Merpay Advent Calendar 2019 の19日目は、Backendエンジニアチームの @toshinao がお送りします。
新しくマイクロサービスを立ち上げる機会があり、クリーンアーキテクチャをベースにしました。クリーンアーキテクチャはバックエンド・フロントエンド・アプリなど様々な場所で採用されています。ただ、確固たる方法というのは無く、みな試行錯誤しているのでは無いでしょうか。この記事では、クリーンアーキテクチャを取り入れる上で考えたことを紹介したいと思います。
マイクロサービスを作ったことがない人や、今までいくつか作ってきたけどより良い設計について考えている人の助けになれば幸いです。
はじめに
メルペイのバックエンドは主にGoとGoogle Cloud Platform(GCP)で開発を行っていますが、各マイクロサービスをどう実装していくかは概ね各チームに委ねられています。今回、設計するにあたって下記の本を参考にしました。
- エンタープライズアプリケーションアーキテクチャパターン (以降PoEAAと表記)
- エリック・エヴァンスのドメイン駆動設計 (以降Evans本と表記)
- Clean Architecture 達人に学ぶソフトウェアの構造と設計 (以降Clean Architecture本と表記)
主に考えたことは下記のような事になります。
- レイヤーごとの責務をはっきりとさせる
- レイヤー間のルールを厳格にする
- 様々な入出力を統一的に扱えるようにする
- 永続化コードも厳格なルールを適用する
割とかっちりとした設計となっていてGoっぽさは少ないかもしれません。
レイヤーごとの責務をはっきりとさせる
過去にマイクロサービスを独自のレイヤー構成とレイヤー名で作成したところ、初見の人には分かりにくく、学習コストが高いものとなってしまいました。
そのため、今回は普及しているレイヤー構成にすることで各レイヤーの責務を把握しやすくし、ぱっと見ただけでどこに何があるかイメージできるように心がけました。
また、自分自身がベース開発を行っていく上でレイヤーの責務が明確だと、どこに何を書くべきかの根拠付けがはっきりするので良かったと感じました。

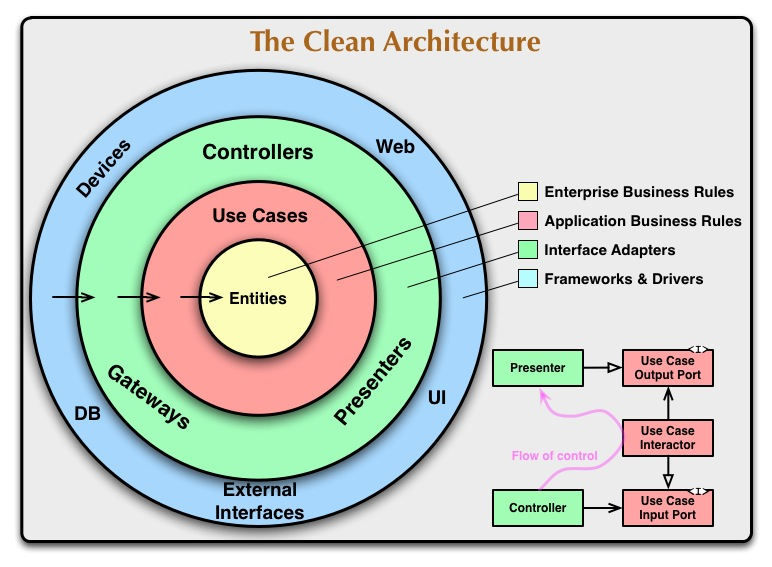
レイヤーは上記の画像と同じ構成にしています。(カッコ内はディレクトリ名です。)
- 1 Frameworks & Drivers (drivers)
- 2 Interface Adapters (adapters)
- 3 Application Business Rules (usecases)
- 4 Enterprise Business Rules (domain)
1 Frameworks & Drivers
Cloud Spanner 、Cloud Pub/Subやgrcp.Dialなどの薄いラッパーを記述します。
ライブラリ側でインターフェースが存在すれば、それをそのまま使う場合もあり、このレイヤーをスキップする場合もありました。
2 Interface Adapters
入力のバリデーションやリトライ制御など業務ロジックが介在しない処理を記述します。
また、Spannerのクエリや連携マイクロサービスへのリクエストもここに記述します。
3 Application Business Rules
メインの業務ロジックを書きます。Spannerのトランザクション管理はここで行っています。
注入されているInterface Adaptersレイヤーのインスタンスを使って外部とのやり取りをします。
4 Enterprise Business Rules
Spannerのテーブル構成と独立させた構造体を定義します。
ここに記述するのは、ドメインオブジェクトの操作や判定処理となります。
レイヤー間のルールを厳格にする
決めたルールは下記となります。
- ルール1. レイヤーをまたがる構造体(メソッドの引数や戻り値)は内側のレイヤーに配置する
- 構造体の責務が曖昧になるため、レイヤーを超えた構造体の引渡しはしない
- 構造体の変換処理でボイラープレートは多くなるが頑張る
- ルール2. パッケージも依存関係の逆転となるようにする
- 外側のレイヤーを呼び出すには自身のレイヤーにインターフェースを配置して、それを呼び出す
- ドメインオブジェクトを除いて内側のレイヤーの呼び出し時もinterfaceを使用する
- ルール3. 生成メソッドは構造体を返す
ルール1.レイヤーをまたがる構造体(メソッドの引数や戻り値)は内側のレイヤーに配置する
Clean Architecture本では「ソースコードの依存性は、内側(上位レベルの方針)だけに向かっていなければいけない。」としか書かれていません。 そのため、レイヤーを飛び越えたアクセスがOKかNGかは、チームのルールになります。
クリーンアーキテクチャのサンプルを探してみると、コントローラーがユースケースを呼び出してドメインオブジェクトを返し、プレゼンターで外部のデータ形式に変換するようなパターンも見受けられます。 このサンプルパターンを許可した場合、ドメインオブジェクトを外部に返す値として使えるので、ドメインオブジェクトが至るところに登場してしまいます。私自身、MVCで開発していた時、モデルにView用の関数を足して責務が曖昧になってしまったという経験がありました。
今回は、Clean Architecture本に習い制御の流れに反して境界を超えるようにし、境界を超えるやり取りの引数と戻り値は内側のレイヤーに定義しました。
デメリットとして、レイヤーを移るごとに構造体の詰替が発生することになりました。メルペイではマイクロサービス間はProtocol BuffersとgRPCを使用しています。adaptersレイヤーの入出力としてProtocol Buffersのツールで生成された構造体を使います。これが便利なため、そのままusecasesレイヤーに渡そうとも考えたのですが、レイヤーを厳格にするため別の構造体を定義することにしました。残念ながら、似たような構造体の詰め替えが発生しています。
デメリットもありますが、レイヤーをきっちり分けたことによるメリットを享受している場所があります。それは、別マイクロサービスのPub/Subのイベントをサブスクライブしている箇所です。そのメッセージは様々なマイクロサービスが受信していて多くのフィールドが存在します。しかし、自マイクロサービスで必要なのは数項目だけなので、関心のある項目だけ定義した構造体をusecasesレイヤーに渡すことが出来ています。


