
Merpay Advent Calendar 2020 の2日目です。
こんにちは。Merpay Solutions Team の @sinmetal です。
この記事は Cloud Spanner (以下Spanner) に クエリ(SELECT Only) を実行するための メルペイ 社内 GUI Tool である gchammer の紹介記事です。
去年の Advent Calandar で同僚の @vvakame さんが紹介しています。 メルペイ社内ツールのお話
生まれた経緯
gchammer は 本番環境の Spanner へクエリを実行するために生まれました。
ざっくり、以下の2つの要求から誕生しています。
- 本番環境の GCP Project から人間の権限を外してセキュアにしたい
- 運用上、必要なクエリをレビューし、ログを残した状態で実行したい
最初は入力欄にクエリを書くだけのシンプルなクエリバイパスマシーンぐらいの気持ちで作り始めましたが、運用していくと徐々に機能が増えていき、ちょっとした管理画面に成長しました。
gchammer のInitial commit が 2019/01/21 なので、2年近くちびちび開発してる形になります。
メルペイのアプリケーションサーバは Google Kubernetes Engine (以下GKE) 上で動かしていますが、gchammer は Google App Engine Standard for Go (以下App Engine) 上で動いています。
App Engine を使っているのは筆者が慣れているのと、GKE 上に gchammer のためにインターネット上からのリクエストを受け取るための
External HTTP(S) Load Balancer を作るのは大げさかなと思ったからです。
gchammer という名前の由来は 本番環境の Spanner に任意のクエリを実行するというなかなか暴力的な Tool なので、使い方を誤ると破壊してしまう可能性があるという意味で hammer の名を冠しています。
一番、最初は Spanner Hammer で shammer にしたのですが、既存の単語と被ってたので、 Google Cloud Hammer で gchammer になりました。
Google Cloud Hammer というサービスが GCP からリリースされたら、絶望すると思います。
筆者は ジーシーハンマー と発音していますが、社内には ジーチャンマー と呼んでいた人もいるので、揺らぎがありそうです。
ざっくりとした機能一覧
gchammerにはざっくり3つの主要機能があります。順番に説明します。
- Query Review
- Long Run Query (and Cancel)
- Query execution plan and Query profile
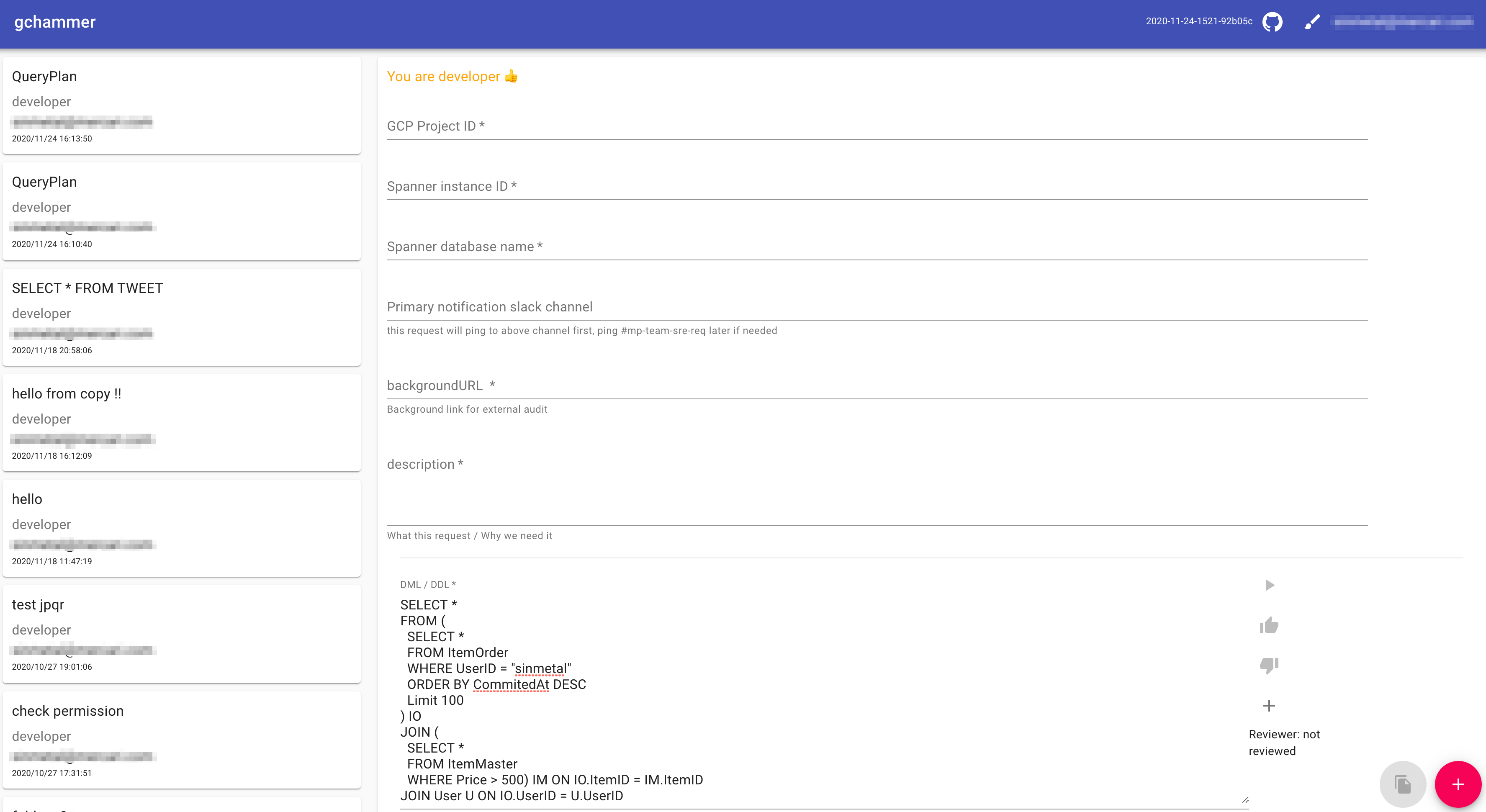
Query Review
クエリは対象の Spanner Database を管理するチームのメンバーがレビューして +1 (承認)されてはじめて実行可能となります。
チームメンバーの判定は、メルペイではチームの定義や管理をterraform経由で行っている(チームのGoogle Groupは存在しない)ため、その結果が反映されるGCP の Resource の IAM Role をチェックする形にしました。
そのため、あるユーザが Spanner が属する GCP Project の IAM Roleを持っている、もしくは対象の Spanner Resource の IAM Roleを持っている場合、これを管理しているメンバーだと判断しています。
