こんにちは、SRE の @masartzです。
今回は最近取り組んだ、メルカリの主要データベースの容量削減のお話をしようと思います。
TL;DR
主要データベースの容量を20%以上削減しました
どういう状況だったか? 何をしたか?
メルカリでは2017年11月現在、出品数は1日100万件を超えています。
なので、単純に日々多くのデータが増えていっています。 そのためデータベースのスケーリングは常に検討し、取り組まなければならない課題です。
今回扱ったデータベースはいくつかあるデータベースの中で商品テーブルを持つ、メルカリの主要データベースになります。
増え続けるデータに対応するための、テーブル分割を変則的な形で対応したのでその過程を紹介します。
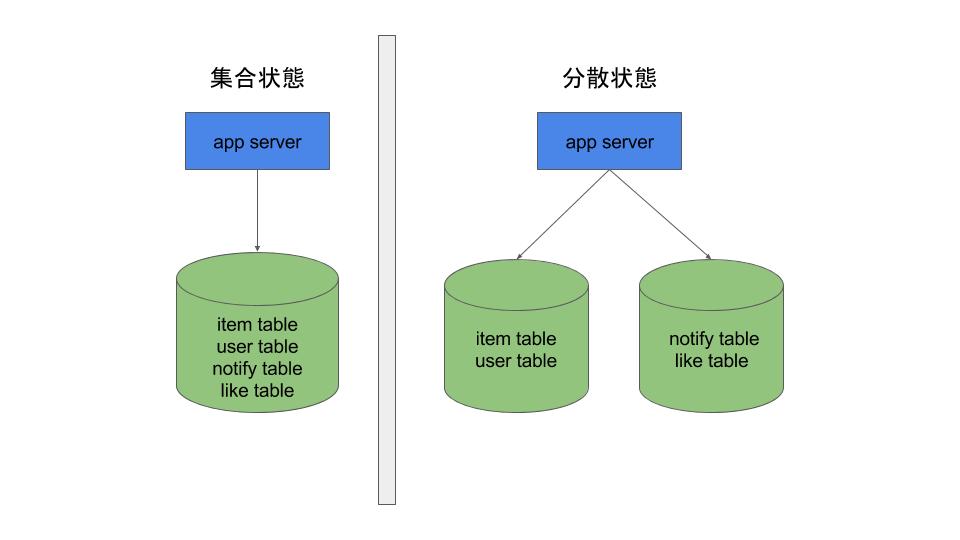
前提:データベース分割方法
メルカリのデータベースには 会員情報や商品情報など、基本要素となるデータから、通知やお知らせメッセージなど付加的な機能まで多岐に渡る情報をデータベースに保存しています。
このため、テーブル単位で物理的なデータベースを住み分ける、いわゆる垂直分散方式を導入しています。

今回の事例
上記の垂直分散は既にかなりのテーブルに対して適応されており、現在のメルカリには複数(> 2)のデータベースにデータが住み分けられて保存されています。
なかでも最も初期からあるデータベースには商品情報や顧客情報をはじめ主要なテーブルが集まっています。
その容量問題に対応するため、まずはデータベースの状況の分析からはじめました。
- データベースの中で、容量が多いのは商品テーブル
- 商品テーブルの割合がダントツで、データベース全体の容量の30%を占める
- 容量が上位の他のテーブルでも1つ1つは5〜10% 程度の割合
- その他多くの小容量テーブルが存在する
というロングテールな占有割合となっていました。
この状況において、小容量のテーブルを他のデータベースに移行したところで、容量の伸び率からすれば焼け石に水です。
割合が最も多い商品テーブルを分割対象として移行する、というのが最初に検討したアプローチでした。
しかし、ここでもう一つ問題がありました。
商品テーブルは他のテーブルとトランザクションを貼りつつ更新処理を行う、という処理が複数箇所に存在していました。
CtoCサービスの特性上、商品が購入されたので、ステータスをupdateしつつ、取引用情報を作成する など商品情報と他の情報をセットで扱うケースは多く、それがサービスのキモでもあります。
通常、分散のためにはテーブルが論理的に独立していることが前提です。例えば、 JOIN したクエリは発行できないので、そのようなコードがある場合には事前に改修が必要です。
商品テーブルとのトランザクションを処理を止める、というのはサービスに大きく影響があるため、現実的ではありませんでした。
このため、商品テーブルを移行する、という策は却下となりました。
変形的な垂直分散
次に商品テーブルの容量が大きい理由をブレイクダウンしてみました。以下商品テーブルの一部抜粋イメージです。
CREATE TABLE IF NOT EXISTS item ( id BIGINT UNSIGNED NOT NULL, name VARCHAR(255) NOT NULL, price INT UNSIGNED NOT NULL, description TEXT NOT NULL, ...
