この記事は、 Mercari Bold Challenge Month の18日目の記事です。
こんにちは。メルカリで Product Manager として働いている津田と申します。私は社内で「会計システム」と呼ばれる、会社が運営するサービスに付随して発生した債権債務の増減を記録・集計するシステムを開発するチームで働いています。
はじめに
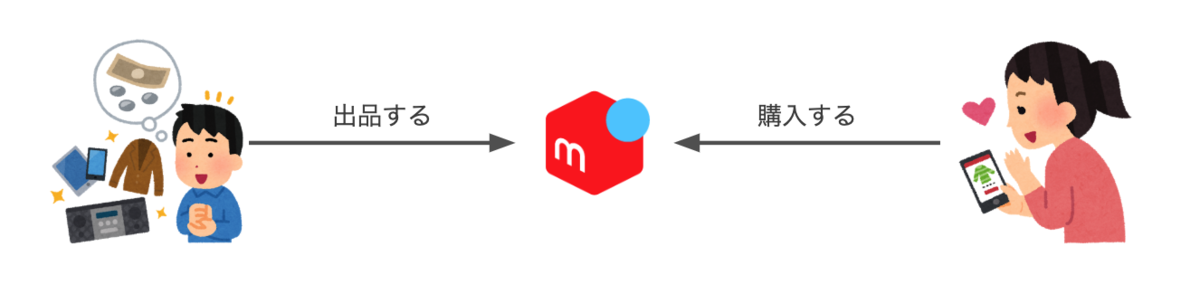
メルカリでは、お客さまの行動に応じて日々さまざまなお金の流れが発生しています。たとえばメルカリで商品が出品され購入された(取引が行われた)場合を考えてみます。

この取引は、会社から見るとそれぞれの相手先に対する債権債務関係の変化と捉えることができます。メルカリにとっては、購入したお客さまに対する債権(= 商品代金)と出品したお客さまに対する債務(= 売上金)が発生します。このとき、商品代金の一定割合(通常は 10%)が販売手数料としてメルカリの売上となります。出品側のお客さまに売上金が付与される前に、販売手数料が控除されます。

債権債務関係が変化するタイミングやその内容はサービスの利用規約や取引先との契約関係、会計基準など様々なルールを基に決定されます。また、実際には多様な配送手段や決済手段、キャンセルや補償等のイレギュラーな処理が絡むことで複雑なお金の流れが発生します。
本記事では、このようなメルカリのサービスに付随して増減した債権債務を集計し会計処理に必要な情報を出力する「会計システム」と呼ばれる社内向けのシステムと、その Microservices 化に伴う変化についてご紹介します。
会計とは
そもそも「会計」とは何でしょうか。
一口に会計といっても世の中には「財務会計」「管理会計」「税務会計」などと呼ばれる様々な種類の「会計」があります。
それらの共通点は「会計主体」と呼ばれる会社や個人の活動から生じた債権債務関係の変動を記録し、利害関係者に報告することです。財務会計であれば、「利害関係者」は債権者や投資家を指します。
財務会計に使われる主要な技術が「複式簿記」と呼ばれる記録体系です。
複式簿記と会計システムの役割
複式簿記は債権債務関係の変動の二面性を借方と貸方に分けて記録する体系で、13世紀のイタリアで発展しました。
複式簿記では、1つのイベントに対して常に「借方」と「貸方」が発生します。例えばメルカリで A さんが 2,000 円の商品を購入し、出品者の B さんがらくらくメルカリ便のネコポス(消費税込みで全国一律195円!)で発送したケースでの複式簿記の仕訳を考えてみます。メルカリ便では、取引の完了時に売上金から配送料が差し引かれます。
1. 取引完了に伴う売上金付与 借方: 購入者(A さん)に対する債権 2,000 貸方: 出品者(B さん)に対する債務 2,000 2. メルカリの販売手数料 10 % を控除 借方: 出品者(B さん)に対する債務 200 貸方: メルカリの売上収益 200 3. らくらくメルカリ便の配送料を控除 借方: 出品者(B さん)に対する債務 195 貸方: 配送会社に対する債務 195
このような仕訳を用いて、現実の取引関係や債権債務の構造を数的に模写していきます。現実のイベントを複式簿記の仕訳として表現するには、「誰から誰へいくらのお金を動かした」ことに着目するとより単純化することが可能です。
これら複式簿記の仕訳を集積したものが財務諸表となります。実際の会計処理は経理チームがこれらの仕訳を勘定奉行や弥生会計のような財務会計システムに入力することで行われます。これらの会計処理を行うためのデータを出力するのが私たちが開発している「会計システム」の役割です。

会計システムがやらないこと
いわゆる freee や MoneyForward, 弥生会計などの財務会計ソフトウェアではありません。従って、仕訳を入力したり財務諸表を集計、出力したり税務申告の元データを生成したりする機能はありません。
それら財務会計ソフトウェアに入力するためのデータを作るのが本記事でいう「会計システム」の役割です。
イベントと会計処理の関係
会計システムには、メルカリやメルペイのサービスで発生したお客さまや取引先各社との間の債権債務関係の増減を正しく報告することが求められます。
報告のためのデータを集計するにあたっては、まず前述のように「会計処理すべき事業上のイベント」を定義し、それに複式簿記の仕訳を当てはめる必要があります。前述の例では、「取引が完了した」ときに「A さんに対する債権」「B さんに対する債務」「メルカリの販売手数料」「B さんからもらう配送料」を記録しておけば十分です。