チームメンバーはSpanner に対してクエリをgchammer抜きで、直接実行する権限を持っていません。ですが、少なくともそのプロジェクトにおける BigQuery.User の IAM Role は保有するのでオーナー確認に利用しています。
この仕組みに沿っていないデータベースも中にはあります。メルペイではアクセスが少ない Microservice の Database は 1つの Spanner Instance に同居してコストを節約しています。
同居している Spanner Database に関しては、GCP Project への IAM Role はチームメンバーは持っていないので、代わりに Database ごとに無難なカスタムロールを定義してチームに付与しています。
Long Running Query (and Cancel)
クエリは通常 Spanner への負荷を考慮して、45sec でタイムアウトするようにしています。ですが、しばしばそれよりも長くかかるクエリを実行したい場合もあります。そのために存在する機能がLong Run Queryです。
この機能では結果をCSVで出力することもできるため、データ連携の用途にも利用されます。
Long Run Queryを利用する場合はユーザのリクエストに対して同期的にクエリを実行せずに、一度 Cloud Tasks を経由して、非同期で実行しています。
予期せずCPUを使いすぎてしまった場合などに対応するため、実行しているクエリをキャンセルできる仕組みを備えています。
Query execution plan and Query profile
本番環境の Spanner への任意のクエリを実行するため、予想外の負荷をかけてしまわないか事前にチェックするための機能です。クエリのレビュー依頼を出した時に Query execution plan を、実際にクエリを実行した時は Query profile を取得する機能があります。
SpannerでもQuery plan(いわゆる実行計画)は非常に重要で、実行性能に対して大きな影響を持ちます。Solutions Teamには日々Spannerの運用の問題が持ち込まれてきますが、一番最初に行うことは何はなくともまずQuery planの確認なのです。
gchammer 自身はクリップボードにコピーするところまでで、人間が読みやすいようにQuery execution plan を表示する機能は持っていません。
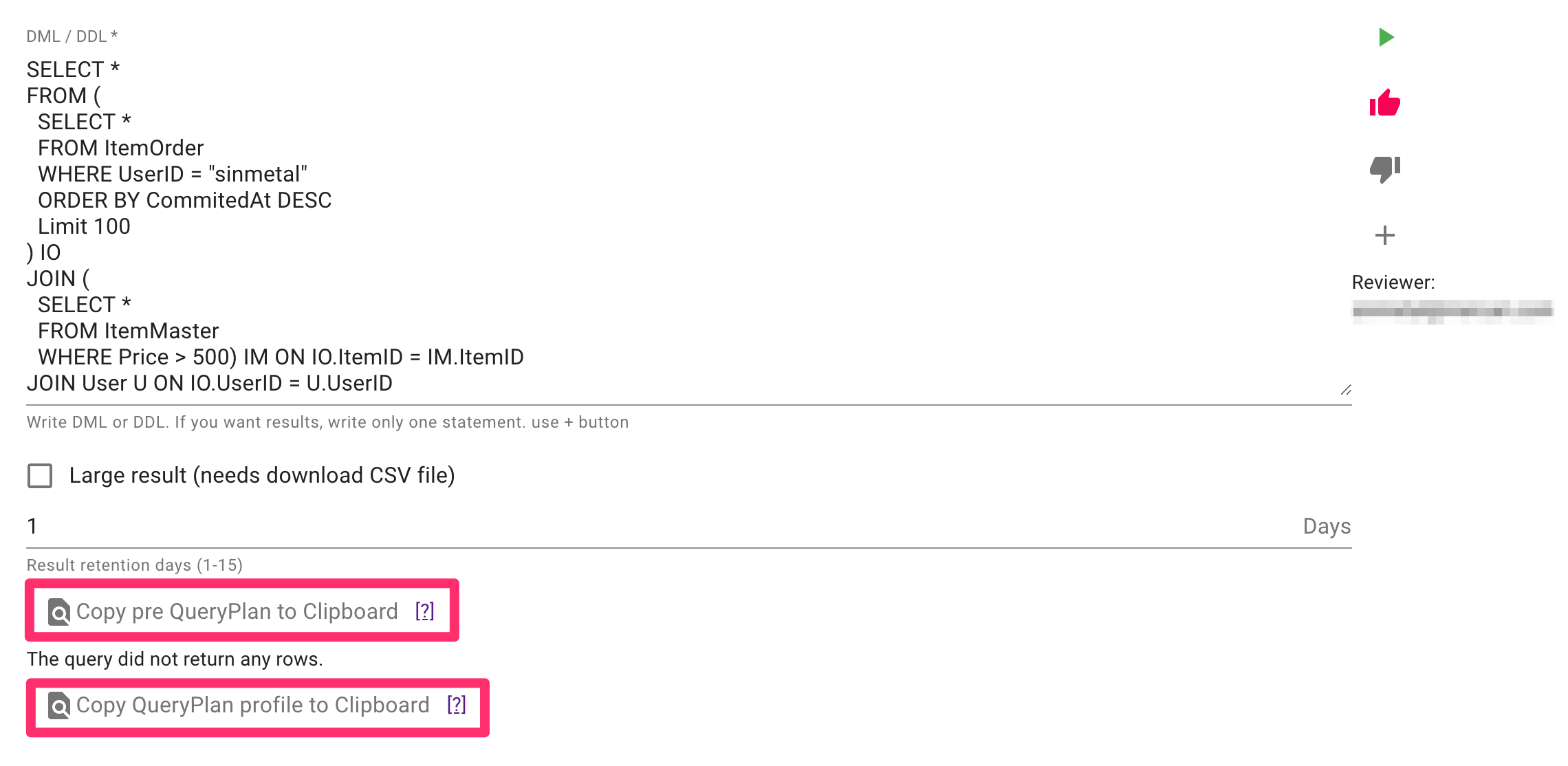
Query execution plan の閲覧は任意の Tool で確認しています。
例えば、同僚の @apstndb さんが作った github.com/apstndb/spannerplanviz/cmd/rendertree を使う場合は以下のように表示します。
Query execution plan
以下の SQL を実行する場合
SELECT *
FROM (
SELECT *
FROM ItemOrder
WHERE UserID = "sinmetal"
ORDER BY CommitedAt DESC
Limit 100
) IO
JOIN (
SELECT *
FROM ItemMaster
WHERE Price > 500) IM ON IO.ItemID = IM.ItemID
JOIN User U ON IO.UserID = U.UserID$ pbpaste | rendertree
+-----+--------------------------------------------------------------------------------------------------------+
| ID | Operator |
