Hi, I’m Yusuke Shibui, a member of the Image Search and Edge AI team in Mercari Japan. I publicized design patterns for implementing a machine learning model into a production environment. The patterns are available in GitHub as OSS, and I welcome you to take a look if you are interested!
The repository is open for anybody to raise a PR or issue. If you have your own machine learning system pattern, please feel free to share your ideas with us!
-
GitHub Pages: https://mercari.github.io/ml-system-design-pattern/
Why do we need design patterns for machine learning systems?
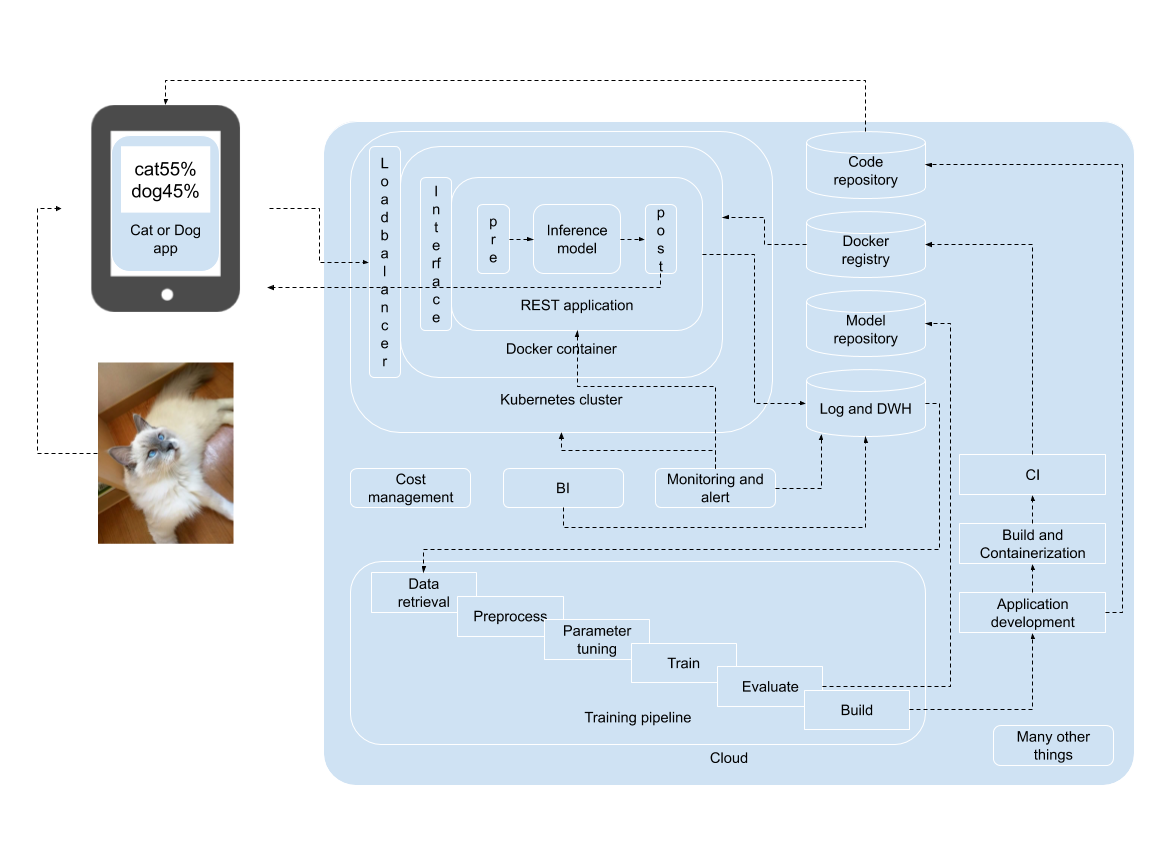
For machine learning models to demonstrate their true value, they must be implemented and used in a production service or internal system. In order to do so, we design a workflow and operation for machine learning as well as related systems to develop an integrated system, but this also uses skills other than machine learning. For instance, while data retrieval, preprocessing, inference, postprocessing, and training pipeline are used from a machine learning perspective, we also need UI/UX design, backend engineering, quality assurance, monitoring and alerts from a software engineering and DevOps perspective.
Even if a machine learning engineer or researcher takes great effort to develop a model to achieve the highest accuracy on the ImageNet dataset, they probably cannot acquire software engineering skills. Some of them may not need those skills in their career. On the other hand, software engineers, including application developers, backend engineers and SREs, might not be familiar with machine learning. Those having both machine learning and software engineering skills or experience are rare.

The machine learning design patterns aim to fill in the gaps between machine learning engineers and software engineers to integrate the machine learning lifecycle and software engineering manners. One of the goals of developing a system with machine learning is to make a business impact with the model in production. This requires understanding of machine learning specific technologies and implementing them into a business system in an operable structure. The aim of the machine learning design patterns is to organize patterns of practices for “making a machine learning model and workflow into a production system”.
There is a famous diagram in a paper, “Hidden Technical Debt in Machine Learning Systems”, that depicts components required to run a core machine learning model. The core is located in the center as a small black square, and is surrounded by various systems.

The paper emphasizes that in order to use machine learning effectively in production, we need to develop and operate non-machine learning components. It does not say machine learning is unimportant, but to make machine learning productive in a system, we need many other resources. We have to implement machine learning logic into a web service or system in order to make our business succeed with machine learning. Note that all the systems require business evaluation and system operation. For a plain system, we certainly utilize an infrastructure and resource management, and may optionally use monitoring, alerts and backups. For a machine learning system, we need a prediction server as well as an interface and connection to it. In addition, we can have rather advanced DevOps with a data logging, analytics, visualization, and training pipeline. We do not need to make all of them at once, but to make a machine learning model into our production system, we have to design and develop resource utilization with consideration of cost effectiveness and related systems.
Structure of the machine learning design patterns
I wrote the patterns in the following categories:
-
Training patterns: ways to design a training pipeline
-
QA patterns: test and quality assurance
-
Serving patterns: designs to develop a model into a prediction system
-
Operation patterns: model and system operations
-
Lifecycle patterns: compositions of other patterns
Each category consists of explanations to realize a machine learning lifecycle, from training, QA, and serving to operation, in a production system. The lifecycle pattern is aimed to design an overall system integrating training, QA, serving and operation.
Each pattern includes:
-
Use case: when to use the pattern
-
Architecture: what issue the pattern is trying to solve and how the system is structured
-
Diagram: overview of the system
-
Pros: advantages of the pattern
-
Cons: disadvantages of the pattern
-
Consideration: things to watch out for when using the pattern
I also wrote some anti-patterns to explain what should not be made.
What I want the patterns to become
I tried to make the initial format of the design patterns not be so dependent on a certain platform, language or library. They are written to be able to be deployed on major cloud services and Kubernetes clusters. Choosing which cloud or Kubernetes cluster to use depends on each company’s or system’s scheme, and I made the pattern quite abstract so that they are applicable to as many systems as possible.
I joined Mercari JP in July 2018, as a MLOps engineer, formerly SysML engineer, and had chances to develop and operate various machine learning systems. I guess I have taken part, in some ways, in most of the machine learning systems running in production. Some projects I worked on from their initial stage, some for model development, and some after release. There are some that I joined from production troubleshooting :)>. This machine learning design pattern documentation is the result of my experience with those projects. Since Mercari is a web service based business and uses cloud and Kubernetes, I assume the patterns might be biased to those conditions. I would like to enhance the patterns to compose in major cloud services, such as AWS, GCP and Microsoft Azure, and make workflows based on KubeFlow, to achieve more general and practical patterns and have more fun with machine learning!



