Mercari Advent Calendar 2018の24日目はメルカリBackendエンジニアの@sota1235がお届けします。
現在、私はWebのシステムをリプレースしMicroservicesアーキテクチャに移行するチームで働いています。
メルカリのMicroservicesアーキテクチャでは各Microserviceチームが責任を持ってSLI/SLOを定め、運用する必要があります。
このSLI/SLOを決める過程でいくつかの学びや難しさがあったのでそれをお話しようと思います。
SLI/SLOとは
SLI(Service Level Indicator)とはサービスの品質を測るための指標です。
そしてSLO(Service Level Objective)とは各SLIに対しての目標数値です。
例えばSLIを全リクエストの50xエラー以外の割合として、SLOは99.99%とする、といったイメージです。
この記事でSLI/SLOについて解説してしまうと日が暮れてしまうのでより詳しく知りたい方は下記記事をご覧ください。
cloudplatform-jp.googleblog.com
Web MicroservicesにおけるSLI/SLO
私のチームでは現在、メルカリWebのシステムリプレースを進めています。
この記事ではその具体的な内容には触れませんが、興味のある方は今年のMercari Tech Confでのスライドをご参照ください。
また、喋った内容は下記でも見ることができます。
私達のチームでは4つのMicroservicesを運用します。
メルカリにおけるSLI/SLOは各Microservicesに定義し、運用していくことを求められているのでWebチームでは4つのSLI/SLOを定める必要があるということです。
今回はWebチームでこの4つのSLI/SLOを決める過程で難しかった点や使うとよかった考え方を共有します。
そもそもなぜSLI/SLOを決めるのか
何かを決めるとき、そこには必ず理由がありますしその理由から常に決めるべきです。
SLI/SLOを決める理由は品質の維持を行うためです。
今までのメルカリのMonolithicアーキテクチャでは、各エンジニアがOwnershipを持ってサービス運用や障害対応を行っていましたが、最後の砦として品質の維持をする責務を持っていたのはSREチームでした。
これがMicroservicesアーキテクチャになってからは各Microserviceチームがそれぞれの可用性、品質を維持する必要があります。
そしてその品質の維持は誰のために行うのかというとサービスを使うお客様のためです。
Webチームの場合、メルカリのWebサイトにアクセスしてもらうお客様のためにSLI/SLOを定め、品質の維持を行う必要があります。
SLI/SLO決めの際のディスカッションでチーム内で対立が起きたときは必ずこの視点に立ち戻るように意識して決めていきました。
Web MicroservicesにおけるSLI/SLO決めの難しさ
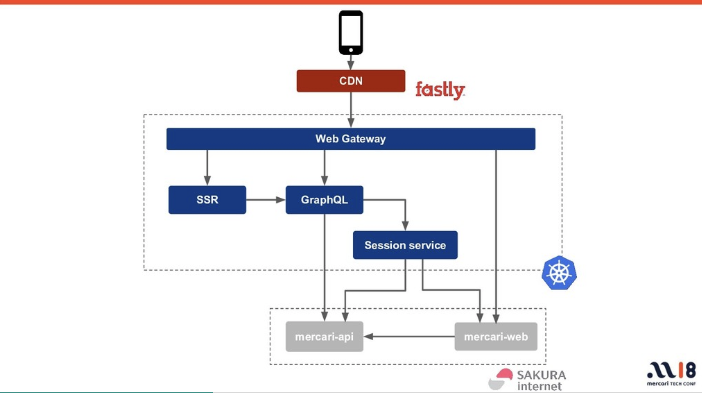
Webチームで運用することが決まっているMicroservicesは以下の4つです。

- Web Gateway
- メルカリWebへ来る全てのHTTPアクセスをハンドリングし、各Microservicesへリクエストを振り分ける
- SSRサーバ
- メルカリWebのHTMLをレンダリングするサーバ
- Next.jsを利用し、初回アクセス以降はSPAとして振る舞う
- GraphQLサーバ
- SSRサーバからアクセスされるサーバ
- internal、ブラウザ両方からアクセスを受ける
- データの取得から更新処理まで原則、このGraphQLサーバが担う
- Session Service
- 各Web Microservicesコンポーネント間のセッション整合性を担保するgRPCサーバ
- Browserからはアクセスされず、Internalでのみ稼働する
これらのSLI/SLOを決めるとき、まずいちばん最初に感じたのは「どこから手をつけるべきか?」ということです。
各Microservicesはお互いに通信し合うため、例えばSSRサーバのSLOを99.99%にしたいと思ったとき、Web GatewayのSLOが99.9%だと達成できないのでは?というような依存関係が存在します。
そしてそれなりに複雑なやりとりが行われる4つのMicroservices間でそれらの依存関係を完璧に解決したSLI/SLOを定めるのは率直に難しいと感じました1。
一旦、他のサービスを忘れる
そこでチームで取ったアプローチは「そのMicroserviceの役割だけを考えてSLI/SLOを設定し、その後ですり合わせる」ことでした。
まずチーム内からそれぞれのMicroserviceのSLI/SLO決めのOwnerを決め、それぞれの視点でSLI/SLOを設定してもらいました。
その後、それぞれのSLI/SLOをすり合わせて適宜調整して決めていきました。
例えばFrontendエンジニアの視点でSSRサーバのSLOを99.99%に定めたならばそれが依存する他MicroservicesのSLOも高めに設定する、等です。