会計処理を行うべきタイミングやその内容は、サービスの利用規約や取引先との契約関係により異なります。これらを定義するには、経理チームや会計監査人と議論する必要があります。メルカリの場合は多彩な決済手段や配送手段を提供しており、それぞれについて会計処理の定義やデータの取得方法を考えなければなりません。
また、注意すべき点として、内部的・外部的な整合性を保つための手段を用意しておく必要があります。例えば決済代行会社に対する債権であれば、その会社から自分達の持っている決済依頼のデータと突合可能な入金明細を取得するという方法が考えられます。これは、イベントと会計処理の関係が網羅的に定義されていることを証明するための手段の一つです。
最初の会計システム
メルカリでは、サービス開始当初から自社で会計システムを開発していました。過去のチケットを見返すと、最初期はイベントと会計処理の定義を基に創業者の一人が SQL で集計していたようです。
手作業でのデータ抽出から徐々に自動化や運用改善を進め、下記のようなシステムに辿りつきました。

実際に会計処理が行われるまでの流れは下記のとおりです。
- お客さまがメルカリを利用する
- メルカリの本番 DB にデータが記録される
- 会計に必要な特定のテーブルを本番 DB から会計 DB に Replicate する
- 会計 DB からお客さまの氏名、住所、電話番号などの個人情報(以下、お客さま個人情報)を削除した状態のファイルを日次で dump し、圧縮して AWS S3 にアップロードする
- 他社からの請求明細を S3 にアップロードする(取引先ごとに AWS アカウントを分けています)
- S3 上の各ファイルを AWS Redshift に取り込む
- AWS EC2 から会計レポートを出力するプログラムを実行し、 Redshift に対してクエリが実行される
- クエリの実行結果を元に会計レポートを作成し、 Google スプレッドシートへ反映する
- 会計レポートを Slack の特定チャンネルに投稿する
- 経理が会計レポートを基に ERP 等へ仕訳を入力し、財務諸表を入手する
お客さま個人情報の削除
本番 DB や会計 DB は MySQL を利用しています。これらの DB にはお客さま個人情報が含まれており、 SRE (Site Reliability Engineering) チーム以外がアクセスすることは許可されていません。
会計 DB を dump し S3 にアップロードする前に、 SRE チームがお客さま個人情報の削除や tsv 形式への変換、ファイルの圧縮などを行っています。 S3 に dump ファイルがアップロードされるまでの運用、監視は全面的に SRE に依存しています。
Redshift への取り込みとレポート出力
会計システムの開発者は S3 上にあるお客さま個人情報削除済みのファイルを読み込むことができ、 copy 句を使って Redshift に取り込みます。
「らくらくメルカリ便」などで外部の取引先から受け取る請求明細については、取引先側の担当者から別アカウントの S3 にアップロードしてもらい、 Embulk で Redshift に取り込みます。これらはそれぞれの取引先からの請求と対応するメルカリ側のデータとの突合に使用します。
MySQL から Redshift への移行
サービスを開始して2 ~ 3年は会計レポートの集計にも MySQL を利用していましたが、取引数の爆発的な増加や集計条件の複雑化に伴い、集計用のデータストアを Redshift へ移行しました。移行先としては BigQuery も候補に挙がりましたが、下記の理由から Redshift を選択しました。
- BigQuery と比較して MySQL クエリとの互換性が高いこと
- PHP から操作する場合に PDO の Driver を差し替えるだけで DB を変更でき、移行コストが低かったこと
MySQL 独自の関数を使っている箇所以外はほぼ同じ SQL が動いたので、移行はスムーズに進みました。また、移行に当たっては会計監査人へ移行プロセスの詳細な説明や一定期間並行運用した結果を共有しており、期末の監査もスムーズに進めることができました。