+-----+--------------------------------------------------------------------------------------------------------+
| *0 | Distributed Union |
| 1 | +- Local Distributed Union |
| 2 | +- Serialize Result |
| 3 | +- Cross Apply |
| *4 | +- FilterScan |
| 5 | | +- Table Scan (Table: User) |
| *13 | +- [Map] Distributed Cross Apply |
| 14 | +- Create Batch |
| 15 | | +- Compute Struct |
| 16 | | +- Global Sort Limit |
| *17 | | +- Distributed Union |
| 18 | | +- Local Sort Limit |
| *19 | | +- Distributed Cross Apply |
| 20 | | +- Create Batch |
| 21 | | | +- Local Distributed Union |
| 22 | | | +- Compute Struct |
| *23 | | | +- FilterScan |
| 24 | | | +- Index Scan (Index: IDX_ItemOrder_UserID_284C6ADB478DD301) |
| 33 | | +- [Map] Local Sort Limit |
| 34 | | +- Cross Apply |
| 35 | | +- KeyRangeAccumulator |
| 36 | | | +- Batch Scan (Batch: $v2) |
| 38 | | +- [Map] Local Distributed Union |
| *39 | | +- FilterScan |
| 40 | | +- Table Scan (Table: ItemOrder) |
| 70 | +- [Map] Cross Apply |
| 71 | +- KeyRangeAccumulator |
| 72 | | +- Batch Scan (Batch: $v5) |
| 76 | +- [Map] Local Distributed Union |
| *77 | +- FilterScan |
| 78 | +- Table Scan (Table: ItemMaster) |
+-----+--------------------------------------------------------------------------------------------------------+
Predicates(identified by ID):
0: Split Range: ($UserID_2 = 'sinmetal')
4: Seek Condition: ($UserID_2 = 'sinmetal')
13: Split Range: ($ItemID_2 = $sort_ItemID'2)
17: Split Range: ($UserID = 'sinmetal')
19: Split Range: ($ItemOrderID' = $ItemOrderID)
23: Seek Condition: ($UserID = 'sinmetal')
39: Seek Condition: ($ItemOrderID' = $batched_ItemOrderID)
