こんにちは。Mercari Advent Calendar 2019の24日目は、US版Mercari Machine Learning & Data Engineering Teamのhatoneがお届けします。
USのData Engineering Teamは、データサイエンティスト・マーケティング・会計チームetcの多岐にわたる社内データのパイプラインの構築・運用を行っています。Data Engineeringとは、どんな役割の仕事なのか?を、DIKWピラミッドフレームワークによる情報整理の事例や、実際にAirflowにてKubernetes Executorを用いたデータパイプラインの例をお話しながらご紹介していきたいと思います。
Data Engineeringとは?
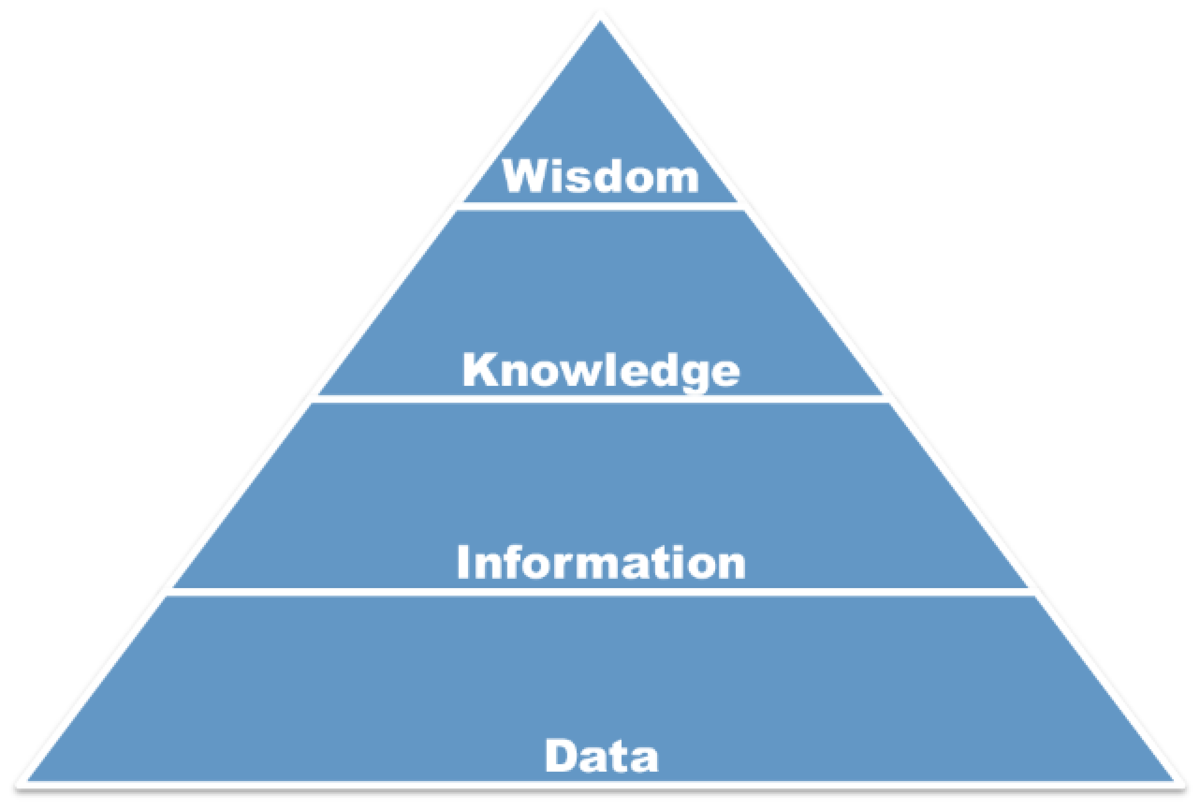
普段の業務では"ログを収集して、解析して、何かしらの判断する" このようなプロセスが繰り返されていきます。膨大なデータ量を如何に解釈して扱っていくかを模したフレームワークとして、DIKWピラミッドというモデルがあります。これは、下層から上層に向かって、Data(データ), Information(情報), Knowledge(知識), Wisdom(知恵)と積み上げられていくピラミッドのフレームワークで、この4つの頭文字からDIKW pyramidまたはDIKW hierarchyと呼ばれています。

このDIKWピラミッドにおける最下層に位置するDataは、未整理状態の生データやログのことを示しています。この例として、各オフィスの当日の最高気温をざっくりまとめた表があるとします。
| City | Temperature | Date |
|---|---|---|
| Palo Alto | 76 | Nov 24, 2019 |
| 東京 | 21.9 | 2019/11/15 |
| Palo Alto | 55 | Dec 04, 2019 |
| 東京 | 14.5 | 2019年12月05日 |
この状態では、下記のように各項目の内容が未整理状態となっています。
- Cityカラムが漢字/英語表記が混在
- Temperatureカラムで気温の表記が摂氏(℃)と華氏(°F)が混在
- Dateのカラムがタイムゾーン不明瞭でフォーマットがばらついている
このような上の表の各要素が未整理のまま収集されている状態がDataです。
こちらを、ちょっと整理してみましょう。混在していた各カラムの内容を、一定の基準で整理していきます。
DIKWピラミッドにおけるInformationは、明確に定められた基準の上で整理・処理された状態を示します。DataとInformationを同じような意味で用いられることがあるのですが、より整形されたDataがInformationと呼ばれているため、ピラミットの1つ上の層にInformationが位置しています。
| City | Temperature(℃) | Date(UTC) |
|---|---|---|
| Palo Alto | 24.4 | 2019-11-15 |
| Tokyo | 21.9 | 2019-11-15 |
| Palo Alto | 12.7 | 2019-12-05 |
| Tokyo | 14.5 | 2019-12-05 |
- Cityカラムが英語表記へ統一
- Temperatureカラムは摂氏(℃)へ統一
- Dateのカラムは、タイムゾーンをUTCに固定し、YYYY-MM-DDフォーマットへ
こうしてDataが整理されてInformationになることで、「最高気温を比較すると、UTC 11月15日の時点ではPalo Altoの方が高かったが、12月5日の時点では東京の方が高かった」といった事実を見ることができるようになります。このInformationから導き出される傾向や規則性を導出されたものが、DIKWピラミッドにおけるKnowledgeになります。そして頂点であるWisdomは、導き出されたKnowledgeに基づいて人により下される判断のことそのものを示します。
Data Engineeringの仕事は、このDataを過不足無く蓄えること、DataからInformationへの変換・蓄積する作業がメインと言えます。日々の施策や広告効果を検証するKnowledgeを導き出すためデータサイエンティストやマーケティングチームへ、会計レポートによる売上金の移動に異変がないかKnowledgeを導き出すため会計チームへ、というように「Dataをどのように整理されたInformationと化していくか?」を常に問いながらData Pipelineを構築運用しています。
AirflowでKubernetes Executorを使ったパイプイライン構築例