なお、 Redshift 移行の副次的な効果として、集計の高速化や分析関数の充実により月次の損益を詳細に分析することが容易になりました。速さは正義。お金で解決。
会計レポートの出力
データの取り込みやレポートの出力を行うプログラムは主に PHP、 SQL、シェルスクリプトを組み合わせて開発されてきました。
メルカリでは月次で会計レポートを出力しており、作成した会計レポート出力プログラムを cron で実行することでレポート出力を行っています(Redshift へのデータ取り込みも同様)。処理が失敗した場合は Slack に通知し、通知が送られてきたら調査を行います。
会計システムの集計結果は Google スプレッドシートにアップロードし、当月分の会計レポートとして Slack で経理チームに共有します。会計処理ごとにシートを分けて会計レポートを作成していきます。
最後に Google スプレッドシートから ERP への取込用のファイルを生成し、経理側で取り込むことで財務諸表に反映されます。
事後的な検証
会計システムが出力したレポートの正確性や品質を検証するには様々な方法があります。
最終的に全ての会計処理は債権債務関係の変動を表現する手段なので、会計レポートで出力した金額の集積と債権債務のあるべき残高(データベースや取引先からの請求書などから算出)の整合性を確かめることで事後的に会計レポートの確からしさを検証することができます。
例えばお客さまの売上金を検証するケースを考えてみましょう。売上金に関わるイベントを積み重ねると、売上金の履歴と一致するはずです。
- お客さま A が出品した 15,000 円の商品をお客さま B が購入
- A が商品を発送し、 B が商品受け取り後に評価、その後取引はつつがなく完了
- A に販売手数料 1,500 円控除後の売上金 13,500 円が付与される
- A が売上金 13,500 円から 10,000 円を引き出す
このとき、3. の時点では売上金は 13,500 円、4. の時点では売上金は 3,500 円です。もし3が6月25日、4が7月10日に行われたと仮定すると、6月末時点の売上金残高は 3. の 13,500 円だったことになります。
会計システムで起きた問題
サービス開始以来、会計システムの開発や運用を行う中で様々な問題が起きました。その一部をご紹介します。
いつの間にか新機能リリース
サービスに新たな機能が加わった・もしくは新たなサービスが始まった場合、会計システムの開発者と機能の開発者、経理の三者でコミュニケーションを取って必要となるデータの持ち方やイベントと会計処理の関係を定義する必要があります。
しかし、メルカリのリリース後しばらくは会計の優先度が低かったため、会計システム側の開発が必要であることに新機能・新サービスのリリース後や月次決算のタイミングで気がつくということがありました。このとき、サービス側のデータ構造によっては集計ロジックが複雑になる恐れがあります。 JSON をパースし中間テーブルを作って別のテーブルと JOIN して…ということもありました。
また、事業の発展に従ってサービス側の開発者が増加し新機能の追加がより頻繁に行われるようになったことで、会計システムに影響を及ぼす変更が加速度的に増加していき混乱が生まれました。
全社でプロジェクト管理に利用していた Redmine (現在は JIRA)のチケットテンプレートに「会計への影響度」という項目を入れたり地道な布教活動を行うことで、徐々に事前相談が来るようになりました。また、メルペイ等の大規模な開発の際に開発者へ会計で困っている点をフィードバックし設計時に考慮してもらうことで、社内での会計システムの認知度も向上していきました。
再集計すると過去の結果が変わる
会計システムでは、本番のデータ構造をそのまま用いて会計上の定義に従った SQL を実行していました。
たとえば「取引が完了した」ときに「クレジットカード決済にかかった決済手数料」を計算する場合、取引のテーブルを決済のテーブルに JOIN していました。このとき、元データの仕様や SQL の書き方によっては集計後に過去の集計結果が変わる可能性があります。例えば集計に使用しているカラムが集計後に update されるなど…
この件については、集計ロジックの工夫に加え、過去のレポートを再生成する際は会計レポートの集計時点のデータベースのスナップショットを使うようにしました。さらに、出力した会計レポートと過去の会計レポートの差分を検証するツールを作りました。
