こちらは Mercari Advent Calendar 2017 の23日目の記事になります。
はじめに
メルカリで機械学習エンジニアをやっている kumon です。
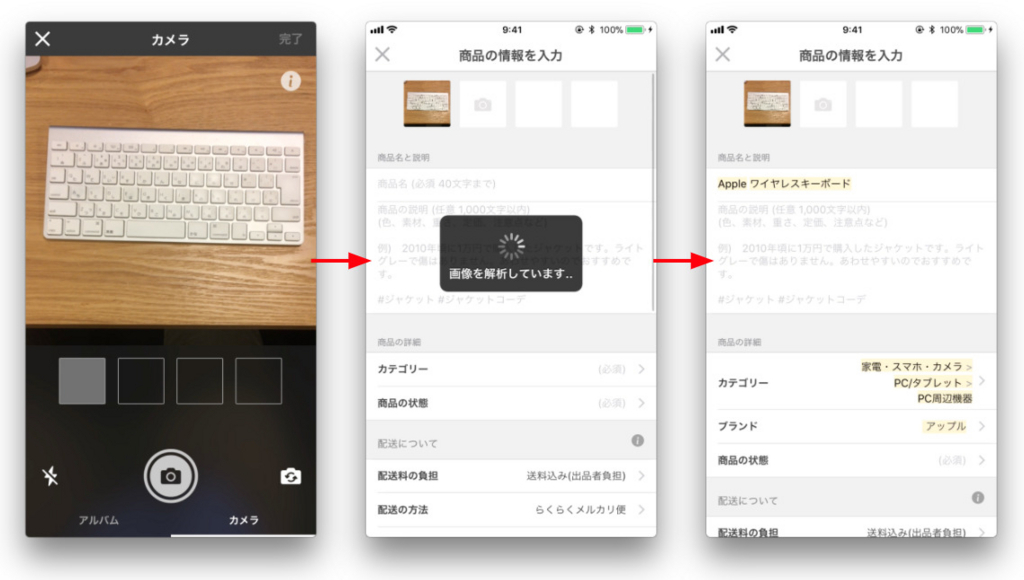
今年の10月に、出品時に画像認識によって、商品名・カテゴリー・ブランドの項目を自動的に埋めるという機能をリリースしました。
もちろん認識結果が得られない場合や、間違えることもありますが、作った本人も驚くような正しい結果を出力してくれることもよくあります。

この認識エンジンはまだまだ改善中ではありますが、画像を使った別の機能についても検討しておりまして、その一つが画像による商品検索です。
画像で画像を検索するためには、一般的に、画像をなんらかの方法でベクトル表現にして、検索対象の画像のベクトル集合から、クエリ画像のベクトルとの類似度がもっとも高いものを類似画像として抽出します。
しばらくはSIFTやHoGといった特徴表現が利用されていましたが、
最近では、深層特徴(Deep Features)と呼ばれる特徴表現が使われることが多いと思います。
深層特徴は、特徴抽出の手法というより、Deep Neural Networks (DNN)の中間層の出力を画像の特徴ベクトルとして使うものです。
DNNでは多くの中間層があるので、どの層を使ったらどういう画像検索結果が得られるのかを見てみようと思います。
画像特徴
出品時の画像認識では、Inception-v3というConvolutional Neural Networks (CNN)の一種をベースとしてモデルを構築しました。
画像から、メルカリのカテゴリー・ブランドを推定できるように、実際にメルカリに出品されている画像データを使って学習させています。
その学習済みモデルを使って、画像による類似商品検索の挙動について確かめてみようと思います。

上図が、Inception-v3モデルですが、ネットワークに分岐と結合が含まれた特徴的な構造をしています。各々の分岐から結合までがInception Moduleと呼ばれています。
ここでは、以下の3種類について試してみます。
A: 最初のInception Moduleの後
- 35 x 35 x 256D の出力を Global Average Poolingで256Dの特徴ベクトルに変換
B: 8番目のInception Moduleの後 (Auxiliary Classifierに分岐している部分)
- 17 x 17 x 768D の出力を Global Average Poolingで768Dの特徴ベクトルに変換
C: 最後のInception Moduleの後
- 8 x 8 x 2048D の出力を Global Average Poolingで2048Dの特徴ベクトルに変換
17 x 17 や 35 x 35 の入力に対してのGlobal Average Poolingはかなり雑ですが、とりあえずこれで挙動を確認してみます。
ちなみに、ここでのGlobal Average Poolingが何者かわからなくても、雑に次元削減していると考えていただいて大丈夫です。
入力に近い層では模様などの視覚的な特徴が得られ、出力に近い層ではよりモデルの学習時の問題設定に応じた意味的な特徴が得られると言われています。
今回のモデルの場合、カテゴリーとブランドを推定するように学習されたモデルですので、出力に近い層では視覚的な特徴よりも、同一カテゴリー・同一ブランドの画像が近くなるような特徴ベクトルが得られることが期待できます。
データ
検証に用いるデータとして、ある期間に出品されたメルカリの商品からランダムに選択した100万画像を用意し、その全てを上記Inception-v3モデルに通して、A・B・Cの特徴ベクトルを抽出しました。

