この記事は MERPAY TECH OPENNESS MONTH の9日目の記事です。
株式会社メルペイのSolutionチームでデータエンジニアをやっている @orfeon です。
この記事ではGCPのデータストアサービスやプロジェクトをまたいでデータを活用するためにメルペイで活用しているDataflow Templateについて紹介します。
メルペイでは各マイクロサービスで Cloud Spanner、BigQuery、Cloud Storage、Cloud SQL、Cloud Datastore など様々なGCPのデータストアサービスを活用しています。
マイクロサービスによってはこれらデータストアサービス間でデータを加工・移動して活用しなければならないこともあります。
例としては、Spannerから店舗ごとに売上を集計してCSVファイルとしてCloud Storageに保存してダウンロードできるようにしたり、SpannerやDatastoreのデータをCloud StorageにAvro形式でバックアップを残すことなどが挙げられます。
また複数のマイクロサービスにまたがって必要とされるデータもサービス間で適切に加工して移動する場合もあります。
こうしたデータストアサービス間のデータの移動処理には定型的なものも多いです。
メルペイのSolutionチームでは、社内でよく必要とされる定型的なデータ加工・移動処理を実装し、社内の開発者やデータアナリストが簡単に使えるテンプレートとして提供しています。
この記事ではこうしたテンプレートの活用内容を紹介していきます。
Cloud Dataflow Template
GCPのデータストアサービス間のデータの加工・移動には Cloud Dataflow を活用しています。
Cloud Dataflow はBatch処理もStreaming処理も統一的に扱えるプログラミングフレームワークであるApache Beamを使って書かれたソフトウェアを、フルマネージドに実行できるサービスです。
Apache Beamは複数のプログラミング言語に対応していて、Java、Python, Go(experimental) の SDK が提供されています。
Python SDKはアドホックにデータ処理をしたり機械学習ツールと連携するのに使いやすく、一方Java SDKは機能やConnectorが充実しており性能的に有利であるといわれています。
今回の用途では定型的な処理を行うこと、大規模なデータを扱うため高い性能が求められること、様々なデータストアサービスと連携する上でConnectorが充実していることが重要であるため、Java SDKで開発を進めました。
Apache Beamで記載したPipelineコードをビルドしてCloud Dataflowにデプロイして動かすことになるのですが、コードをあらかじめビルドしてGCSに登録しておき、必要なパラメータを実行時に指定してDataflowでPipelineを起動するDataflow Templateという機能があります。
Dataflow Templateの機能を使うことで、GUI上の操作や、Dataflow APIを経由した必要最低限の開発で登録したデータ処理パイプラインを実行することができます。
Google-Provided Templates
異なるデータストアサービス間のデータ移動などの定型的な処理を実行するDataflow Templateが、Googleから公式のテンプレートとして提供されています。
公式テンプレートはブラウザでDataflowのコンソール画面から必要なパラメータを指定して簡単に実行できますし、プログラムからAPIを呼んで実行することも可能です。
公式テンプレートではBatchからStreamingまで様々なデータ処理パイプラインが提供されており、GCPのデータストアサービス間の大方の定型的なデータ処理はここで見つけることができるかと思います。
Dataflowで定型的なデータ処理を行いたい場合にはまず公式テンプレートで使えそうなものがないか探してみると良いと思います。
今回作成した Dataflow Template
必要とするデータ処理パイプラインが公式のテンプレートで提供されていない場合はテンプレートを自作することになります。
メルペイでは様々なGCPのデータストアサービスを利用していますが、特に Cloud Spanner を主要なデータベースとして利用しています。
