SRE所属の @siroken3 です。最近はもっぱらパートナー会社様とのデータ連携環境構築を主に、時々プロダクションのMySQL環境と分析基盤との連携インフラの構築が多いです。
本記事は、メルカリに出品された過去すべての商品をBigQueryへ同期するにあたって取り組んだ時のお話です。
背景
当社では分析目的などでBigQueryを以前から使用しており、プロダクションのMySQLからBigQueryへデータを同期して分析に活用してきました。特に商品を表すテーブルは重要です。
しかし、後述する課題によりBigQueryにアップロードすることができなかったため、分析用のMySQLDBのスレーブとBigQueryを併用せざるを得ませんでした。とはいえ不便なので以前からBigQueryのみで商品テーブルも分析対象としたい要望がありました。
課題
メルカリでは販売済み商品を物理削除していないため、サービス開始以来全てのデータが格納されています。プロダクション環境で使用しているMySQLの商品テーブルはInnoDBのBarracudaフォーマットで数百GByteオーダー、レコード数にして数億件です。
BigQueryにはプライマリキーやユニークキーによる制約がかけられないことに注意する必要があります。
さらに、商品の説明が更新された / 価格を変更した/ 発送された などのイベントにより商品テーブルは更新されます。同期時にはこれらの変化も含めてBigQueryのレコードが反映させる必要があります。
しかし、BigQueryは更新について制限があり*1、テーブル毎に1日に1,000回までしか更新できません。
したがって、素朴にBigQueryに同期しようとすると全レコードを一度に同期する必要があります。embulk *2のようなETLツール使う前提としても数日など実用的な時間で同期できないので工夫が必要です。
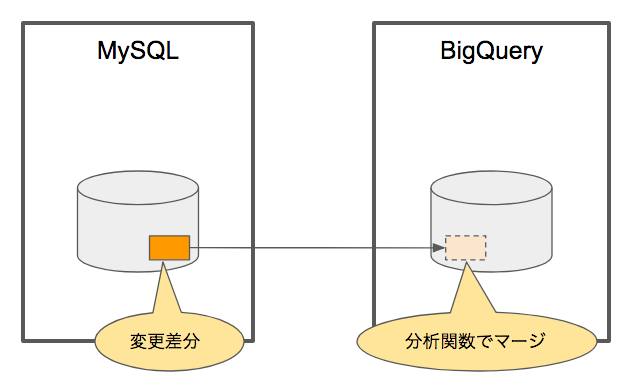
採用した方法
Shiozaki さんによるBigQueryへの差分同期のアイデア*3を見つけこれをヒントに実現することができました。
基本的な流れは以下のとおりです。

- 同期させたい期間のレコードを定期的に検索
- その結果をBigQueryの作業用テーブルへ上書き
- 作業用テーブルとアップロード先のテーブルをマージ。マージにはBigQueryの分析関数*4を使用
具体的にはMySQLからBigQueryへの同期用ETLツールは embulk + embulk-input-mysql plugin *5 + embulk-output-bigquery plugin *6、 定期実行およびエラー時のリトライをさせるためにワークフローエンジンの digdag *7を採用しました。
既存商品テーブルの同期
定期的に差分をアップロードするのに先立ち、現時点すべての商品テーブルのデータを一旦BigQueryへアップロードする必要があります。
対象となるデータが数百GBありますので数日間バッチを回して失敗、な調子ではTry&Errorがつらすぎるので一度にアップロードせず複数回に分けてアップロードすることにしました。
embulkにはincremental:指定があり簡単に入力を分割して複数回に分けてアップロードする処理する仕組みがあり、それを使おうとしましたが、BigQueryで扱いたい商品テーブルは単一ではなく複数テーブルのJOINした結果です。 JOINするには embulk の configurationでquery: を使用する必要があり、これは残念ながらincremental: と排他だった*8ので断念しました。
そこで複数回に分割する機能はdigdag で提供されている for_each> タグで実現することにしました。商品データの更新日時を表すupdatedを適切な期間で区切り、embulkへパラメータとして区切られた期間の開始日時、終了日時として指定する方法を取りました。同期するためのembulk configurationの一部を抜粋します。
# items-bulk.liquid
in:
type: mysql
host: {{ env.MYSQL_HOST }}
port: 3306
user: {{ env.MYSQL_USER }}
password: {{ env.MYSQL_PASS }}
database: {{ env.MYSQL_DB }}
query: |
SELECT
id,
d.description,
(略)
FROM
items i JOIN item_description d ON i.id = d.item_id
WHERE
'{{ env.S }}' <= updated AND updated < '{{ env.E }}'
out:
type: bigquery
mode: replace
table: tmp_items
(後略)