そんな日々のDataをInformationへ変換して蓄積していく例として、「8TB程度あるdumpログ(非正規化されている文字列込み)をBigQueryへ取り込む」や「カラム結合が駆使されて見目麗しく整っているExcelスプレッドシートの中腹部分からいい感じにレコードを取り出して、BigQueryへ格納する」など様々あります。私達のチームでは、AirflowというPythonで定義されたワークフローをスケジュールして実行するプラットフォームを、プロジェクト毎にKubernetes クラスタ上とCloud Composer上でいくつか稼働させてデータパイプラインを運用してます。そして社内で使われるLookerというBIツールが連携しているため、最終的に蓄積する場所がBigQueryになっています。
そのような背景から、”Airflow上でPythonスクリプトを使ってデータを処理し、整形済みデータをGCSへ格納、BigQueryへロードしていく”という手をよく使っています。
今回は、Airflow上でKubernetes Executorを用いたパイプラインの例をご紹介していきます。これはApache Airflow 1.10.0から導入された比較的新しいExecutorで、タスクインスタント毎に新しいポッドを作成して実行してくれるものです。
実際の例
下記が、特定のレポートをAPI経由で取得して再整形してBigQueryへロードするパイプラインの一例です。

Step A: KubernetesPodOperator
Step Aでは、Docker
Kubernetes (以下、k8s)のクラスタ上でPodを立ち上げ、起動時に任意のコマンドを実行して、その処理結果をGoogle Cloud Storage(以下、GCS)
へとアップロードしています。予め実行したいPythonスクリプトとShellスクリプトをいれたDocker Imageはbuildして、Container Registoryへ登録しておきます。
Pythonスクリプトはユースケースに応じて変わってしまうのですが、Shellスクリプトはだいたい下記のようなパターンになります。
# Docker Image上のcsv_uploader.sh
#!/bin/bash
cd /usr/local/hogel_report
# ユースケースに応じた処理スクリプトを実行する
python transfer.py ${TARGET_DATE}
# 処理結果をGCSへ転送
gsutil cp /usr/local/hogel_report/reports/* gs://GCS_DESTINATION/${TARGET_DATE}/
これをAirflow上で呼び出すためには、下記のようにDAGのOperaterを書きます。
# Step A stepA = KubernetesPodOperator( dag=dag, task_id='upload_hoge_report_to_GCS', name='upload-hoge-report-to-gcs', cmds=['/bin/sh'], arguments=['-c', 'sh /usr/local/hoge-report/csv_uploader.sh'], namespace='default', startup_timeout_seconds=3600, image_pull_policy='Always', image='gcr.io/DOCKER_IMAGE:latest', env_vars={ 'TARGET_DATE': '{{ ds_nodash }}' }, is_delete_operator_pod=True, )
image_pull_policyオプションを’Always’にしておくことで、Pod起動時に常にImageをPullしてくるようになります。また、開発検証時のみis_delete_operator_podオプションをFalseにしておくことで、Podが何らかのエラーで正しい挙動をしなかった場合に削除されずデバッグがしやすくなります。この2つを設定しておくことで、開発効率が少しだけ良くなるおすすめのオプションです。
Step B: GoogleCloudStorageToBigQueryOperator
Step Bでは、GCSに上がった整形済みデータを、BigQueryへとロードしていきます。GoogleCloudStorageToBigQueryOperatorを下記のように指定しています。
