Mercari Advent Calendar 2017 の15日目は id:koemu こと斎藤が担当します。
こんにちは。私は、サーバサイドのソフトウェアエンジニアとして、過去はメルカリ 米国版の開発、現在は日本版の開発に携わっています。
サーバサイドのソフトウェアエンジニアにとって、サービスの成長に伴うサーバの負荷との戦いは切っても切れない存在であると、私は考えています。初めから想定できる問題もあれば、サービスが成長して初めて明るみになる問題もあります。成長痛と言ってもいいかもしれません。
今日は、私が当社で働いていて携わった、サーバサイドのプログラムのパフォーマンスに関わる事象について、「Slave DBへの要求を
memcached に向けていく」「PHP からサブシステムを呼び出そうとするときの工夫」そして「array_merge()の失敗談」の3点をピックアップして紹介します。
Slave DBへの要求を memcached に向けていく
- 問題: 検索時における商品情報参照時のレイテンシの改善
- 解決策: 頻繁に参照される情報を精査しそれらをmemcachedへ保存
- 結果: レイテンシの改善, Slave DBへのリクエスト・トラフィックの減少
レイテンシ改善は、ネットワーク全体の負荷を軽減するばかりでなく、お客様の体験を改善できるものです。サーバを増やすだけでは、1リクエストあたりのレイテンシは改善できません1。そこで、プログラムの改善が必要になります。
当社では、非常に多くのアクセスを受け止める部分については、既に memcached によるキャッシュを使ってレイテンシの改善は行っていました。その上で、問題になり始めていた箇所がありました。検索結果と閲覧履歴です。検索のインデックスは Apache Solr に、閲覧履歴は出品情報が管理されたものとは別のDBにそれぞれ保存されているのですが、実際にお客様に情報を提示する段階になりますと、出品情報が管理されているDBにある付帯情報をマージしてお客様に返す必要がある構造になっています。これを実現するために、検索の度に結果をマージするためのIN句を用いたクエリが実行されます。簡単な擬似コードをコード1に示します。
- コード1: 出品情報をマージするためにDBからまとめて取得する
<?php function mergeResult(string $query): array { $item_id_list = SearchIndexService::fetchResult($query); $result = DB::rows( 'SELECT name, seller, attribute1, ..., attributeN FROM items WHERE item_id IN :item_id', ['item_id' => $item_id_list] ); return $result; }
この方法は、New Relicによる測定の結果、SQLのクエリ実行時間が多分を占めていることがわかりました。そこで、 memcached へを用いてパフォーマンスを改善することにしました。しかし、商品情報はそれなりに多くの属性を持っており、単純にすべてキャッシュさせると、今度はアプリケーションサーバ 〜 memcached サーバの間の通信量の負担の問題が出てしまいます。例えば、以下の3つです。
- どんな項目に絞って保存するか
- どういった構造でデータを保存するか
- キャッシュできている商品情報とそうでない商品情報をどう切り分けるかの判断が必要
1は、ある1つのエンドポイントだけでなくある程度汎用性を見越しつつ、表示に必要な属性を絞って保存することで解決しました。
2は、当初PHPのオブジェクトをキャッシュしていたのですが、圧縮しても2転送量が増えてしまう症状が発生しました。そこで、シンプルなテキストベースの配列として保存し、保存時・取得時にその順序を担保してデータを利用できるようにしました。なお、1で想定していた構造が変わる場合は、キャッシュし直しになりますが、キーのプリフィックスを変えることで対応できるように施してもいます。なお、シンプルなテキストベースの配列ですと、他の言語でも読み書き可能になるメリットもあります。
3は、当社にはプライマリキーとなる情報を基に、キャッシュ済みなら memcached から、そうでないものはDBから取得した上で memcached にも保存しておく処理をまとめて行うサービスクラスが既にあり、解決させることができました。
以上により、期待通りレイテンシは改善することができました。また、参照先としてアクセスしていたSlave DBへのリクエスト数も大きく抑えることができ、システム全体で受け止められるリクエスト数の余裕も出ました。
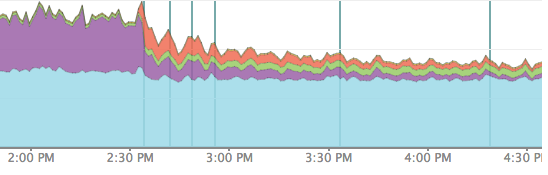
図1が、デプロイ前後の New Relic のチャートの推移です。水色がPHPの処理、紫色がDBへの問い合わせ、オレンジが memcached への書き込み時間を示しています。一定の効果を示しているのが、チャートからも読み取っていただけるかと思います。
- 図1: 2:30pm 過ぎにデプロイした後はDBへの問い合わせが減らせている様子

PHP からサブシステムを呼び出そうとするときの工夫
- 問題: サブシステム側が刺さったときPHPの処理待ちが増えすぎないようにする
- 解決策: タイムアウトをできる限り短くする, サブシステム側もタイムアウトに強い設計にする
- 結果: トラブル時におけるPHP側での待ち時間の減少
ご存知の方もいると思いますが、当社のサーバサイドのコードはPHPとGoで書かれています。
今回は、ページビューを数えるサブシステムと、メインのPHPのコードの間で施したタイムアウトの設定についてです。