77: Seek Condition: ($ItemID_2 = $batched_ItemID)
Residual Condition: ($Price > 500)Query profile
$ pbpaste | rendertree --mode=PROFILE
+-----+--------------------------------------------------------------------------------------------------------+------+-------+------------+
| ID | Operator | Rows | Exec. | Latency |
+-----+--------------------------------------------------------------------------------------------------------+------+-------+------------+
| *0 | Distributed Union | 0 | 1 | 0.05 msecs |
| 1 | +- Local Distributed Union | 0 | 1 | 0.04 msecs |
| 2 | +- Serialize Result | 0 | 1 | 0.03 msecs |
| 3 | +- Cross Apply | 0 | 1 | 0.03 msecs |
| *4 | +- FilterScan | 0 | 1 | 0.03 msecs |
| 5 | | +- Table Scan (Table: User) | 0 | 1 | 0.03 msecs |
| *13 | +- [Map] Distributed Cross Apply | | | |
| 14 | +- Create Batch | | | |
| 15 | | +- Compute Struct | | | |
| 16 | | +- Global Sort Limit | | | |
| *17 | | +- Distributed Union | | | |
| 18 | | +- Local Sort Limit | | | |
| *19 | | +- Distributed Cross Apply | | | |
| 20 | | +- Create Batch | | | |
| 21 | | | +- Local Distributed Union | | | |
| 22 | | | +- Compute Struct | | | |
| *23 | | | +- FilterScan | | | |
| 24 | | | +- Index Scan (Index: IDX_ItemOrder_UserID_284C6ADB478DD301) | | | |
| 33 | | +- [Map] Local Sort Limit | | | |
| 34 | | +- Cross Apply | | | |
| 35 | | +- KeyRangeAccumulator | | | |
| 36 | | | +- Batch Scan (Batch: $v2) | | | |
| 38 | | +- [Map] Local Distributed Union | | | |
| *39 | | +- FilterScan | | | |
| 40 | | +- Table Scan (Table: ItemOrder) | | | |
| 70 | +- [Map] Cross Apply | | | |
| 71 | +- KeyRangeAccumulator | | | |
| 72 | | +- Batch Scan (Batch: $v5) | | | |