類似画像検索
ベクトル同士の類似度の尺度としてコサイン類似度を用い、A・B・Cのそれぞれの特徴ベクトルごとに上位10位を類似画像を収集します。
Example 1

クエリ画像は赤いニットです。
Aの特徴ベクトルを使った場合、見た目はなんとなく似ていますが、スカートやTシャツなどニット以外のカテゴリーの画像も上位に来ています。BとCでは、ニットが並んでいることがわかりますが、特にCでは類似画像という表現より類似商品といった表現の方が適切な結果が得られています。
Example 2

クエリ画像はボーダー柄のニットです。
Cの結果に、白の無地のものが入っているように見えますが、実はこれもボーダー柄なので、間違いではありません。
Aではボーダー柄ではあるものの、ニット以外が多く含まれています。
Example 3

紺のダウンベストですね。
Aではダウンっぽい質感の商品を抽出できています。
B・Cでは正しくダウンベストが得られていますが、特にCでは色に関する感度が薄れていることがわかります。
Example 4

クエリ画像はCOACHのショルダーバッグです。
Aの結果でも、半数はCOACHのバッグを見つけられています。B・Cでは、全てCOACHのバッグが得られていて、特にCでは、ショルダーバッグだけが抽出されています。
Example 5

クエリ画像はLOUIS VUITTONのダミエ柄のショルダーバッグです。
Aでは全てダミエ柄のバッグが得られていますが、カテゴリーは様々で、ビジネスバッグやトートバッグが並んでいます。
B・Cでは、ショルダーバッグが多く含まれるようになりますが、ダミエ柄ではなくモノグラム柄のバッグも目立ってきます。
これは、特徴表現の精度が落ちたというより、カテゴリーとブランドを推定するために学習したモデルを利用しているため、柄の違いがあっても同一のブランドと判断できるような特徴表現が得られていると言えます。
Example 6

クエリ画像はNikeのニット帽です。
Aではニット帽も抽出できてはいますが、ボーダー柄に見える商品が得られていることがわかります。この層の特徴を直接使うのは難しそうです。
B・Cでは、ニット帽のみが得られていて、Cの方がNikeのニット帽をより多く抽出できていることがわかります。
Example 7

クエリ画像は花柄のショルダーバッグで、背景にも模様が含まれます。
Aでは、全体的なごちゃごちゃした感じの見た目の画像が得られている反面、B・Cでは、複雑な背景にも負けず、主に柄物のショルダーバッグが並んでいます。
もし、Aでは、花柄が含まれる画像が得られているのであれば、BやCにAの特徴ベクトルを混ぜても面白いかなと思いましたが、そのような挙動は得られませんでした。
もしかしたら、雑に次元削減をしていることも影響しているかもしれません。
まとめ
出品時に利用している画像認識モデルの3つの中間層を利用して、商品画像検索を行ってみました。
使う層によって得られる結果が異なるため、検索機能への要求スペックに応じて使い分けるのがよさそうに見えます。
また、商品の柄への感度が高い特徴ベクトルが得られれば、上記、BやCの層の特徴ベクトルと単純に結合して利用するのもよさそうです。
画像をクエリとした検索では、テキストを利用した検索よりも処理負荷やデータサイズが大きいことに加え、
1日に100万点を超える出品をどう扱うかという、画像の特徴表現以外の課題もいろいろあります。
上述のものとは別の予備実験では、5000万画像を対象に、4コアのCPUサーバーを使った場合、Cの層からの特徴ベクトル抽出に100ms、類似ベクトル抽出に100msほど要しました。
これでは、大量の検索リクエストを捌くのに多くのサーバーが必要となってしまいます。
もちろん、近似計算によって処理時間を大幅に短縮することは可能ですが、検索精度とのトレードオフとなります。
そして、メルカリの商品点数から考えると検索対象が5000万件ではもの足りませんので、GPUサーバーは必須だと思っています。
十分にGPUの恩恵を受けられるように、複数の検索リクエストをまとめて処理するような実装も必要となります。
その他の課題もまだまだありますが、ひとつずつ楽しんで解決していければと思います。
機械学習/自然言語処理エンジニアを積極的に募集しておりますので、ご興味ありましたらご連絡いただければと思います。
採用情報: Software Engineer (機械学習/自然言語処理) | 株式会社メルカリ
明日24日は jollyjoester さんです!お楽しみに!