この際、どちらも譲れずに議論が平行線になった際は最終的にお客様にとって何が大事なのか、という視点で決めていきました。
FrontendのSLI/SLOの難しさ
4つのMicorservicesの中で一番SLI/SLOを決めるのが難しいと感じたのはSSRサーバです。
従来の1Request、1ResponseのHTTPサーバであれば例えばHTTP RequestのSuccess RateをSLIとして運用することができ、また計測の難易度も高くありません。
しかしSSRサーバの場合、HTTP Responseは返せていてもその後のJavaScriptの振る舞いや通信するGraphQLのレスポンス次第で品質に影響が出る可能性があり、何をどこまで追い求めるべきか今まで以上に考える必要があります。
例えばSPAの何かしらの処理でのエラー2を利用したSLIにした場合、Request数を母数にすることはできないので何を母数にするのか。そもそも絶対数で計測するのか等、考えなければいけないことがかなりあります。
完全にfixしていない、かつ運用後に見直す前提ですが現在Webチームでは以下のようなSLI/SLOを検討しています。
- HTTP Success Rate
- HTTPサーバとしての可用性を担保する
- ページロードの最大値
- 例えばどんなに時間がかかっても1000msecまでしかページロードを許容しない、という意味です
- ページロードの平均値
- 全てのページの値が900msecだと最大値には引っかからないものの全体の体験として悪くなる可能性があるので平均値も別で定めています
これ以外にも例えばRAILモデルに沿えているかを計測する、Lighthouseのスコアを見る等の案がありましたが一旦、3つ程度のSLI/SLOで行く方向性で考えています。
狙いとしては最初にSLIが多すぎる、また計測が難しいものを多く取り入れると運用自体の難易度が上がり開発どころではなくなる可能性があるため、まずは最低限お客様にとって影響のある指標を守れるようにして、徐々に改善していこうという流れです。
SLI/SLO決めの良さ
ここまでSLI/SLO決めの難しさばかりを語ってきましたが、これをきっかけに得られたものも多くあります。
Microservice間の依存関係を見直す
HTTP Success RateというSLI/SLOだけで見てみると、SSRサーバのSLOよりも、その依存先であるGraphQLサーバのSLOの方が高くあるべきと考えることができます。
なぜならSSRサーバはほぼ全てのページでGraphQLサーバへアクセスするからです。
しかしここでMicroservices化する意味や、あるべき姿について考えます。
例えばGraphQLサーバの責務はデータ、更新系APIの提供。SSRサーバの責務はお客様にレンダリングされたページを返すことだと言えます。
するとSSRサーバは他のMicroserviceコンポーネントがどのような振る舞いをしていようが、自分の責務をどう全うするかを考えるべきです。
例えばGraphQLサーバが落ちていたときにSSRサーバの返すページが真っ白になっていてよいかというとそうではなく、500ページをきちんとレンダリングして、お客様に意味のあるページを見せるべきです。
このように考えていくとSLI/SLOは必ずしも自分が依存するサービスのSLI/SLOに引っ張られていいわけではない、ということがわかります。
わかりやすい例でいうとSession Serviceが落ちていてもGraphQLサーバもSSRサーバも全ページを未ログインユーザ向けのものに変えることで可用性は担保できますし、他にもそのようにフェールセーフ、フェールソフトの考え方で別Microserviceとの関係性を考えるきっかけになりました。
アプリケーションレイヤー以外への意識
SLI/SLOを考えると他のMicroservicesだけでなく、自分たちが利用するミドルウェアやデータベースのことも考えるきっかけになります。
考え方は先程と基本同じですが、例えばSLOを99.99%に保ちたいMicroserviceがあるとします。
そして使用するデータベースの候補が2つあり、それぞれSLA(Service Level Agreement)3が99.99%, 99.9%だとします。
今までであればSLAは気にはするものの、基本的には使いやすいものや性質を考えて選ぶ場面が多かったように感じますが、Microservicesアーキテクチャでは各チームが原則全てを運用するのでこの技術選定の際にそのSLAも比較項目に加える必要があります。
また、使用するデータベースないしはミドルウェアが動作しないときにアプリケーションがどのようにあるべきかも合わせて今まで以上に考えていく必要があります。
まとめ
SLI/SLOは決めるのがゴールではなく、サービスを運用すると同時にきちんと守っていくことがゴールです。
Webチームではまだまだチャレンジが始まったばかりですが、運用する過程で得た知見等をまたブログなりでアウトプットできればと思います。
明日は@codehexの記事です。お楽しみに!