このようなチェックを自動化したり定期的に実行したりすることを考えると、集計結果をデータベースに保存しておいて再集計時に比較する処理を作ってもよかったかなと思います。実際には開発の優先度(新機能や新サービス、新たなアーキテクチャへの対応など)で着手できませんでした。
知識が属人化しやすい仕組み
このような会計システムでは集計ロジックが本番 DB のデータ構造に依存するため、新たな機能に関連した会計処理イベントを集計したり既存の集計への影響度を判断するにはメルカリの仕様やデータ構造に詳しくなる必要があります。
集計がシンプルな場合は問題がないのですが、メルカリは昨年の時点で60程度の会計レポート出力プログラムがあり、引き継ぎコストが非常に高い状態でした。
また、米国や英国での展開時も同じアーキテクチャで開発をしていたため、米国や英国でのビジネスや会計の慣行に詳しくなる必要もありました。これらは徐々に現地の開発者に引き継いでいきました。
担当者である私にとっては英語やデータ構造の勉強に繋がりましたが、問題を解決するために多くの知識や情報が必要で、結果的にとても引き継ぎづらい仕組みになってしまったと反省しています。
本番 DB の外部不整合
メルカリでは商品購入時の決済や配送などに関連して外部の取引先とデータ連携をすることがあります。
このとき、メルカリのデータベース内では整合しているが会計 DB の dump から計算した債権債務の金額と実際に入金・支払がされる金額に差異が生じている、というケースがありました。この点については債権債務の集計ロジック以外に、サービス側でのロジックや通信の障害、運用面での問題など様々な原因が考えられます。
このようなケースでは、支払や入金の元データを取引先から入手して Redshift に取り込んだ会計 DB の dump と全件突合し、差異となっているデータからパターンを抽出して帰納的に原因を調査し、必要なチームに対応を依頼もしくは経理に原因を説明するという作業を行っていました。お客さまとの関係においては決済のキャンセルや売上金の補填等で解決済みだが会計システムへの影響が対応時に考慮されていない、というケースが多かったです(お客さまに影響がある場合は最優先で解決されるが、会計にどう反映されるかまでの考慮が対応時に行われていなかったため、後から会計のみが困るということ)。
決済に関してはメルペイの開発時に会計への影響が考慮され、調査のコストが低くなりました。詳しくは下記の記事「マイクロサービスにおける決済トランザクション管理」もご参照下さい。
tech.mercari.com
Microservices 化に伴う DB の分散
メルカリでは2018年頃から本格的に Microservices 化に舵を切ることになりました(Microservices Platform at Mercari / logmi)。
この過程で、従来本番 DB に集約されていたサービスのデータが各 Microservices の DB へ Migration されることになりました。また、メルペイは初めから Microservices アーキテクチャで開発されることが決まっていました。
従来の会計システムの仕組みでは Microservices アーキテクチャに対応することが非常に困難だったため、会計システム自体も Microservices に合わせて根本的に新しいアーキテクチャでゼロから開発し直すことになりました。
Microservices化に合わせた新しい会計システム
新しい会計システムの開発にあたっては、従来会計システムの開発者が担っていた責任の一部を各 Microservices に負ってもらう必要があることから、それぞれの責任分担について整理することから始めました。
Microservices 化後の責任分担
会計システムにおける登場人物は下記の三者です。

それぞれの登場人物がそれぞれの社外関係者に対して負っている責任について考えてみます。
各 Microservices 開発者は他の Microservices と協同してお客さまに製品を提供する責任があり、経理には投資家や経営陣に財務報告をする責任があります。

これらの社外関係者に対する責任を効率的に果たすために、社内で議論や検討を行い次のような役割分担をすることになりました。

会計処理が行われるまでの責任の流れは次の通りです。
1) 各 Microservices がサービスの商流(お金の流れ)を経理に説明する