また、digdag の configuration も下記に示します。configuration for_each> において periods という名前のオブジェクトを使いました。サービス開始当初などデータ量が少ないと予測される期間は長めにし、直近の日付は期間を短めにしています。これでも大きいので、1ループが数時間程度で終わるように、またembulkがOOMしないようにさらに分割を行いました。
すべての分割を日付で指定するのは可読性に欠けるので、更にfor_range>の sliceオプションにより50分割し一度に同期する量を調整しました。しかし、読者の皆様のユースケースで試される際には digdag には分割数のデフォルトの上限(1000)がある
*9のでご注意ください。
timezone: Asia/Tokyo
+sync_all:
for_each>:
periods:
# サービス開始当初はbulk upload対象期間長め(半年)
- from: '2013-06-24 00:00:00'
to: '2014-01-01 00:00:00'
- from: '2014-01-01 00:00:00'
to: '2014-06-01 00:00:00'
(略)
# 最近分は短め
- from: '2018-03-01 00:00:00'
to: '2018-05-15 00:00:00'
_do:
+sync:
for_range>:
from: ${parseInt(moment(periods.from).format('X'))}
to: ${parseInt(moment(periods.to).format('X'))}
slice: 50 # 期間中を50分割してembulkで処理
_do:
+sync:
_export:
s: ${moment.unix(range.from).format('YYYY-MM-DD HH:mm:ss')}
e: ${moment.unix(range.to).format('YYYY-MM-DD HH:mm:ss')}
_retry: 5
sh>: S="${s}" E="${e}" embulk run items-bulk.yml.liquid -r /var/tmp/items-bulk-resume.yml
+merge:
_retry: 3
# 他のbq jobに迷惑をかけないように batchモード
sh>: bq query --batch --max_rows 1 --replace --allow_large_results --use_legacy_sql=false --destination_table OUR_BQ_DATASET.items "$(cat ./merge-items.sql)"
上記 digdag ワークフロー定義ファイルの最終行がアップロードしたBigQuery上の同期用一時テーブルと対象のテーブルのマージ用SQL実行と結果を対象BigQueryテーブル items へ上書きするタスクです。
sh>: bq query --batch --max_rows 1 --replace --allow_large_results --use_legacy_sql=false --destination_table OUR_BQ_DATASET.items "$(cat ./merge-items.sql)"
マージ用SQL merge-items.sql の実行結果が bq --destination_tableによりitems テーブルに上書きされます。
SELECT * EXCEPT(rn) FROM ( SELECT *, row_number() over (PARTITION BY id ORDER BY updated DESC) AS rn FROM ( SELECT * FROM OUR_BQ_DATASET.tmp_items UNION ALL SELECT * FROM OUR_BQ_DATASET.items ) ) WHERE rn = 1
BigQueryの分析関数の row_number() と PARTITION BY句を使用しています。これらの分析関数を使ってどのようにマージが行われるのかについて概念的な図で説明します。

- (1) BigQuery上に対象テーブルのitems と 一時テーブルの tmp_items があります
- (2) UNION ALL で全行の和集合を構成します。
- (3) row_number() over (PARTITION BY id ORDER BY updated DESC) によって itemsのid毎に更新日の降順でグループ分けします。(右下が拡大図です)
- (4) row_number = rd が 1 のものだけをSELECTします。その際に作業用カラムrnをEXCEPT(rn)によって除去します