社内からはSpannerのデータベースから特定の条件を満たす一部のレコードだけを取り出して処理したいという要望をよく頂きました。
しかし公式テンプレートではSpannerへの任意のクエリ結果を処理するテンプレートは提供されていませんでした(2019/05/28時点)。
そこで社内の定型的データ処理の最初のテンプレートとして、Spannerに任意のクエリ結果を処理するカスタムテンプレートを整備していくことにしました。
要望を整理しSpannerからの任意のクエリ結果の処理を支援するために以下のようなテンプレートを用意しました。
- SpannerToText, SpannerToAvro
- 内容: Spannerへの任意のクエリ結果を指定したGCSのパスにJson,CSV,Avroフォーマットで保存する
- 用途
- Spannerテーブルの差分バックアップ
- マイクロサービス間のデータ移動
- GCSにワンクッション置くことで送り手/受け手で負荷などの責任範囲を分離
- SpannerToSpanner
- 内容: Spannerへの任意のクエリ結果を指定したSpannerテーブルに保存する
- 用途: DMLでは対応できない大規模Spannerテーブルのコピー
- 性能検証用の大規模テーブルをコピーし性能テストを平行して実施可能に
- SpannerToSpannerDelete
- 内容: Spannerへの任意のクエリ結果のKeyをもつレコードを指定したテーブルから削除する
- 用途: DML, Partitioned DMLでは対応できない超大規模な不要データを削除
- SpannerToBigQuery
- 内容: Spannerへの任意のクエリ結果を指定したBigQueryのテーブルに保存する
- 用途: データ分析に有用なデータをフィルタして定期的にBigQueryに投入する
以下、これらのテンプレートのために開発したSpannerから任意のクエリを読み込むモジュールについて紹介していきます。
SpannerQueryIOの開発
Spannerから任意のクエリ結果を取得するためにSpannerQueryIOというモジュールを作成しました。
SpannerQueryIOの要件としてクエリ結果のレコードが大量であっても高いスループットで読み込めることが挙げられます。
この要件を実現するために、SpannerのPartitioned Queryと、ユーザによるクエリ分割のサポートを採用しました。
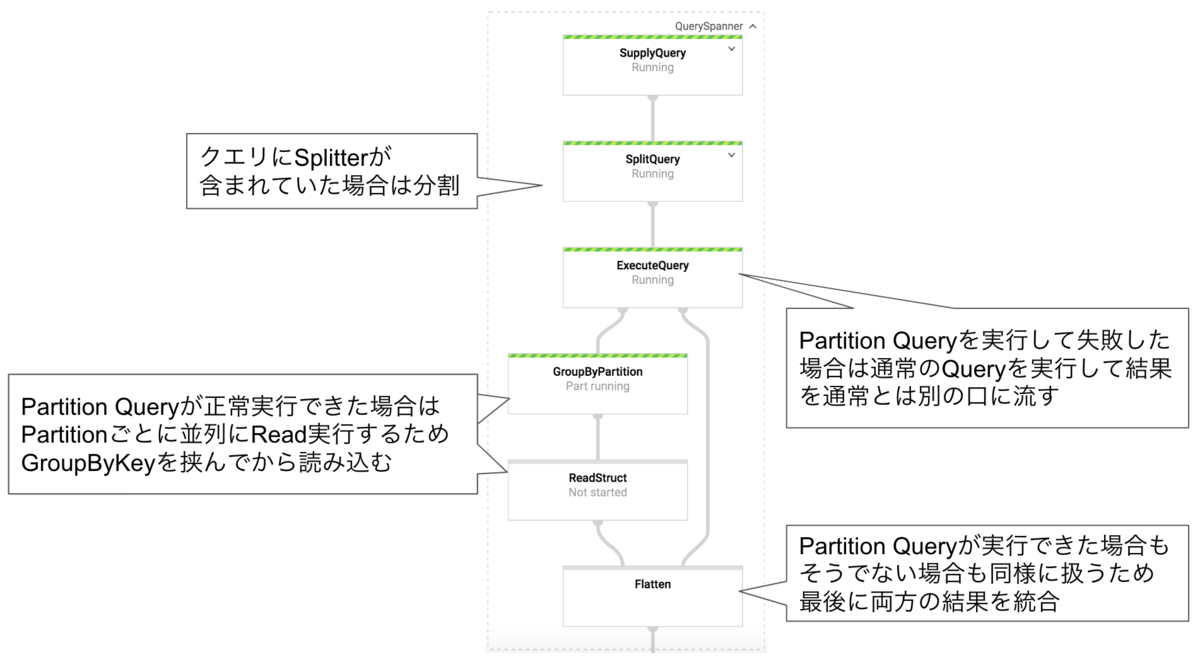
以下図はSpannerQueryIOの全体処理を表したものですが、これらの施策について説明していきます。

Partition Query
Cloud Spannerから大量のデータを読み取るときは、クエリをより小さな部分(パーティション)に分割し、複数のマシンを使用してパーティションを並列に取得・処理することでより高速に読み込むことができます。
以下、Cloud SpannerクライアントライブラリによるPartition Query実行のコード例です。
BatchReadOnlyTransaction transaction = batchClient .batchReadOnlyTransaction(TimestampBound.strong()); PartitionOptions options = PartitionOptions.newBuilder().build(); Statement statement = Statement.of("SELECT * FROM table"); List<Partition> partitions = transaction.partitionQuery(options, statement); // この部分を複数マシンで並列に実行する for (final Partition p : partitions) { try (final ResultSet resultSet = transaction.execute(p)) { while (results.next()) { Struct struct = resultSet.getCurrentRowAsStruct(); .... } } }