2) 経理が各 Microservices が送付すべき会計処理イベントを定義する

3) 各 Microservices がお客さまに製品を提供する
4) 各 Microservices が経理の定義に従って会計システムにデータを送る

5) 経理が会計システムの開発者に最終的に欲しい会計レポートの定義を伝える
6) 会計システムは経理の定義に従って会計レポートを生成する
7) 経理は財務諸表を作成し、投資家と経営陣に報告する

1) については Slack の様々なチャンネルをチェックしたり新規マイクロサービス開発時に必ず作られる Design Doc を見て能動的に対応するケースもあります。
会計システムも数ある Microservices の一つといえます。実際に、会計システムのインフラでは社内の Microservice Platform チームが提供するツールをよく利用しています。
新しい会計システムの仕組み
メルカリが自社内で利用している Microservices Platform が現在のところは Google Cloud Platform (GCP)の使用を想定していること、社内に知見が多く強力なサポートを受けられることから、新しい会計システムは全般的に GCP のマネージドサービスを組み合わせて開発しました。

システムが稼働する前に、経理が予め定義したイベントと会計処理の関係を Cloud Spanner にマスターデータとして保存しておきます。マスターデータは新たな会計処理が追加される度に追加され、各 Microservices から送られた会計処理データの Validation に使用されます。
実際の会計処理は図の左から右へ次のような手順で行われます。
- お客さまがメルカリやメルペイを利用する
- 各 Microservices が会計処理データを Cloud Pub/Sub に送る
- Cloud Pub/Sub に届いたデータが定義通りかつ不整合がないか Cloud Functions を使って Validation する
- Validation Error となるデータは Cloud Pub/Sub の Error topic に書き込む
- Validation 済みのデータは Cloud Spanner に書き込む
- メルカリの各 Microservices が GKE 上の Reconcile API を通じてデータの整合性を事後的に確認する
- Reconcile 結果を Spanner に保存し、メルカリの各 Microservices にレスポンスを返す
- Spanner に貯めた会計処理データを Cloud Composer と Cloud Dataflow で BigQuery に同期する
- 月次でレポート生成のバッチ処理が行われ、 Slack 経由で経理チームに会計レポートを渡す
会計処理データは月次で締め切られ、毎月1日まで前月分のデータを訂正することができます。会計レポートは毎月2日に集計されます。2日以降に届いたデータは翌月の会計処理になります。
修正に際してはレコードの update や delete は行わず、削除用のインターフェースを用意して各 Microservices から削除依頼をもらい、それを通常の会計処理データと別のテーブルに保存しています。
会計処理データの形式
新しい会計システムでは、各 Microservices が会計システムに送る会計処理データの形式を統一しています。
サービス上であるイベントが発生したとき、イベントごとに複数の会計処理が必要なケースが考えられます。例えばお客さまがメルカリ上で「ポイント」と「クレジットカード」を併用して購入を行った場合、一つの購入から2つの会計処理が発生します。
この「イベントと会計処理の関係」ごとに id (社内で matter_id と呼んでいます)を発行し、その id に借方と貸方の仕訳科目や許容する消費税区分を設定することで、受け取ったデータの Validation や会計レポートの生成に使っています。
会計処理データを保存する Spanner のテーブルでは下記の3つのカラムを合わせて Primary Key としています。
- 各 Microservices 側で取引や決済を一意に識別できるユニークな ID
- 上記の matter_id
- どの Microservice が送ってきた値かを示す service の id(service_id と呼んでいます)