JPでは、現在サーバサイドで表に立って動いているのがPHPのプログラムです3。PHPはサーバサイドで実行する際、起動プロセス数=同時に受け止められるリクエスト数、となります。ここで問題になるのが、PHPが呼び出す先にあるサブシステムの処理が滞った時(刺さった時)です。これはサブシステムが即時エラーを返すより問題です。なぜなら、刺さっている間、PHPのプロセスはその接続のために拘束されてしまい、他のリクエストを受け付けなくなります。そして、これが折り重なるとお客様に御迷惑をおかけする可能性があります。
そこで、今回はPHP側のHTTP通信タイムアウトを 10msec に設定し、万一刺さった場合でも結果として問題とならないようにしました。また、 Go で書かれているサブシステムのプログラムは、リクエストを受け取ったら即時に処理がキューイングされ、レスポンスが返ってこなかった場合でもカウントアップの処理は正常に進んでいる状況になっています。
なぜ 10msec かというと、正常時の処理時間を計測した結果、この値が問題ないと判断できたためです。実際にそのように設定した後も、特に問題は出ておりません。
なお、PHPでGuzzleを使った際にタイムアウトを1秒未満にする方法は、別にエントリを書いているのでもしよろしければご覧ください。
GuzzleでTimeoutを1秒未満に設定する on @Qiita
array_merge() の失敗談
- 問題:
array_merge()呼び出し時、マージ元の配列が長いと遅い。 - 解決策: PHP 5.6→7.1へバージョンアップ
- 結果: 劇的に改善
どちらかと言うと失敗談です。
当社のDBは、用途により垂直分割を行っています。垂直分割の詳細は以下のエントリをご覧ください。
垂直分割された同士のDBのテーブルを参照する際、プログラム側でマージしなければなりません。その際、あるバッチプログラムで以下のようなコードを書いていました。擬似コードをコード2に示します。
- コード2: 配列長が長くなると
array_merge()のパフォーマンスが劣化していく例
<?php $result = []; $db1_result = DB1::rows('SELECT hoge, fuga FROM foo WHERE condition = 1'); $chunked_result = array_chunk($db1_result, 100); foreach ($chunked_result as $chunk) { $db2_result = DB2::rows( 'SELECT hoge, fuga FROM bar WHERE condition IN :list', ['list' => $chunk] ); $result = array_merge($result, $db2_result); } // 処理が続く
このコードですが、 $result の配列長が長くなればなるほど、 array_merge() の実行速度が遅くなります。これは、 PHP 5.x系(当時 PHP 5.6)ですと顕著でした。なぜわかったかというと、 SELECT hoge, fuga FROM bar WHERE condition IN :list の実行間隔がどんどん長引いていることが観測されていたためです。詳細は「付録」の節で示します。
このケースですが、問題が発覚したのと同じ時期、当初計画していたPHP 7.1へのバージョンアップが行われ、処理系自体のパフォーマンス改善がうまく効いて運良く解決してしまいました。
ちなみに、 array_merge() を使わずに、配列を1要素ずつ追加するようコードを書けば $result の配列長が長くなっても処理速度が著しく落ちることはありません。擬似コードをコード3に示します。
- コード3:
array_merge()を使わずに配列を結合する
<?php $result = []; $db1_result = DB1::rows('SELECT hoge, fuga FROM foo WHERE condition = 1'); $chunked_result = array_chunk($db1_result, 100); foreach ($chunked_result as $chunk) { $db2_result = DB2::rows( 'SELECT hoge, fuga FROM bar WHERE condition IN :list', ['list' => $chunk] ); foreach ($db2_result as $db2_row) { $result[] = $db2_row; } } // 処理が続く
テストコードやQAではわかりにくい問題ですが、逆にこういったことは起きてしまってもすぐに確認でき、そして対処できることもまた大切だと再確認した出来事でした。
まとめ
ここまで、当社のサーバサイドシステムのパフォーマンスに関わる事象について、「Slave DBへの要求を memcached に向けていく」「PHP からサブシステムを呼び出そうとするときの工夫」そして「array_merge()の失敗談」の3点に分けて紹介しました。書いているプログラミング言語の知識ばかりでなく、データベースやネットワークの知識を総動員して、ことにあたるのを知って頂けたと思います。
当社のサーバサイドのパフォーマンス改善は、まずはSREが日々の運用を通じて問題を確認し、SRE・ソフトウェアエンジニアが互いに協力して対応にあたっています。いうなれば、日々がリアルISUCONです。「良い負荷がかかる」機会に恵まれるのはそうなく、ソフトウェアエンジニアリング能力を鍛える良い機会となっています。そして、ここまで大きい規模になると自分自身だけの力で到底解決はできません。ソフトウェアエンジニア同士、そしてSREのみなさんの知恵と知識を借りて、成し遂げています。