ルール2. パッケージも依存関係の逆転となるようにする
感覚的にパッケージの依存関係の逆転を意識するのは難しく、DIできるようになっていてもパッケージの依存関係が逆転していないことはよくあると感じています。私の経験ですが、ScalaでMinimal Cake Patternを使ったプロジェクトで開発していた時、実装とインターフェースを同じパッケージに記述していたため、パッケージを使い回すときに依存関係が複雑になり、コンパイル時間の増加と依存関係の複雑さに起因するライブラリのバージョンアップが厳しいという問題に直面しました。(他に問題があった可能性もありますが…)
Goではそこまで意識する必要は無いかもしれないですが、今回はパッケージの依存関係の逆転をきちんとしてみようと思いました。とはいえ、インターフェースを毎回、別パッケージに手で記述するのは面倒だったので、ifacemakerを使ってインターフェースを生成しました。ただ、ifacemakerは同じパッケージ内に置くことが前提なので、別パッケージに置くと一部問題がありました。
問題となったケースは、もとのファイルではインポート対象だったが、インターフェースになるとインポートが不要になるケースでした。つまり、セルフインポートになってしまう場合です。解決はセルフインポートになった箇所を削除するだけで良かったので、AST解析して削除するツールを作りました。レイヤールールで内側に構造体を置くことにしたため、引数に出てくる型は概ね最初から別パッケージとなっていたこともあり、プログラムは複雑なものになりませんでした。
また、ASTの解析のついでにインターフェース定義の上に go:generate mockgen コメントを挿入して同時にモックを生成するようにしました。
ルール3. 生成メソッドは構造体を返す
GoのDDDサンプルだと生成系(Newで始まるようなメソッド)もインターフェースに入っている例を見かけます。その場合、そのメソッドは自身のインターフェースを返す必要があります。それを利用して引数でプライベートなfake構造体を返すか、本物を返すかを選択できるようにするパターンもあります。
「Accept interfaces, Return structs」は「インターフェースを受け入れ、構造体を返せ」ということですが、公式wikiのCodeReviewCommentsにも構造体を定義してあるパッケージにインターフェースを定義するべきでは無く、利用する側でインターフェースを定義したほうが良いと書かれています。考え方的にはセパレートインターフェース(PoEAA)に近いものだと思います。具象型はインターフェースを知らなくてもいいということが共通しています。
また、Goだとnil Pointer Receiverとインターフェースの相性があまり良くないとも感じてます。
あまりGoらしさにこだわっているわけでは無いのですが、今回、生成メソッドは構造体を返すようにしました。
様々な入出力を統一的に扱えるようにする
設計したマイクロサービスの主な入出力は下記となります。
- 連携マイクロサービス
- Google Cloud Spanner
- Google Cloud Pub/Sub
- Google Cloud Storage
- 暗号化ツール
- 環境変数
業務ロジックの中で上記の入出力を直接記述するとテストがしにくくなります。例えばPub/Subのサブスクライバーにリトライハンドルとビジネスロジックを書いてしまうと、テストを書くのが大変になります。
各入出力に対してレイヤーを意識することで統一的に扱いたいと考えました。Pub/Subからの処理もadaptersレイヤーとusecasesレイヤーに分ける、別マイクロサービスのリクエストも同様にするというルールを作りました。