送られるデータは下記のようになります(実際にはユースケースに合わせてより多くの項目を送ってもらっています)。
"data": [
{
"id": "61105CF1-A953-496E-9B65-B230DDC84D35", // サービス側のユニークな id
"matter_id": "merpay-balance-add-funds", // イベントと会計処理の関係を定義する matter_id
"service_id": "1", // どのマイクロサービスかを識別する service_id
"amount": "900", // 会計処理の金額
"date": "2018-07-18T12:14:07+0900", // イベントが発生した日時
"vat_type": "5", // 消費税区分
"client_dr_customer_id": "A001", // 借方に対応する取引先の id
"client_dr_customer_type_id": "1", // 借方取引先 id の種別(お客さま or 加盟店さま)
"client_cr_customer_id": "A003", // 貸方の取引先 id
"client_cr_customer_type_id": "1", // 貸方取引先 id の種別
"client_value": "xxxxx", // クライアント側が自由に内容を決める項目
"option_value": "yyyyy" // 会計システム側が自由に内容を決める項目
}
]
}
あらゆる取引で顧客の識別 id を送ってもらうことで、顧客 id ごとに会計上の債権債務残高を集計することが可能です。
リコンサイル API
新しい会計システムのデータは会計処理だけでなく加盟店さまへのお支払い(後述)にも使われるため、信頼性を高めなければなりません。
このために、各 Microservices が Cloud Pub/Sub に送付した会計処理データを事後的に突合(リコンサイル)する API を用意しています。
API のプロトコルには gRPC を採用しています。各 Microservices はリコンサイル API に対してリクエストを送り、レスポンスを元に調査を行う責任があります。リコンサイル API は Primary Key に相当するデータやイベントの発生日時、金額などを受け取り会計システム側のデータベースとの整合性をチェックします。
Microservices と会計システムとの間でデータの不整合が発生するケースは、何パターンか考えられます。
- 双方にデータが存在するが、特定の項目のみ不整合
- Microservices 側のみにデータが存在する
- 会計システム側のみにデータが存在する
3 のパターンについては Microservices 側からリコンサイルがされないまま残ってしまいます。これを検知するため、リコンサイルの進捗状況は会計システム側でもバッチ処理で定期的にチェックしています。
バッチ処理
新しい会計システムでは会計レポートの集計以外にも、下記のように様々なバッチ処理が稼働しています。
- Spanner のバックアップを保存
- 前日分の会計処理データを Spanner から BigQuery に同期
- 前日分の Reconcile 状況を BigQuery で集計し集計結果を Spanner に保存
- Reconcile されていない会計処理データの件数を集計、通知
- 加盟店さまへの支払用データ出力(後述)
これらのバッチ処理の多くは Cloud Dataflow を利用しています。ジョブを定期的に起動する際は Cloud Composer を利用しています。
柔軟性が欲しい場合、manifest ファイルを作って GKE から cron job で動かすこともあります。
加盟店さまへのお支払いについて
会計システムのデータは会計処理だけではなく、メルペイの加盟店さまへの支払を作成するための元データとしても使われています。
支払時には加盟店さまへの支払額に影響する各 Microservices から Reconcile で整合性が保証されたデータのみを Spanner から GCS に出力し、メルペイ側で加盟店精算を行う Microservice が GCS からファイルを取得して支払データの生成や未払残高の操作を行っています。
メルペイと会計システムとの関係については builderscon tokyo 2019 の @kazegusuri さんによる発表資料「Open SKT: メルペイ開発の裏側」をご参照ください。
