こんにちは、はじめまして。メルカリでデータエンジニアをしている、しゅう (@shoe116)です。Mercari Advent Calendar 2018の3日目を担当することになりました。
メルカリではデータの活用が盛んな一方で、実はデータ処理を専門にやるエンジニアが最近まで存在しておらず、そんなこんなで僕がSREチームにデータエンジニア第1号としてjoinしました(実はこのあたりはメルペイのが少し先んじていて、あっちにはすでにデータプラットフォームチームがあって、僕は今彼らと一緒に並んでコードを書いている)。今日は僕らがGoogle Cloud Platform(以下GCP)に作っている、メルカリ(とメルペイ)の新しいログ収集基盤について簡単に紹介しようと思います。
メルカリの既存ログ収集基盤について
「新しいログ収集基盤を紹介しようと思います」と書いた数行後にこの章を持ってくるのは自分でもどうかと思うのだけれど、話の都合上「既存のメルカリのデータ分析基盤」に少し触れさせてほしい(どうにもしっくりこないので、本文はです・ます調は諦めて、いつもどおりの口調で書くことにしました)。
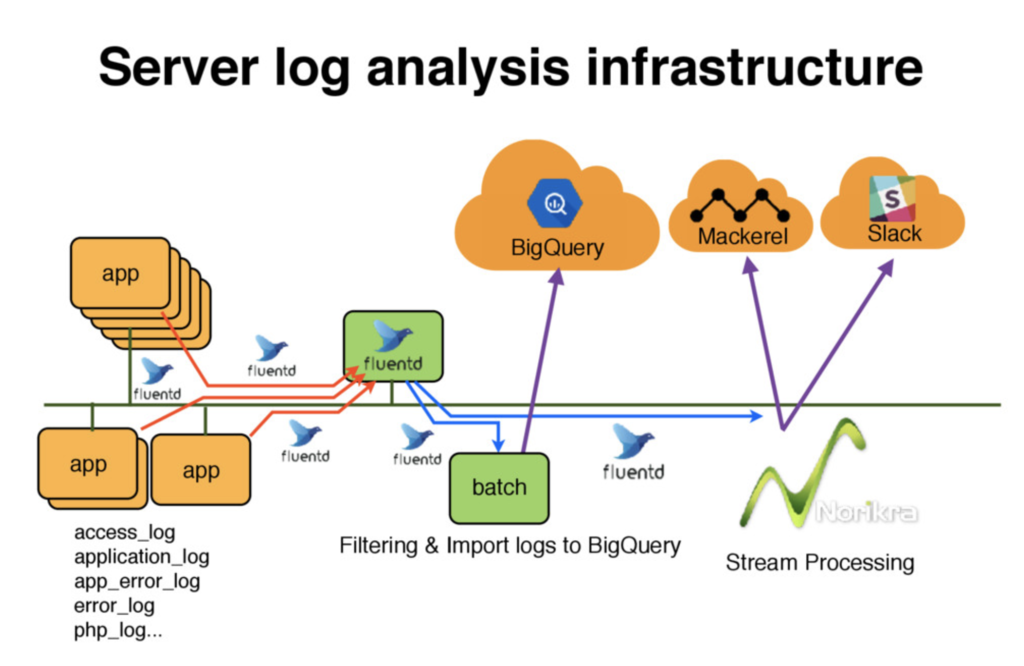
メルカリのログデータの分析基盤は、これまでもこのブログでも何度か紹介されている1ように、ものすごく簡単に言うと 「Fluentdで集めてbatchでGoogle BigQueryに同期」 が基本構成だ2。

最終的な出力先であるBigQueryはDWHとして非常に便利で、BIチームに限らず多くの人がこのデータを日常的に利用しているのだが、このログ回収の仕組みには
- batch処理でBigQueryに同期している都合上、データを利用できるまでにタイムラグ(数時間)がある
- Fluentdのプラグインを複数利用してデータ転送と同時にデータ加工を行っているため、転送経路(すなわちインフラ構成)を熟知していないとデータ処理の開発・運用が困難
という課題があって、データの利用の観点では前者が、MonolithからMicroservicesへのアーキテクチャ変更にとっては後者が問題になる。
新データパイプライン
上記2つの課題を踏まえ、Microservicesアーキテクチャを想定し
- ログの収集とデータ加工のフェーズを分ける(収集時はデータをいじらない)
- 低latencyを実現するためにStream処理で構成する
- 生データの蓄積だけではなく、使いやすく構造化した出力もサポートする
をコンセプトに、下図のようなデータパイプラインをGCPに構築した。

なお、オンプレやAWSではなくGCPを選択した理由は、
- 各マイクロサービスはGoogle Kubernetes Engineで動く
- 最終的なデータ分析の多くはBigQueryで行われる
ということを鑑みたことによる*3。
この章では、このデータパイプラインについて紹介していく。
コンポーネントと処理概要
各マイクロサービスには、ログ投げ込み用のCloud Pub/Subの"Ramp"を提供する。Cloud Pub/SubはMessageのpayloadに、任意のバイト列(Javaでいうところの byte[])を持たせる事ができる。Rampに投入された全Messageは、Cloud DataflowのStreaming処理を用いて集約用のCloud Pub/Sub "RawDataHub"に集める。この際、PubsubMessageのpayloadは一切変更せず、後続の処理に必要なメタデータ(Rampのtopic名やスキーマ情報、パイプラインのMetricに必要なデータ等)はPubSubMessageのattribute(JavaだとMap<String, String>)に付与する。このDataflow Jobではサービスやtopic毎の処理は行わず、全てのメッセージを画一的に扱う。
RawDataHubのデータは、更にCloud DataFlowの3つの独立したStreaming処理で "RawDataLake"、"StructuredDataLake"(いずれもインフラはGoogle Cloud Storage、以下GCS)と "Data WareHouse"(Google BigQuery)に出力する。
以降では、各コンポーネントの役割とDataflowによるStreaming処理について述べる。
Ramp – RawDataHub