| 76 | +- [Map] Local Distributed Union | | | |
| *77 | +- FilterScan | | | |
| 78 | +- Table Scan (Table: ItemMaster) | | | |
+-----+--------------------------------------------------------------------------------------------------------+------+-------+------------+
Predicates(identified by ID):
0: Split Range: ($UserID_2 = 'sinmetal')
4: Seek Condition: ($UserID_2 = 'sinmetal')
13: Split Range: ($ItemID_2 = $sort_ItemID'2)
17: Split Range: ($UserID = 'sinmetal')
19: Split Range: ($ItemOrderID' = $ItemOrderID)
23: Seek Condition: ($UserID = 'sinmetal')
39: Seek Condition: ($ItemOrderID' = $batched_ItemOrderID)
77: Seek Condition: ($ItemID_2 = $batched_ItemID)
Residual Condition: ($Price > 500)Query execution plan をどのように読むかは次が参考になるでしょう。
- Query execution plans
- Query execution operators
- Troubleshooting performance regressions
- Cloud Spanner Unofficial Hacks
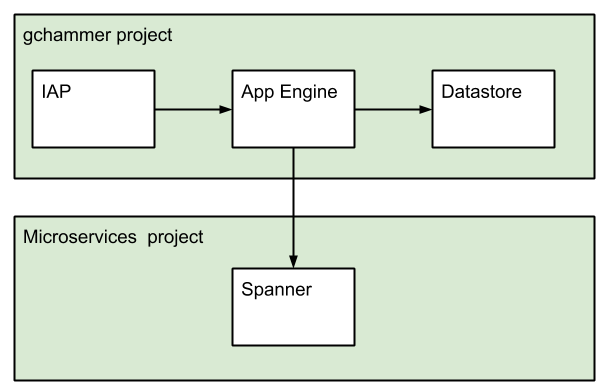
アーキテクチャ
メインのアプリケーションの Application Server は App Engine Standard for Goを利用しています。 Database は Cloud Firestore Datastore Mode (以下Datastore) を使い、認証は Identity Aware Proxy という、古の App Engine 使い御用達の構成を採用しています。
Spanner 用のツールなのにデータベースが Datastore なのは、Spanner は最低ランニングコストが高く、データ量が少ないワークロードに適さないからです。gchammer は社内ツールで人間が使うのみなので、データ量としては非常に少ないです。ツールの目的上、gchammer 自身のデータベースへのアクセスは限られた人間のみにする必要があるため、共用の Spanner Instance に同居も難しいため、シンプルでランニングコストが低い Datastore を使っています。
Web Frontend と Backend Server は GraphQL をインターフェイスに利用しやり取りしています。
Web FrontendはReactとApollo Clientを利用して実装されています。
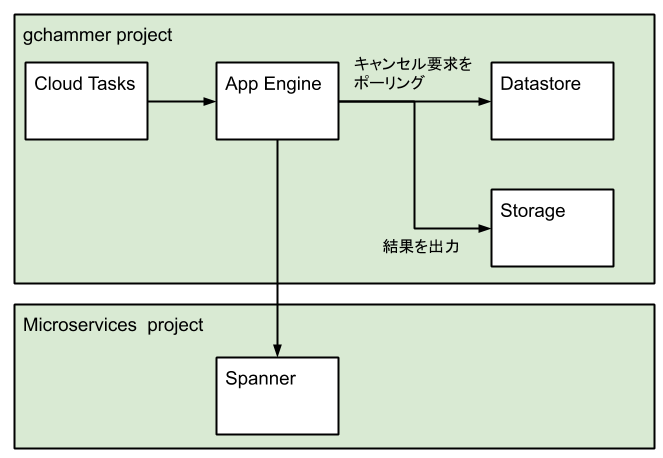
Long Run Query (and Cancel)
Long Run Query では、前述のとおりどのぐらい実行時間がかかるか分からないので Cloud Tasks を使って、非同期処理にしています。