上記はテーブル定義の一部ですが、 description つまり商品説明のカラムがTEXT型で最大でした。
これを受け、 description という部分情報のみを持つ別テーブル(item_description)を別データベースに作成し、カラム単位による分割の変形方式で移行することにしました。
description カラムだけでも、商品テーブルが占める量(データベース全体の1/3)のかなりの割合を移せる見込みがあったためです。スキーマは以下のようなイメージです。
CREATE TABLE IF NOT EXISTS item_description ( id BIGINT UNSIGNED NOT NULL, description TEXT NOT NULL )
また、 商品説明の更新は他のテーブルとのトランザクションで起こる事はありません。
具体的には購入されたからといって、商品説明に何か追記される、というような仕様はありません。
あくまでユーザーアクション(つまり商品情報の編集)によってのみ更新されるため、トランザクション問題もクリアできました。

対応手順
今回の移行作業は一朝一夕では実現できず、いくつかの段階が必要になります。
- 新テーブル(item_description)を用意し、新旧両方で二重書き込みを開始するようアプリケーションコードを改修する
- 旧テーブルの既存のdescriptionデータをバッチ処理で新テーブルへコピーする
- アプリケーションコードの参照処理を旧から新に切り替える
- アプリケーションコードの旧テーブルへの書き込みを停止する
1と2に関しては、1のためのコード改修、2のバッチ開発は特に難しいことはありません。
それよりも事前に整えておくべき周辺作業のほうが重要です。
手順1,2の段階
商品テーブルへの書き込み箇所を限定・集約する
2が終わった段階のゴールは、新旧のテーブル(のdescription情報)が完全に同期していることです。
このためには、既存処理で 商品テーブルへ書き込みしているところに追加処理を入れる必要 があります。
- サービスの中で書き込み処理が散在している
- サービスが複数存在していて、それぞれが直接データベースにアクセスしている
などの場合、その分だけ対応しなければなりません。
方法としては、都度対応よりも限定あるいは集約し、影響範囲を狭めメンテナンス性を上げることが重要です。
今回は社内のCS向け管理画面サービスのコードからもデータベースへの書き込み処理がありました。
この処理は実際のところデッドコードであったため削除する事で処理を集約させました。
ここまで完了して、新旧テーブルから同時にSELECTし内容を比較するチェックバッチを実行し、
完全に同期している事を確認できて手順2のゴールに到達です。
手順3の段階
ここが最もコストと時間がかかった段階になります。
今回の対応策を行う場合、アプリケーション側ではテーブルの分割を隠蔽するよう工夫するべきです。
具体的には下記のようなmodelのインターフェースがあれば、そのまま保つということです。
<?php // Write時 Item::create($input_param); --- // Read時 $item = Item::get($item_id); $item->getDescription();
このために、分割されたテーブルをModel内部でのみ意識する(擬似コードですが)以下のようなイメージです。
<?php class Item { // 内部的に2つのテーブル(item, item_description)にinsertする public static function create($param) { $description_param = [ 'id' => $param['id'], 'description' => $param['description'] ]; DB::insert('item', $param); DB::insert('item_description', $description_param); } // 内部的に2つのテーブルからSELECTする public static function get($item_id) { $row = DB::select_row('item', $item_id); $row['description'] = DB::select_row_column('item_description', 'description', $item_id); return new self($row); } }
しかし、サービスコードの中には、例えば以下のような処理もありました。
<?php class ToBeFixed { public function foo() { $raw_data = DB::execute('SELECT id, name, description FROM item WHERE created < ?', Date::Today()); // データを直接データベースから取得してから、それをオブジェクト化する $item = new Item($raw_data); $item_description = $item->getDescription(); (略...) } }
このような場合は、期待していた動作と変わってしまうため、修正しなければなりません。
もちろん修正方法としてはなるべくmodelを使った処理にするのが望ましく、 Item::get() するように改修しました。
上記はあくまで擬似コードですが、実際のコードに対してこの状況が一概に記述が乱立しているとは言えません。
それぞれのコードが作られた時期や経緯等があったのだと思います。
また上記のような修正するべきコードの中にはデッドコードも含まれており、影響範囲を確認した上で削除も行いました。今回のような使用頻度の高いテーブルやクラスの変更に対して、不要なコードをとりあえずそれっぽく直しておく事はコストでもあり将来のリスクでもあります。
このような修正・削除のアプローチは作業上必要であり、またそれをする意義があるというのが以前もお伝えした私の見解です。
参照箇所の洗い出し
この参照切り替えは、どの程度の精度で行えばゴールになるでしょうか?