# Step B stepB = GoogleCloudStorageToBigQueryOperator( dag=dag, task_id='upload_hoge_to_BQ', bucket=bucket_name, destination_project_dataset_table='%s:%s.%s' % (project_id, dataset, 'hogel_report_{{(execution_date.strftime("%Y%m"))}}'), source_objects=['{{ds_nodash}}/hoge_report_*'], source_format='CSV', skip_leading_rows=1, max_bad_records=3, write_disposition='WRITE_TRUNCATE', project_id=project_id, bigquery_conn_id=gcp_connection_id, google_cloud_storage_conn_id=gcp_connection_id, schema_object='hoge_report.json', trigger_rule=TriggerRule.ALL_DONE, )
今回の例ではBigQuery上で年月毎のテーブルを格納するため ‘hogelreport{{(execution_date.strftime("%Y%m"))}}’ をようにAirflowのMacroを記述しています。
Step C: SlackAPIPostOperator
Step Cは、他の処理が何らかのエラーが発生した場合にSlackチャンネルへアラートをあげるためのものです。

# Step C stepC = SlackAPIPostOperator( dag=dag, task_id='post_alerting_message_to_slack', token=token, channel=channel, username=username, text=''' Task Failed. *Task*: {task} *Dag*: {dag} *Execution Time*: {exec_date} *Log Url*: {log_url} '''.format( task='{{task}}', dag='{{dag}}', exec_date='{{ ts }}', log_url=log_url_base+'execution_date={{ts}}&task_id={{task}}&dag_id={{dag}}' ), trigger_rule=TriggerRule.ONE_FAILED)
Step D: BigQueryOperator
StepDは、StepBの月毎を全て結合し、任意のカラムのみにしたものを出力する例です。
# StepD
stepD = BigQueryOperator(
dag=dag,
task_id='union_hoge',
bigquery_conn_id=gcp_connection_id,
sql='SELECT c1, c2, c4, c7 FROM PROJECT_ID.DATASET_ID.hoge_report_*',
destination_dataset_table="%s:%s.%s" % (project_id, other_dataset', 'hoge_report’),
allow_large_results=True,
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
trigger_rule=TriggerRule.ALL_DONE,
)
このような流れで、特定のレポートをAPI経由で取得して再整形してBigQueryへロードするDataをInformation化する作業を実現しています。
これまでAirflow 1.9.x系にてPythonスクリプトを実行したい場合は、Python Operatorを使う手がありました。しかし、この場合は独自のライブラリを利用したい場合にはAirflow本体の環境へライブラリを追加する必要が発生していました。そして、あるデータパイプイラインにて特定のバージョンのライブラリを使いたいが、別データパイプラインでは同ライブラリの別バージョンを利用したいようなケースの場合ではバッティングしてしまうという問題がありました。Airflow環境へインストールされたライブラリに依存せずにPythonスクリプトを実行させたい場合、Dask(並列処理ライブラリ)をマシンパワーを生かして実行する際には、Kubernetes Executorを用いることにより、KubernetesPodOperatorで記述したタスク単位で割り当てるリソースを細やかに制御でき、Docker Imageベースで実行するため他環境のAirflowへの移行も容易で、有用な点が非常に多いと感じています。
さいごに
時折、想像の範囲を軽く超えたデータパイプライン開発のチケットが切られることがあります。
Data Engineeringは、ビッグデータならぬビックリデータを如何に実装していくか?というパズル問題のような思考から、単純に大きなサイズのデータを扱うこと、Airflowクラスタのメンテナンスなど、データをいい感じに扱うための技術スキル総合格闘技感が楽しいところです。
今後も、処理できるデータの幅と芸風を広げていくために、精進してまいります。
最後まで読んでいただき、ありがとうございました!! Happy Holiday : )
明日(25日目)の担当は @suguru です。引き続き、どうぞお楽しみください!