各マイクロサービスのRampのトラフィックはサービス毎にバラバラな上、当然のことながらマイクロサービス自体が増減する。いくらCloud DataflowはGCPのマネージド・サービスだとはいえ、アプリケーションのリリース、監視やworker数の調整などの運用業務もあるので、各サービスごとにパイプラインを構築・運用するのは現実的ではない。逆に、全てのマイクロサービスのログを統一のトピックに投げるようにすると、サービスごとのETL処理や、障害発生時のコントロールが難しくなる。サービス用のデータの受け口としてRampを用意し、そのデータをRawDataHabに集約することで、ある程度の柔軟性を保ちつつ統一的なパイプラインを構築することが可能になる。
RawDataHub – RawDataLake
前述の通りPubsubMessageのpayloadは任意のバイト列であり、JSONやProtocol Buffers、MessagePackといった一般にログ転送で用いられるデータ・フォーマットだけでなく、画像や音声等、バイト列で表現できるデータならなんでも送ることができる。RawDataLakeには、RawDataHubの全payloadをRampのtopic名と処理時間でパーティショニングしながら、Apache Beam のAvroIOでそのままAvroレコードとして出力する(俗に言うmicro batch)*4。このRamp – RawDataHub – RawDataLakeのデータパイプラインにはpayload以外の一切の情報が不要なため、プラットフォームとサービス間のスキーマ連携が不要であり、また暗号化したデータや音声等のバイナリも統一的に扱うことができる。
RawDataHub – StructuredDataLake
RawDataLakeへの出力と異なり、このパイプラインはスキーマ情報を取り扱う。事前にデータ構造が既知であるRampのデータに対してのみ、payloadの byte[] をデシリアライズし、Avroのschemaを動的に生成、そのschemaを用いて構造化したAvroのレコードにシリアライズする。このAvroレコードをRawDataLakeと同様にRampのtopic名と処理時間でパーティショニングしながらGCSに逐次書き込んでいく。StructuredDataLakeのデータは、構造化されている分Rawデータに比べSpark等の処理エンジンで扱いやすく、また機械学習のデータとしても利用しやすいのが特徴だ*5。
RawDataHub – DataWareHouse
StructuredDataLakeへの出力と同様に、事前にデータ構造が既知であるRampのデータに対してのみ、payloadの byte[] をデシリアライズしBigQueryのTableRowオブジェクトに変換、それをこれまたApache Beam のBigQueryIOを用いてBigQueryの所定のテーブルに行単位で書き込んでいく。
このパイプラインでは、当面の課題であったBigQueryへの同期のlatencyの問題が解決されており(ちゃんとした負荷検証はこれからだけど、RampへのMessage投入から10秒程度の遅れの見込み)、メルカリのデータ分析環境改善に貢献できる予感がしてきている*6。
最後に
ということで、より大量のデータを、より効率的に、より柔軟に扱うためのログ収集基盤をGCPに構築しているというお話でした。最後まで読んでいただきありがとうございます。
なお、弊社では大量データと格闘したいエンジニアを引き続き募集しています。興味を持っていただけてた方は是非↓もご覧ください。
Mercari Advent Calendar 2018、明日は @ikkou です。明日もお楽しみに!
脚注等
*1: 例えば下記のような:
- メルカリのデータ分析基盤の紹介〜BigQuery周辺の話〜
- Pascal〜Puree + ngx_lua + Fluentd + BigQueryでつくるメルカリのログ分析基盤〜
- fluent-agent-hydraで省エネログ転送
*2:NorikraでStream処理しているものはSREが運用目的でシステムメトリックスとして利用しているのが主なので、本エントリでは説明を省略する。気になる方はぜひメルカリのデータ分析基盤を。
*3:扱うトラフィックを考えると、ネットワークを跨ぐlatencyやコストが問題になるのは自明だった
*4:正確には、データの処理時間やUUID等必要最小限のメタデータも付与している。でも、payload部はRampに投げ込まれたバイト列そのままだ
*5:Spark等でその手のプログラミングをする場合、ストレージから読み出すほうがずっとコードが書きやすいと個人的には思っている。たとえほとんど同じことをSQLで表現できたとしても。
*6:本格的なプロダクションでの稼働はこれから