そして、チューニングしたコードをリリースし、各種メトリックを見届けている中でパフォーマンスが改善したのを確認し、「ふふふっ」と笑みをこぼすのが、私の仕事のやりがいの一つとなっています。
16日目は、id:sota1235 さんです。それでは皆様、ごきげんよう。
付録: array_merge() のパフォーマンスについて
array_merge のパフォーマンスを調査するため、以下のコードを作成し、 同じ計算機にある PHP 5.6 及び 7.1 の処理系を通じて実行しました。そのうえで、 PHP 7.1 にてループをネストして Join するともっともパフォーマンスが良いことを示します。
まず、 array_merge() のパフォーマンスを調査するために実行したコードをコード4に示します。
- コード4:
array_merge()でマージする配列長が変わる毎によるパフォーマンス劣化を計測する
<?php ini_set('memory_limit', '64M'); $source = array_fill(0, 100000, 1); $chunk = array_chunk($source, 100); $start_msec = microtime(true); $last_msec = $start_msec; $merged = []; $i = 0; foreach ($chunk as $list) { $i++; $merged = array_merge($merged, $list); if ($i % 100 === 0) { printf("%fn", microtime(true) - $last_msec); $last_msec = microtime(true); } } printf("%fn", microtime(true) - $start_msec); printf("%sn", count($merged) === 100000 ? 'OK' : 'NG');
その結果、図2のとおり、 array_merge() でマージする際、引数に与えた配列長が長くなるほど、線形でパフォーマンスが劣化していくことがわかります。 PHP 7.1 では処理速度自体は5〜6倍良くなりますが、線形でパフォーマンスが劣化することに変わりはありません。これらの結果は、 array_merge() の引数の順序を変えても変わらないことを確認しています。
- 図2:
array_merge()の処理計測結果 (単位:秒)

最後に、 PHP 5.6 と 7.1 、および array_merge() とネストで Join した場合、それぞれの計測結果を示します。手元の計算機で、3回計測した際の平均値を示します。
| 単位:秒 | array_merge() : コード5 |
Join : コード6 |
|---|---|---|
| PHP 5.6 | 3.152 | 0.016 |
| PHP 7.1 | 0.508 | 0.006 |
- コード5:
array_merge()版
<?php ini_set('memory_limit', '64M'); $source = array_fill(0, 100000, 1); $chunk = array_chunk($source, 100); $start_msec = microtime(true); $merged = []; foreach ($chunk as $list) { $merged = array_merge($merged, $list); } $end_msec = microtime(true); $elapsed_time = $end_msec - $start_msec; printf("%fn", $elapsed_time); printf("%sn", count($merged) === 100000 ? 'OK' : 'NG');
- コード6: Join 版
<?php ini_set('memory_limit', '64M'); $source = array_fill(0, 100000, 1); $chunk = array_chunk($source, 100); $start_msec = microtime(true); $merged = []; foreach ($chunk as $list) { foreach ($list as $record) { $merged[] = $record; } } $end_msec = microtime(true); $elapsed_time = $end_msec - $start_msec; printf("%fn", $elapsed_time); printf("%sn", count($merged) === 100000 ? 'OK' : 'NG');
以上から、配列の結合処理の高速化に際し、ネストして Join したほうがパフォーマンスが高いこと、そして PHP 5.6 より 7.1 が高速に処理できることがわかりました。
-
SRE大全 メルカリ編 後半 #hbstudy 75 / SRE Taizen Mercari 2 hbstudy#75 // Speaker Deck pp.22↩
-
Memcached::OPT_COMPRESSION: PHP: 定義済み定数 – Manual↩ -
USは違うアーキテクチャで動いています: US版Mercariのリニューアルと今後 (サーバサイド) – Mercari Engineering Blog↩