このようなクエリ分割ができるのはクエリ実行プランの root operator が Distributed Union の場合だけです。
クエリの最後にORDER BYやLIMIT句があるようなクエリだと root operator が Distributed Union にならないので、Partitioin Queryとして実行しようとするとエラーが発生して失敗します。
そのためPartition Queryが実行可能かどうかで、別々にテンプレートを用意することも考えました。
しかしテンプレートの利用者が自分が実行しようとしているクエリがPartition Queryで実行可能かを判断して使い分けるのも面倒ではないかと思いました。
そこで単一のテンプレートでPartition Queryも通常のクエリも両方対応できるようにしました。
Dataflow Template では実行時に動的にパイプラインを構成することはできないので、両方のパイプラインを用意しておき、実行時にPartition Queryが実行可能かどうかでデータの流し先を分岐するようにしています。
クエリをSplitterで分割することによる並列実行のサポート
Partition QueryはSpannerのクエリプランナーが並列化できるようクエリをPartitionに分割してくれる機能ですが、
ユーザがクエリを明示的に並列化できるよう分割して実行できるようにも対応しました。
以下のようにクエリに–SPLITTER–の文字列が含まれていた場合、その文字列でクエリを分割して並列にそれぞれ実行します。
大量の結果を含むクエリを、cardinalityの大きいフィールド値に応じて別々に結果を取得できるよう、負荷バランスよく分割することで、処理を高速に終わらせることができます。
SELECT * FROM sometable WHERE MOD(ABS(FARM_FINGERPRINT(key)),3) = 0 --SPLITTER-- SELECT * FROM sometable WHERE MOD(ABS(FARM_FINGERPRINT(key)),3) = 1 --SPLITTER-- SELECT * FROM sometable WHERE MOD(ABS(FARM_FINGERPRINT(key)),3) = 2
Partition Query は、クエリによってはPartitionごとのデータのばらつきが大きく、一番負担の大きいPartitionに引っ張られて処理が遅くなってしまうこともあります。
処理時間やSpannerへの負荷を細かくコントロールしたい場合にはユーザによるクエリ分割が有効です。
データ変換モジュールの開発
様々なデータストアサービス間でデータを移動するには、各サービス間のフォーマットに合わせてデータを変換する必要があります。
データストアサービスの種類が多いとその組み合わせ分だけ変換モジュールを作る必要があり、工数的にしんどくなってしまいます。
幸い、会社の用途ではSpannerが中心的に用いられること、多くのGCPデータストアサービスでレコードをAvro形式として扱うことができること、これらのデータ構造が入れ子の配列と構造体を扱える汎用性の高いフォーマットであることから、データ変換において Spanner の Struct と Avro の GenericRecord 形式を経由することで、データ変換モジュールの工数を抑えることができました。
おわりに
Dataflow Templateを利用することでデータストアサービス間の定型的なデータ加工・移動処理を簡単に利用できるようになります。
この記事ではSpannerからのデータ読み込みを中心としたメルペイでのDataflow Templateの活用例を紹介しました。
今回紹介したテンプレート以外にも、現在ではGCPのデータソース間でなめらかにデータを変換・活用するための様々なテンプレートを作って活用しています。
メルペイで開発しているこれらのDataflow Templateは近日中にOSSとして公開できるよう準備を進めています。
GCPのいろいろなデータストアサービス間でデータ移行を検討している人は楽しみにしていただけると幸いです。
次はyoshiki.shibataさんによる「gPRCを用いたマイクロサービスのAPI仕様の記述」です。お楽しみに!