今後の課題
新しい会計システムはメルペイに合わせて2019年1月にリリースされ、決算や監査を経て8ヶ月ほど運用されています。この中で様々な課題が明らかになりました。
関係者への責任分担の浸透
前述の通り、この新しい会計システムで正確かつ適時な会計報告を行うには、各関係者がそれぞれの責任を果たす必要があります。
会計システムの導入にあたり、プロジェクトの背景やそれぞれの関係者に対応してもらう必要がある内容をスライドやドキュメントにまとめ、説明して回りました。
しかし、実際には会計処理データの送付やリコンサイル API へのリクエストを担当する各 Microservices や、イベントと会計処理の関係を定義してもらう経理などの関係者全員に自身の責任や役割を理解してもらいそれぞれの責任範囲について合意することがとても難しかったです。
決済やお客さまの残高を管理する Payment Platform のチームとは会計システムの開発段階から密にコミュニケーションを取り、スムーズに開発を進めることができました。しかし、中には会計関連の開発優先度を上げてもらうために度重なるコミュニケーションが必要な Microservice もありました。
コミュニケーションを進める中で気をつけたことは、「可能な限り早めに伝えること」です。会計の要件を満たすにはそのためのデータを保存しておく必要があり、設計の早い段階(データ構造などを決める)から各 Microservices の開発者に会計の要件を認識してもらう必要があります。つまり、経理や Microservices 開発者などの各関係者ができるだけ早いタイミングで会計関連の開発が必要なことを認識し、それに向けて行動していくよう促すことが重要です。なお、会計の考慮は設計段階でしておくべきですが、実際に開発を行うまでは間が空くため、人の入れ替わりが多い現場では繰り返し伝えることも大切です。
現在は社内向けのアーキテクチャ研修で会計の話がされていたりドキュメントの整備や地道な布教活動などにより、徐々に改善しています。
クライアント実装時のコスト
新しい会計システムでは会計処理データの送付や Reconcile API の呼び出しを各 Microservices に依存しているので、各チームにデータ送付やリコンサイルのための開発をしてもらわなければ、会計システムは責任を果たすために必要なデータを入手することができません。
しかし、会計関連の開発の優先度は後回しにされがちでスケジュールの皺寄せが来ることもありました。
この点については、会計関連の開発で参考にできる実装例があると実装のためのコストが下がると考えたので、会計システムの開発チームで参考になるような実装サンプルや開発が必要な機能が揃った SDK のようなツールを開発することを検討しています。
システムの運用負荷
当初の会計システムではインフラやデータベースの運用を SRE チームに依存していましたが、新しい会計システムでは会社の方針で開発者が本番環境の運用も行っています。
その中で、本番環境へのマスターデータ登録やインフラのメトリクス監視、障害対応など運用関連のタスクが増加しました。
この点については、運用業務を楽にするような管理画面やツールの開発、 SLI/SLO の明確化などを進めていきたいと考えています。
内部統制について
財務情報に影響するシステム(サービスの本番環境も含む)を開発する際に気にしなければならない枠組みとして、 ITGC (IT 全般統制)や J-SOX(内部統制報告制度)と呼ばれる内部統制の仕組みがあります。
上場企業や上場準備企業など会社法上の会計監査人設置会社において独立監査人が会計監査を行う際、財務諸表に重要な虚偽表示が無いことの合理的な保証を得るため、財務諸表を出発点として目標を監査要点に分解して(例えば「売上は適切に集計されているか」など)監査を行います。
このとき、メルカリのような大規模サービスを運用している会社では全ての証憑(たとえばデータベースのレコード)を目視で確認することは現実的に不可能ですので、財務報告に影響する部分の内部統制の整備状況や運用状況を評価し、実際の証憑は無作為にサンプリングしたデータを用いて監査を行います。
実務上は様々な監査手続が考えられますが、原則的には自社のアクセス権管理や変更管理、運用管理などについて定めた規程や Risk Control Matrix (RCM) に沿った開発や運用が行われているかが論点になります。特に今回ご紹介したような会計システムについては、下記に注意する必要があります。
