発効率が向上します。オンボーディングと共同作業もスムーズになります。すべてのプロジェクトを1つのパイプラインでオンボーディングできるからです。メリットはたくさんありますが、このアーキテクチャはまだ試案段階です。今後も改良を重ねていきます。

これは、今後の計画の一部です。まず、共通のパイプラインを予測プロセスのほうにもつくりたいと考えています。そして、より多くの特徴量を得る方法として、分析やモデルリングのために予測結果やグラフ特徴量をFeature Storeに蓄積します。あるモデルの予測結果は、別のモデルのインプットになり得ます。また、継続的なモニタリングや品質管理もおろそかにはできません。TFDVや、Vertex monitoringでモデルや特徴量を継続的にモニタリングして、データの信頼性を向上させる予定です。また、増大する要件に応えるために、教師ありモデルを大量に生産したいと考えています。Feature Storeに新しい特徴量やラベル付けされたデータが蓄積されると、トレーニング・デプロイパイプラインが自動的に教師ありモデルをつくるようになります。
以上です。ご清聴ありがとうございました。