こんにちは、メルカリでCRE (Customer Reliability Engineering) に所属している @hurutoriya です。
今回メルカリ社内での勉強会の一環として、Google が提案した機械学習システムの信頼性を数値化する ML Test Score のハンズオンワークショップを開催しました。
本記事では、ML Test Score の説明、ワークショップの開催方法や簡単な考察などをお話します。
今回はWFHの影響も受け Google Meet を使ったフルリモートでの開催となりました。
ワークショップの内容として、メルカリ内で実際に運用されている機械学習システムを対象に、実際にそのシステムを開発する機械学習エンジニアが ML Test Score を計算しました。
ML Test Scoreの説明
ML Test Score の目的は、定量化しづらい機械学習システムの技術的負債を可視化し現状を把握するためのフレームワークです。
このスコアの前提として、対象の機械学習システムは
「教師ありの機械学習モデルで推論を行い、バックエンドでリアルタイムに予測結果を返すシステム」
となっています。
以下の4つのパートから構成され、各パート7つの検査項目が提案されています。
- 特徴量とデータのためのテスト
- モデル開発のためのテスト
- 機械学習システムインフラのためのテスト
- 機械学習のためのモニタリングテスト
各パートのスコアの最小値が最終的にその機械学習システムの ML Test Score となります。
つまり、4つのパートのスコアのうち最低点が機会学習システムの総合的な評価結果となるような厳しいものです。
この計算方法は、4つのパートのテストが同じく重要であることを意味します。
論文公開時、Google の数十のチームを対象にした調査では、80%以上のチームが上記の4つのテストを包括的に実施していなかったとのことです。
逆にほとんどのテストでは、少なくとも半数のチームがゼロではないスコアとなっていた模様です。
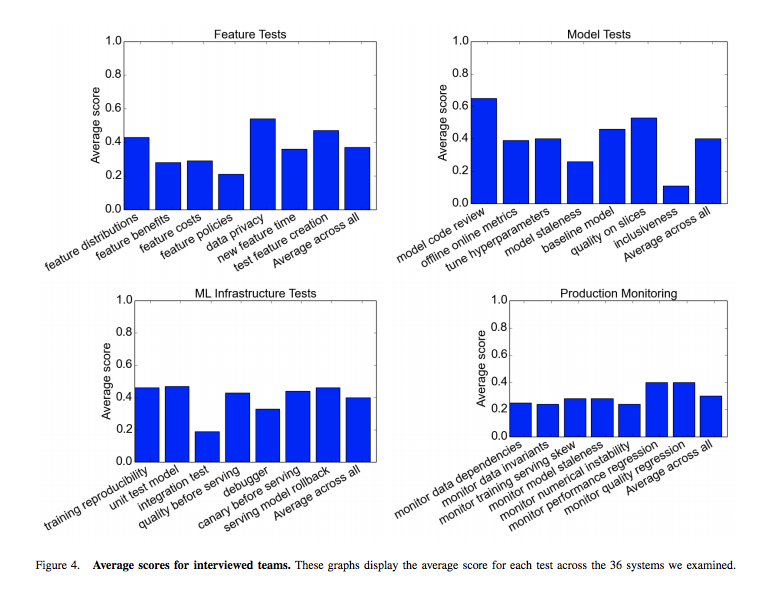
以下の Google 内の調査での平均値を見てみると、4つのパートのスコアを高得点で達成することが難しいかがわかります。

細かい説明は原著の
か
日本語で読んでみたい方は、個人的に抄訳した記事もあるのでご覧ください。
ワークショップの開催経緯
自分が所属するCREの機械学習プロジェクトで、先月から毎月1回自分たちが開発する機械学習システムの ML Test Score を見直してどの部分を改善できるか、していくべきかを議論しています。
その中で、改善点の優先順位を決めてチケット化し継続的に ML Test Score が改善する仕組みを回し始めました。
この過程で、後回しになりがちで定量化しづらい機械学習システムの技術的負債の現状の把握が個人的にとても有益だと感じました。
これは他の機械学習エンジニアも興味を持つのではと考え、メルカリに所属する機械学習エンジニア全体を対象にしたワークショップを主導し開催しました。
今回のワークショップ開催の狙いとして参加者に
- 手軽に
- 楽しく
ML Test Score を実際に計算してもらうことです。
そのため、ハンズオンのスケジュールは1時間で終わるようにして、参加の敷居を下げるために事前準備は必要とせずに各グループにチューターを割り当て、ファシリテーションをしていく形式にしました。
タイムスケジュール
| 時間 | 内容 |
|---|---|
| 00-05 | ML Test Score の紹介と効果 |
| 05-15 | 特徴量とデータのためのテスト |
| 15-25 | モデル開発のためのテスト |
| 25-35 | 機械学習システムインフラのためのテスト |
| 35-45 | 機械学習のためのモニタリングテスト |
| 45-60 | ML Test Score 計算後の感想、どこを改善したいかの議論 |
ML Test Score の紹介と効果の説明後は、事前にグループを割り振っておきGoogle Meets に参加者とチューターがアクセスし、ハンズオンを開始します。
上記のタイムスケジュールに従って、主催者が事前に用意した Google Sheets の各テスト項目に対して、マニュアルで検査を行いドキュメントにまとめられていると0.5、CIなどで自動的に検査しているなら1と穴埋めをしていきます。

ML Test Score の計算で重要なのは高得点を取得することではなく、対象とする機械学習システムの現状を理解することが重要です。
穴埋めを終えた最後の15分間では、参加者同士が現状を理解した上でどこを改善するべきかを議論を行っていきます。
ワークショップ開催後の知見
開催後は多くの機械学習サービスを運用するメルカリならではの発見がありました。
例えば、原著論文内では、音声や画像のみを扱うチームからのフィードバックとして、特徴量とデータのためのテストでは適切なテスト項目が存在しなかったという考察があります。
この課題は、画像のみを扱うメルカリの写真検索 の ML Test Score 計算でも、上記のケースに該当しました。
例えば自分の考察では、Data 2: All features are beneficial というテスト項目では、そもそも画像のみを取り扱うので、無駄な特徴量が混在する余地がありません。また、Data 6: New features can be added quickly では、画像クエリから特徴抽出を行い、ベクトルの近傍探索を行う写真検索システムでは、新たに特徴量を追加したい状況が発生することが無いのではないかと考えています。
他にも非構造化データのみを取り扱う場合は、適切ではない項目が特徴量とデータのためのテストのパートでは少なからず存在します。
論文内では、上記の問題を解決するために
- 人力によるテスト
- LIMEなどを用いた予測結果の解釈によるテスト
などのあらたなテスト項目が提案されており、改めて個々の機械学習システムのドメインに応じて検査項目自体を適合させていく必要があるなと学ぶことができました。
ワークショップ参加者の開催後のアンケートも、評判がよく定期的に開催していきたいなと思っています。
以下にワークショップ参加者の感想の一部を転載します。
- システムの問題点を整理するいいきっかけになった。
- The initiative is good, and I think hands on separate groups is a good way as well. It was well organized.
- We could see the weakness of our system
手軽に楽しく参加できるワークショップを開催するという当初の目的は達成できたのかなと思います。
機械学習システムを開発している皆様もご興味が湧いたらあなたが開発する機械学習システムの ML Test Score の計算はいかがでしょうか?
1時間もあれば ML Test Score は計算可能なのでチームビルディングの一環としてもオススメです!
メルカリの機械学習チームでは、ML Test Score を活用することで継続的な機械学習システムに関する技術的負債の減少につとめていきます。