もちろん、模範解答は100%なのですが、もし100%でなかった時のリスクと影響範囲がその判断ポイントとなります。
切り替えが完了しているとは、つまり 旧テーブルのカラムを参照していることがない ことです。
旧テーブルのカラムを安全に消去し問題があれば復旧する、ことができれば良いと言えます。
ここで、以前のブログでもお伝えした、 ALTER文でRENAMEし様子を見る という手法が考えられますが、今回は残念ながらこの手法は使えませんでした。
理由は商品テーブルの規模であり、とてつもない容量のテーブルで、
稼働中のサービスに対して ALTER実行-> 問題あれば再ALTERでRevert は現実的に不可能です。
移行手順4完了後の、本番環境の作業イメージを先に述べます。
5 . 1つのSlaveを本番サービス環境から切り離し(Service Out)
6 . 切り離したSlaveで UPDATE item SET description="" // 全行を一括更新 を実行
7 . データベースを再構築することでdiskのデフラグが行われ、この段階まで来てはじめて削減した容量が反映される
8 . Slaveとして本番サービスに再投入
9 . Masterに昇格
上記のように、本番環境のテーブルを操作することは容易ではありません。
また、この事からも手順3の段階で、参照切り替えを作業を完了させておく、後戻りの効かない作業になります。
このために以下のような複数の策を用いました。
- CI環境でのみ旧テーブルを変更する
- QA環境で、旧テーブルのカラムを一次的にRENAMEする
CI環境での対応
メルカリのテーブル定義は、リポジトリ内のdb-schemaファイルにsnapshot形式で管理されています。
CI環境ではこのdb-schemaファイルから都度テスト用のデータベースにテーブルを作成します。
このため、ブランチ上でdb-schemaファイルを変更することによって本番と異なるテーブルを構築できます。
今回はdb-schema上から 旧商品テーブルのdescriptionカラムの行を消すことによって、
CI環境上でdescriptionが存在しない商品テーブルを作成し、そこで落ちるテスト(によって動くサービスのコード)を修正対象として改修していきました。
QA環境での対応
CIがパスするようになって達成したことは、 テストが通る範囲で旧テーブルへの参照がない ことのみです。
当然ながらテストのカバレッジは100%ではなかったため、テストで通らない範囲の確認が必要です。
幸いサービスリリース前に行うQAテストの環境の旧商品テーブルは、本番環境に比べればレコード数は多くなかったためALTERが操作可能でした。ここで旧商品テーブルのdescriptionをRENAMEし、各施策のQA作業という幅広く網羅される環境で問題が起きないことを確認しました。
手順4、最終工程
とうとう旧箇所への書き込みを止める段階です。
手順2の最後にも確認した新旧テーブルの同期チェックを念のため再度実行し
- 書き込みは完全に両方に書けていること
- 読み込みは完全に新を参照していること
を再度確認したうえで、旧への書き込み処理を止めました。
この手順自体は何も難しいことはありません。
前述の擬似コードで表現すると、数行の差分です。
<?php // 内部的に2つのテーブル(item, item_description)にinsertする public static function create($param) { + $item_param = $param; + $item_param['description'] = ""; // 旧への書き込みを止める + $description_param = [ 'id' => $param['id'], 'description' => $param['description'] ]; - DB::insert('item', $param); + DB::insert('item', $item_param); DB::insert('item_description', $description_param); }
まとめ
手順4完了後、5-9も無事に完了し、めでたくdisk容量は削減されました。これにて移行完了です。
今回の対応は
- アプリケーションのインターフェースを変えない
- 多様な記述があるサービスコード
- できる操作が限定される本番環境仕様
など大規模サービス特有であり、醍醐味とも言える一連の作業でした。
このような大規模作業はもちろん私一人で行った訳ではなく
- 手順3の作業中、サービスのコードを広く漁るという特性上、関係する様々なエンジニアへのコードレビュー
- QA/SET チームによる旧テーブルが、参照されているところのあぶり出し及び参照されていないことの動作確認
など、多大なるご協力をいただき、メルカリのValueの一つである All for One を感じる案件でもありました。
メルカリではこのような大規模のサービスでの改善に興味のあるエンジニアを募集しています。
是非下記リンクからのご応募をお待ちしています。
予告&お知らせ
また、来月頭からは メルカリエンジニアによるアドベントカレンダーも開催されます。
こちらもお楽しみに!