- 会計システムの元データのバックアップが取られていること
- 実際に会計処理に使用した会計レポートを事後的に再生成できること
- 会計システムの開発時に開発者と別の第三者がレビューを行い、その証拠を残すこと
- 会計システムの動作している環境へ読み書きする権限が適切な範囲に限定され、付与時に第三者によるレビューがされ、且つ定期的に棚卸されていること
- 開発者と別の特定の権限を持つ者がリリースの承認を行い、その証拠を残すこと
レビューや承認の証跡を網羅的に残すのは面倒ですね。
メルカリでは GoBold さんと呼ばれる Bot が活動しており、特定の GitHub リポジトリに対して下記のチェックを自動でやってくれます。
- Pull Request (PR)作成者以外が PR を Approve し、特定のラベル(LGTM)を付けていること
- PR 内にチケットへのリンクが記載されていること
- リンク先のチケットが特定のステータス(リリース承認)になっていること

Looker を使った分析用ダッシュボード
メルカリでは Looker というダッシュボード作成サービスを利用しており、会計システムでも分析用途で導入しています。 Looker については下記の記事もご覧ください。
- プロダクトのリリース前から新ダッシュボード「Looker」の導入に踏み切ったわけ
- BIツール「Looker」の分析画面について紹介します
- メルカリにおける Dashboard Replacement の事例

新しい会計システムでは、各 Microservices から送られた会計処理データを最終的に BigQuery に保存しています。
この BigQuery を閲覧できる GCP サービスアカウントを作成し Credential を Looker の管理画面から登録することで、 Looker を用いて会計システムのデータを可視化するダッシュボードを作ることができます。
Looker は LookML というフォーマットでデータ同士の関連性を定義しておくことで SQL を書かずにグラフィカルなダッシュボードを作ることができるので、分析に重宝しています。
Looker 用のサービスアカウントについて
Looker の document ではサービスアカウントに BigQuery Job User と Data Editor をつけるように書いてありますが、実は Data Editor が無くても Connection を張ることはできます。
その代わり Derived Table が使えなくなるので、パフォーマンスが大きく下がります。メリットは特にありませんが、運用上の理由で Data Editor 権限をつけたくない方はご参照ください。
会計システムの未来
長々と書いてしまいましたが、会計に関するほとんどの課題は履歴形式のデータとそのコンテキスト(履歴の各行に対する会計的な意味づけ)で解決することができます。将来的にはマネージドサービスで問題を解決するケースがより増えていくのではないでしょうか。
この観点から私たちが注目している製品の一つが Amazon QLDB です。会計システムの観点からは、台帳形式のデータベースに発展の可能性を感じます。
終わりに
本記事が私たちと同じような問題を抱えている人に届けば幸いです。
経験のある開発者の方々からすると至極当然のことでも、初めて取り組むとたくさんの地雷を踏んでしまうことがあります。正直に申し上げると、私もいち担当者として「このままで上場できるのだろうか…」と不安を抱いて眠れない夜もありました。
しかし、最終的にはチーム内外の多大なるご協力や地道な調査と不整合データの補正、会計・内部統制監査を経て、信頼性の高い財務情報と目的に適合するアーキテクチャにたどり着くことができました。
とはいえ、数年後にはどうなっているか全く分かりません。複雑な状況に対応し続けるためにやらなければならないことはたくさんあります。メルカリ・メルペイでは日々の開発や運用の中でたくさんの成功や失敗が生まれており、大胆な挑戦から様々な経験を積むことが可能です。
会社の採用情報はこちら。
次回の記事は @catatsuy による「Google Cloud Functionsを使ってSlackで簡単にCDN上のキャッシュを消せるようにする話」です。お楽しみに!