この方法によりBigQueryで重複レコードを登録してしまう問題を回避することができるようになりました。これで同じ期間を対象にした同期タスクを2回実行してしまっても重複レコードが作られることなく意図したレコードのみ同期されるのでリカバリが楽になります。
差分データの同期
すでにここまでの仕組みで差分同期する仕組みができあがっており、あとはMySQLのクエリ条件の違いと運用上の仕掛けです。
クエリ条件の違いは「定期実行するdigdag workflowの前回のタスク実行時間以降すべて」になります。
ただし、本稿で説明したMySQLサーバはプロダクションデータベースのスレーブとして運用しており、レプリケーション遅延の可能性があります。そこでバッファとして1時間を設けて同期対象の差分の範囲を過去に遡らせて期間を重複させています。
このような運用が可能なのも分析関数によって最新のレコードのみをマージできる仕組みがあればこそ、です。
また digdag は簡単に plugin を仕込めるようになっており、 指定した回数リトライしてもエラーに終わった場合は Slackに通知する*10こともできます。
timezone: Asia/Tokyo
schedule:
minutes_interval>: 30 # 30 分ごとに実行
skip_on_overtime: true # 前回のワークフローの実行時間が30分を超えて実行中のときはSKIPする
_export:
plugin: # 通知プラグイン
repositories:
- https://jitpack.io
dependencies:
- com.github.szyn:digdag-slack:0.1.3
workflow_name: upload-to-bq-items
!include : credentials/slack_webhook.dig
+sync:
+load:
_export:
# 最終(SKIPしていない)実行日時より1時間前に遡って同期対象にする
S: ${moment(last_executed_session_time).add(-1, 'hours').format('YYYY-MM-DD HH:mm:ss')}
_retry: 5
sh>: embulk run ./items.yml.liquid -r /var/tmp/items-resume.yml
+merge:
_retry: 3
sh>: bq query --batch --max_rows 1 --replace --allow_large_results --use_legacy_sql=false --destination_table OUR_BQ_DATASET.items "$(cat ./merge-items.sql)"
_error:
slack>: error.yml
現在のところおおよそ30分以内には商品テーブルの同期ができている状況です。とはいえBigQueryへの同期が失敗することがあったり、出品数が増えて30分で収まらない可能性もあるので調整する必要もありそうです。
今後
今回BigQueryへの同期の仕組みをembulkとdigdagの組み合わせで実現しました。社内でデータ基盤を整える動きもあり、もしかすると別のETLツールが選択されるかもしれません。
しかしBigQueryに対して大量のデータをアップロードするためには今回の分析関数を使ったマージは有効でした。BigQueryへの同期を構築する場合には欠かせない手法になりそうです。
まとめ/所感
- 巨大なテーブルもBigQueryへアップロードして使えるようになった
- 分析関数の利用によって同期が”コケ”てもにも安心して自動実行できるようになった
- digdag は慣れが必要だが、プラグインの仕組みは便利、定期実行モードでのリトライの仕組みが優秀だと思う
最後になりましたがメルカリではデータ分析基盤の開発したい方を募集中です。もっといい方法で作ってやりましょうという皆様、ご応募お待ちしております。
*3:MySQLからBigQueryの同期を差分更新にしたら4倍早くなった話 (Takehiro Shiozakiさん)
speakerdeck.com
*4:https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators#analytic-functions
*5:https://github.com/embulk/embulk-input-jdbc/tree/master/embulk-input-mysql
*6:https://github.com/embulk/embulk-output-bigquery
*8:Ver. 0.8.33にて確認
*9:ちなみにこの上限の回避策もありますhttps://github.com/treasure-data/digdag/issues/508