実行結果は CSV として、Cloud Storage に保存します。
途中でクエリをキャンセルする可能性があるので、Datastore にキャンセル要求を伝える情報を保存しています。
クエリを実行しているワーカーは一定間隔ごとに Datastore をチェックし、キャンセル要求があれば、実行中のクエリを中止します。
クエリの中止は単純にクエリ実行に利用している context をキャンセルしています。
実行しているクエリが利用している Session を Delete することも考えたのですが、 cloud.google.com/go/spanner では、クエリ実行時の Session ID が簡単には取れなかったので、 context をキャンセルするようにしました。
Library として公開されたもの
gchammer そのものは社内利用のみが想定して作られているので非公開ですが、gchammer のために生み出されて外部公開している部分もあります。
それが github.com/gcpug/hake です。
ユーザが入力した任意のクエリを実行する場合、結果のスキーマは実行時にしかわからないため、事前にGoで定義したstructに当てはめることはできません。
そこで任意のクエリのレスポンスを扱うために汎用的なカラムを表現する GenericColumnValue が公式で用意されています。
GenericColumnValue を JSON や CSV に変換するのはめんどうだったので、隣に座っていた メルペイ エキスパートチームの @tenntenn さんに頼んで、 github.com/gcpug/hake が生まれました。
余談ですが、僕は hake の test がテーブルドリブンテストのサンプルとして、ちょうどいいサイズだなーと思っており、テーブルドリブンテストを書く時、いつもこれをスニペットのようにコピーして使っています。
今後追加したい機能
Low Priority Query
Spanner は 処理の優先順位として High,Low を持ちます。 gchammer のリクエストはアプリケーションに影響を与えないように Low で実行したいのですが、現状、任意のリクエストを Low Priority にする方法はないので、High Priority で実行しています。
任意のリクエストを Low で実行できるようになれば、将来的に変更したいです。
Query Parameter and Template
Query execution plan を毎度まいどレビューするのは、実は大変な作業です。ですので調査のために複数回実行する可能性があるものは事前に SQL を登録しておいて、パラメータだけ変えて実行できると便利です。
Template 登録時と実際に SQL を実行する時でスキーマに変更があり Query execution plan が変わる可能性はありますが、差分をチェックして、変化がなければ OK とするなどの工夫で実用的な機能となるでしょう。
このようなTemplate 機能を作るためには WHERE の条件に使う値を実行時に変更できるようにする必要がありますが、現状の gchammer は SQL を書くテキストエリアがあるだけで、クエリパラメータには対応していません。
クエリパラメータを入れるには操作する人間が困ったりミスをしたりしないよう、それなりの使いやすさに UI を整える必要があります。が、筆者が所属するメルペイのSolutions Team には UI が得意なメンバーがいないので、どうしようかなぁと悩んでいます。
明日の Merpay Advent Calendar 2020 は、 Backend Engineer の iwata さんより 料率計算における小数点数の扱いについて です!