永続化コードも厳格なルールを適用する
最近だと永続化コードはリポジトリパターンを適用することが多いように思います。今回も最初リポジトリパターンを使った処理を検討しましたが、永続化メカニズムの隠蔽を行うことにメリットを感じなかったこと、adaptersレイヤーの戻り値としてドメインオブジェクトを返すことに対する違和感から、今回はリポジトリパターンを採用しませんでした。
最終的にはadaptersレイヤーはテーブルゲートウェイパターンで戻り値を返し、usescasesレイヤーで変換してドメインオブジェクトにする処理フローに決めました。
永続化メカニズムの隠蔽を諦めた理由
PoEAA、Evans本ともにリポジトリパターンは永続化メカニズムを隠蔽することに比重を置いた説明となっています。下記、PoEAAのシーケンス図では、
SQLを仕様パターンで隠蔽し、ストラテジーパターンで永続化メカニズムを隠蔽(切り替え可能に)しています。普及しているリポジトリパターンでは仕様パターンを使うことは少ないかと思います。PoEAAでもメソッドとして表現している方法が直後に出てきます。(下記の図のCriteriaが仕様パターンです。)

過去に携わったプロジェクトで永続化メカニズムをCloud DataStoreからCloud Bigtableに置き換えることがありました。永続化メカニズムの特性を生かすと、ドメインオブジェクトを変えたほうが良いという結論になり、ドメインオブジェクトは変更になりました。その経験から、どんな永続化メカニズムにも対応できるドメインオブジェクトを設計するのは効率的ではないと考えました。
また、SpannerのトランザクションはRead Only TransactionとRead Write Transactionがあります。トランザクションは永続化メカニズムごとにバリエーションがあり、統一化するのは難しいと考えています。
ルールを適用するためにやったこと
adaptersレイヤー
永続化コード周りのライブラリとして、Spannerのデータベースから構造体とメソッドを自動生成してくれるyoを使用しました。
yoによって生成されたファイルを直接編集するとスキーマの変更時に手動で編集しなければいけないので、生成された構造体をラップした構造体を定義しています。
yoのデフォルトだとActiveRecordパターンのように構造体とメソッドが一緒になります。
ルールに従うには、Spannerクライアントはdriversレイヤーにあるので、usecasesレイヤーからアクセスするためにはadaptersレイヤーにアクセスメソッド(の構造体)を配置して、テーブルの構造体はusecasesレイヤーに配置する必要があります。
yoはテーブルの構造体とアクセスメソッド(の構造体)を自動生成する時にテンプレートを指定できます。そのテンプレートはカスタマイズ可能になっているので、前述のルールで配置できるようにカスタマイズしました。
usecasesレイヤー
下記の理由から、ドメインオブジェクトとテーブルの構造体を分けました。
- 組み込みバリューパターン(PoEAA)を使用したい
- Spanner固有の情報(ShardIDなど)はドメインオブジェクトに保持したくない
usecasesレイヤーの命名は最初データマッパーにしたのですが、改めてPoEAAを読むとデータマッパーパターンは
- テーブルとオブジェクトのマッピングを行う
- オブジェクトをオンメモリに持つ時に一意IDをキーとしてmapに保持する
ようなパターンであると書かれています。

データマッパーのマップとはどっちの意味のマップなのか分からなかったので、今回はデータマッパーという言葉を使うのをやめました。また、Clean Architecture本ではテーブルとデータ構造を紐付けるものとしてデータマッパーが登場します。(オブジェクトと紐付けているのではなく構造体と紐付けているということを強調しています。)
今回はテーブルから構造体を生成して、生成された構造体をドメインオブジェクトに変換するようにしたので、PoEAAともClean Architecture本とも異なると考えました。
以上のことを踏まえ、下記のようにしました。
- 永続化メカニズムから取得はシンプルなテーブルゲートウェイパターン(PoEAA)
- usecaesレイヤーに配置したyoから生成される構造体をDTOと命名
- DTOからドメインオブジェクトに変換するユースケースをtranslatorと命名
最終的なシーケンス図は下記となりました。

実際はもう少し複雑です。translatorでDTOの暗号化されているフィールドを復号化する処理を行っています。
この時、adaptersレイヤーの暗号化ツールクライアントに復号化を依頼し、復号化したものを組み込みバリューとして表現しています。
最後に
今後は、割と重厚なクリーンアーキテクチャとなりボイラープレートが多いので自動生成できるところは自動生成したいというのと、一方で、業務ロジック部分の整理が弱い箇所があるのでドメインレイヤーなどを定義して整理したいと考えています。
明日のMerpay Advent Calendar 執筆担当は、AML, Backendエンジニアチーム の @agro1986 さんです。引き続きお楽しみください。




